Discussion topic for EIP-7830.
Update Log
- 2024-11-29: initial draft Add EIP: Contract size limit increase for EOF by axic · Pull Request #9074 · ethereum/EIPs · GitHub
External Reviews
None as of 2024-11-29.
Outstanding Issues
None as of 2024-11-29.
Discussion topic for EIP-7830.
None as of 2024-11-29.
None as of 2024-11-29.
Prior relevant discussion topics:
Spreadsheet calculating costs to deploy.
summary:
24KiB today - ~ 5.4MGas
64KiB under EIP-7623 - ~ 15.8M gas
Largest contract in 30MB - ~ 121.9 KiB
Largest contract in 36MB - ~ 146.9 KiB
JUMPDEST-analysis is required for legacy contracts, and many of the algorithms performing it are not linear and/or have unknown unknowns
I have seen this claim that JUMPDEST analysis is non-linear but can someone explain why it would be?
The code below appears to implement this and it is linear.
From a strict algorithm analysis perspective it is O(n), but there are in essence multiple linear aspects with different “constants” that the interaction varies so much based on the content it appears non-linear because we are magnifying one of the linear cases to a level not seen in typical organic use.
Typical contracts are full of non-jumpdest/non-push targets. The best attack contracts were exclusively jumpdest, exclusively push, or a deep mix of both jumpdest and push of various sizes. There was not a single algorithm that didn’t exhibit a large computational cost jump between all jumps and all jumpdests (algos boil down to you either mark safe or unsafe jumps, and the cost was in the marking). So a good attack vector was all jumpdest/push1 where the immediate is jumpdest. This particular algorithm cited is weak against the all jumpdest case, but excels in the all push(jumpdest) case.
Since we now charge a nominal gas per-32-bytes for CREATE[2] now this scenario puts the worst attack scenario for each client in line with the GPS (gas per second) of other operations, and is no longer a better denial-of-service vector than “SHA3 lots of data,” which has been one point to anchor GPS against. Without that cost executing CREATEs in a tight loop with a good attack contract significantly degrades GPS to an unacceptable level.
Thanks, I think I understand the situation now. I think a summary could be useful for others:
I haven’t caught up on all the discussion but something about this seems really off to me. We’re talking about the costs incurred by execution clients, right? And the concern is that a linear pass through all contract code (to compute a pc to instruction map) before message calling a contract – a map whose computation can be cached by the way – is too expensive? This is surprising to me, so I want to check it before getting more into the details of performance trade-offs strictly below the regime of “a linear pass is ok”.
It’s also about when the pass occurs. For EOF it occurs at contract creation, and at no other time, and all metadata needed for execution is encoded in the container.
For legacy the jumpdests are metadata derived from the code, a list of which jumpdests are valid and which are not. Clients need do generate this meatata prior to execution. Naïve implementations will check as part of the CALL, most clients cache once calculated. Clients could persist this cache but I am not aware of any that do. Initcode is particularly tricky because there is a very high likelyhood it will never be executed again.
So while the cost is linear with size the attack modes are impactful. Clients would need to commit to disk caching jumpdest analysis to remain on the safe side.
So clients can easily handle non-EOF here by doing that caching as you said. I think this removes the argument here that EOF is needed for increasing the code size limit.
My impression so far although I’m not entirely up to date is that almost every pro-EOF argument I see has some similarly weak justification. I am concerned about having to implement EOF (I’m maintaining a formal EVM spec) when there isn’t actually a good reason for it.
One thing to note is that clients caching the jumptables is something the protocol does not require, whereas EOF validation is something the protocol requires.
Which EVM spec are you maintaining? You will need to add a new section about container validation, but the remainder of the changes are mostly tweaks on existing opcodes to support the design goals of things such as removing dynamic jumps, making stronger guarantees about the operand stack, removing code introspection and removing gas introspection.
The attacks use CREATE, the bytecode can be generated on the fly, there is no caching that can be done, at best heuristics. The chain needs to protect against worst case scenario so the parameters (size limit) are tuned for that. I don’t see how caching mitigates that attack.
As far as I can tell, pricing JUMPDEST analysis on CREATE more accurately is the only real mitigation.
Verifereum, a formal EVM spec in higher-order logic.
Since we can’t actually get rid of legacy code, the spec (and all the clients for that matter) needs to implement all the things EOF is removing anyway, and then additionally implement all the EOF checks etc. It just doesn’t improve things as far as I can tell the way it would if we were actually making breaking changes. But a blockchain is not a good place to make breaking changes - better to build better tooling around the existing EVM in my opinion.
OK this might be true (I haven’t independently analysed whether this attack is a serious threat, but I am happy to assume it is for now), in which case I would support repricing as the way to address it.
I’m not sure I understand this. It’s still just a single pass to compute the locations of all the jumpdests in a contract, no?
Are these results actually recorded anywhere? The algorithm looks single pass. Just iterate over all the bytes in the bytecode, skip PUSH opcodes and mark jumpdests.
If the question is how big of an array you need to store all the jumpdests, this is just a matter of pricing. And it seems that it’s already paid for by the initcode cost of 2 gas per 32 bytes anyways. (If the argument is that this cost is too low, maybe with some execution resource usage numbers, we could raise it to 3 gas per 32 bytes or something).
If there was an algorithm where the cost was independent of the code bieng analyzed, does this change anything?
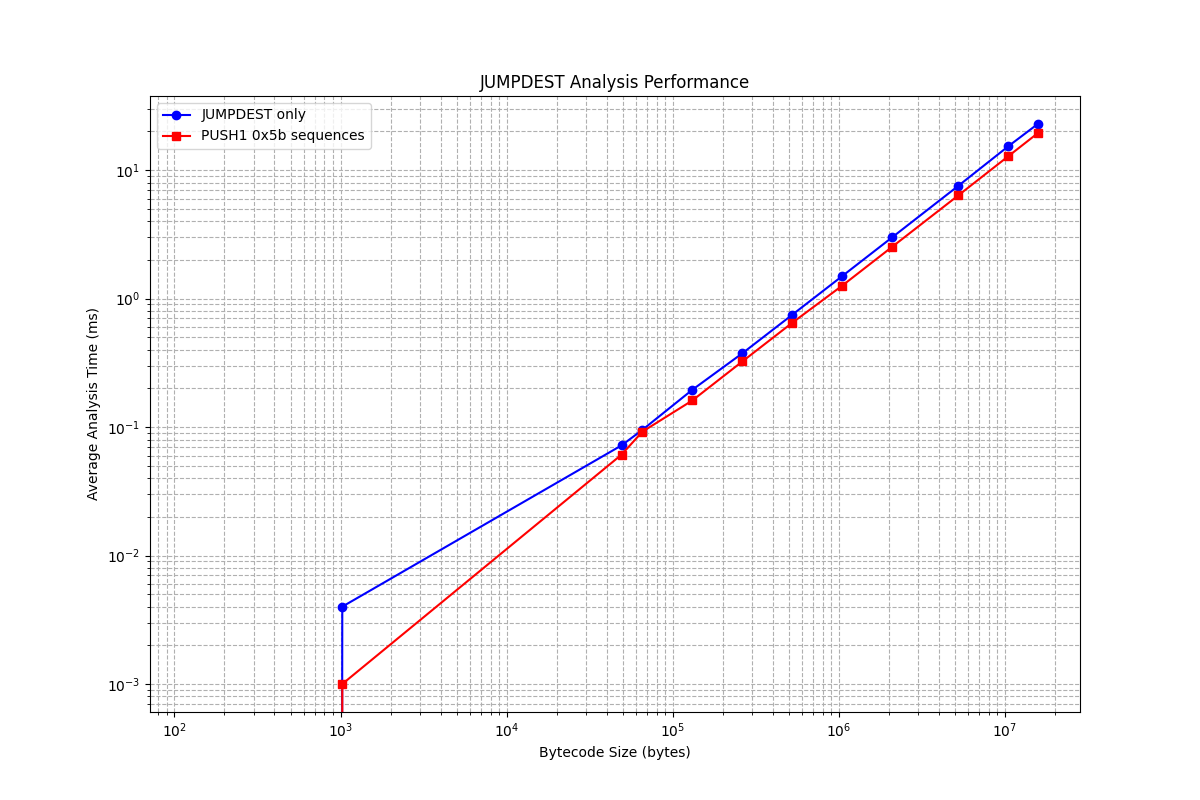
I’ve performed benchmarks of JUMPDEST analysis. The results are fairly similar for both PUSH1-heavy and JUMPDEST-heavy bytecodes. The benchmarks show a strong linear correlation between analysis time and bytecode size.
The max cost is ~46.5ns per word (on a 5-year old laptop), which is arguably a bit high (and like I said, could be addressed by the gas schedule), but I didn’t spend any time optimizing the code, I just wanted to demonstrate linearity.
Draft EIP to simply remove the jumpdest analysis
Where’s the discussion top in “remove jumpdest analysis?” Several of my Ipsilon teammates think it would be dangerous and reckless, but I don’t want to derail this EIP’s discussion.