Some ideas for improving how the EVM charges gas for memory, and how much gas child call frames are allowed to access. The key goals are to simplify the rules, make it more clear what the invariants are, and to increase the amount of memory available to legitimate applications.
See post here (uses some latex so can’t post here directly):
I generally support this - what we have is a mess and this is much, much better.
My basic concern is that if I understand you, “it doesn’t actually cost any resources to use memory” isn’t entirely true. As I said on the Discord:
… RAM is addressed in pages, and CPU cache in lines, and writing to an address touches only that line and page, not the intervening ones. How expensive that is depends on lots of things that we probably should consider more than we have – see What Every Programmer Should Know About Memory
So indeed the size of the address range doesn’t matter, or even the total amount of memory used. To a first approximation it’s the size of the working set vs. the amount of room left in the CPU caches for EVM memory that matters. If the working set is too large CPU caches will spill to RAM and memory access gets much slower.
Since each CALL requires spinning up a new VM instance and loading the code of the called contract it seems that caches may be spilling then anyway, so limiting memory use per VM as well as in total makes sense to me. But I don’t have numbers for how large the working set of EVM instances tends to be or how much is used by the rest of the client. Given the numbers, I suspect a good formula might go quadratic per VM in the call stack to keep each VM from using too much cache, but accumulate across VMs.
Interesting… so it might make sense to add an extra layer of quadratic pricing per VM to account for large memory leading to memory being stored in less efficient caches? Though if that’s true, then the true optimum might be to make the cost of MLOAD and MSTORE (and copying) depend on the log of the memory size?
I do think that things like that could be added on top of the framework, though there’s the tradeoff of whether or not it’s worth it to fine-tune and accept the cost of increased complexity that comes as a result.
I support the change because memory cost management (as mentioned in the post it is rather inconsistent).
I have few points to mention from the post and the discussion. I agree with @gcolvin on the limit of memory use per VM and making the cost quadratic because it serves the purpose of increasing the available amount of memory for legitimate applications and “punishing” the malicious applications that would require larger memory. I might be wrong, but up to my understanding, since the idea of quadratic cost is also used in the current version, there might be another concern about the number of VMs to be initiated (call-frame in the current version). Would we go back to another 63/64 rule? So, we might have the same problems again.
On the point of fine-tuning, I think that all the proposals are going towards that direction because fine-tuning will allow us to reach an essential design goal: clear formula for memory pricing. So, defining new costs for MLOAD and MSTORE is a step towards that direction. I agree with linking the cost to the memory size, but I think that the function to use depends on many factors like @gcolvin mentioned. I might be wrong again, but I am not sure if MLOAD and MSTORE should be handled the same way in the first place.
The big hit is that RAM is a full order of magnitude slower that cache. An interesting experiment would be a program that loops, reading and writing randomly within a buffer. As the size of the buffer increases I’d expect the throughput to plummet when the I/O starts overflowing cache. I think we want a cost function that discourages contracts from falling off the cliff.
Thus the quadratic cost function. I’ll need to do some measurement to see if that’s the right function.
Most programs don’t write randomly though, in part because this has bad performance like shown in the graph. Most common access patterns are 1) stack-like, where access clusters around recent additions, before being removed again. (I suspect EVM mem usage is primarily like this), and 2) linear scans, where array data is repeatedly accessed in order. CPU Caches are really good at handling those loads. LRU eviction policies handles the former, speculative prefetching the second.
The exceptions to these patterns are datastructures like trees and hash tables, and algorithms like sorting, matrix multiplication and FFTs. For these there is a lot of research to make them more cache-friendly. This is the main motivation behind B-trees and cache-aware and cache-oblivious algorithms.
I’m bringing this up because the literature of cache-aware/oblivious algorithms has already addresses the problem of modeling the real cost of memory access with the cache-aware memory model and the cache-oblivious model respectively.
The difference between the two is roughly whether the algorithm knows how the caches work and can adjust its behaviour, or is oblivious to it. For example, if you are using files or network storage, the algorithm is aware. For Ram and CPU caches this does not apply. In fact, the exact details of caches vary wildly between processors (much like how EVM runs on a variety of hardware) and the only strategy is to create algorithms that work great on any cache hierarchy. So for present discussion the relevant literature is the cache-oblivious one.
The cache-oblivious cost model is approximately as follows:
The cache contains words of size B
It stores at least B such words
When a new entry is inserted (after a cache miss), the oldest* one is removed.
The complexity measure is the number of cache-misses/insertions.
*: The actual model uses a theoretical optimal cache that can perfectly predict future access, but it turns out just evicting the oldest one is a real good approximation.
I also want mention that modern (as in last 5 years) CPU caches are several megabytes in size on L3. It is very unlikely that EVM transactions will exceed this.
There is also a sizable cost associated to accurately accounting for memory usage. The EVM implementation needs to check the memory bound for each MLOAD/MSTORE and conditionally check gas, maybe allocate more memory, etc. For values that are in cache (i.e. nearly all) this is likely more expensive than the memory operation itself.
We could also allocate each call-frame a fixed amount like 1MB and do away with all that. 1MB is a generous amount: even if you could allocates more, you would not have any gas left to do anything useful with it. With 1MB and a ~1024 call-depth limit, the EVM needs at most 1GB. This sounds like a lot, but memory doesn’t cost anything unless it is accessed and there is not enough gas to access the most of it.
I’d also love to see an chain-history analysis of the max memory size distribution for all historical call-frames.
I think that the limit should take into consideration also the number of call-frames that can be initiated. In order to have a good analysis to define limits and cost functions, we need historical data of memory usage of different contracts including possible DoS ones. Nowadays, L3 cache are around 8MB. It should be enough for the majority of the cases, but we are not sure if there was some case in the past that required more.
In general, we all agree on fine-tuning the cost of MLOAD and MSTORE.
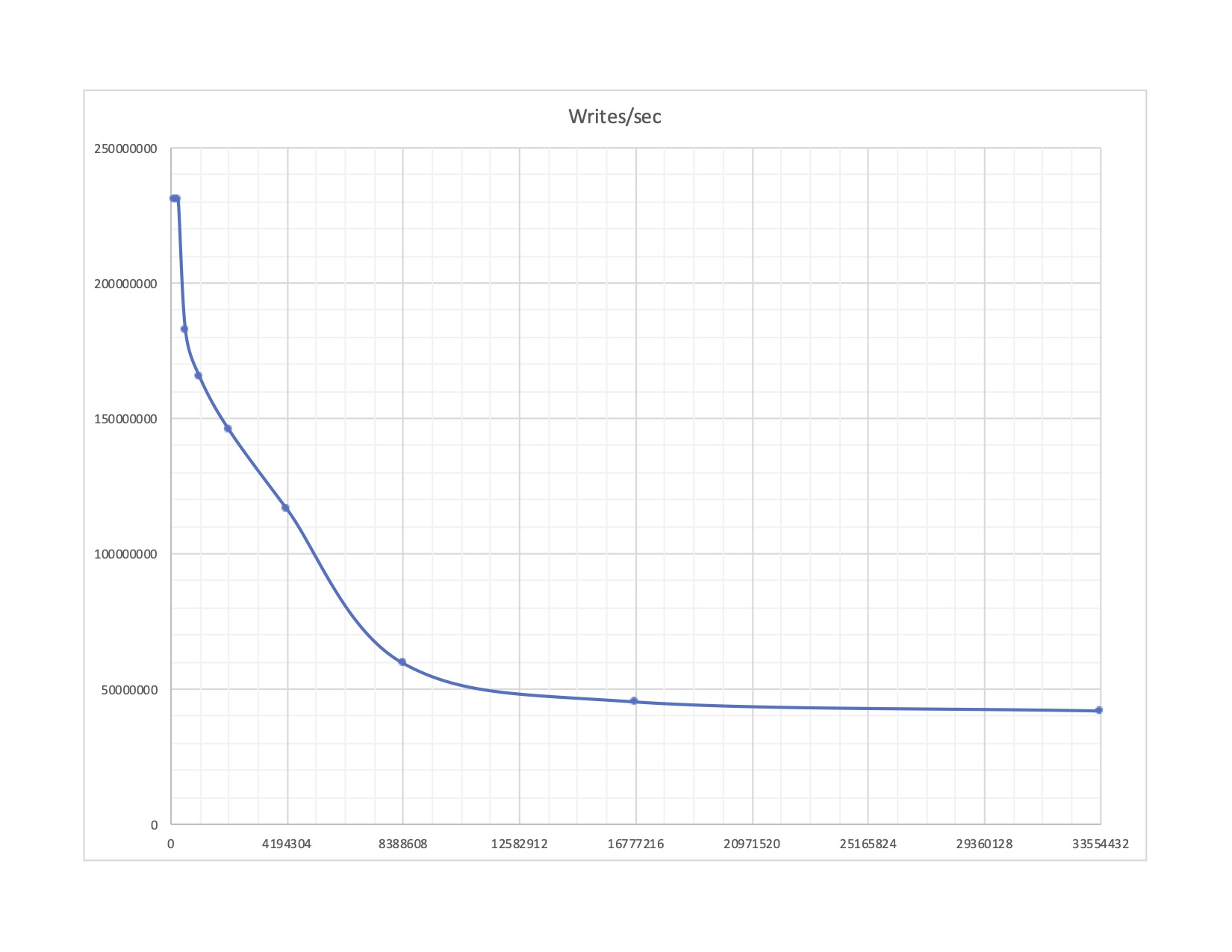
What we see in this worst-case experiment doesn’t fit a quadratic increase in memory cost. Rather, performance does an approximately exponential decay from 230M to 42M writes-per-second at 16Mbytes. (Different system will of course give different results.)
At that 6:1 ratio, a cost formula of 3 + floor(log(MSIZE)) might fit pretty well, starting at 3 gas and rising to 16 gas at 32 megabytes. However, that spread also seems small enough to just choose a flat fee somewhere in that range – I’d guess about 6.
This is my intuition too. Especially once you take into account EVM overhead, it doesn’t feel like the cost of an MLOAD with large memory vs small memory is that large. So we should try to make sure that a plain 3 gas per memory op isn’t fine enough as it is.
I’ll note that the push opcodes are at 3, and they are nearly a best case, with sequential access to adjacent words on the stack. So unless interpreter overhead dominates I’d expect random access to memory (the DoS surface) to require a bit more. I need to get set up to measure it.
There is a problem with the proposal 1 is that increasing the stack depth past 1024 may bring new DoS vulnerabilities to some Ethereum client implementations. Proposal 1 sets a new maximum depth of 29296.
There are two known methods to manage commit/rollback of world state changes: 1) track only new key/values (also called state cache) or 2) track changed values (old and new) (also called state journal or state log). In a VM with N nested calls, there are N active caches but only one active journal.
In a cache, every time a cache is committed (a CALL is successful), the contents of the cache at level N are copied into the cache at level (N-1). When a SLOAD operation occurs, the cache at level N is queried and if the key is not there, then the cache at level N-1 is queried and so on recursively until level 0 (the trie) is reached. Let’s assume that a certain key is warm at level 1 (meaning it has already been fetched from the trie). At stack level 29000, a SLOAD gas cost would need to be k*29000 for k approximately equal to 10 (290k gas). But the cost of a warm SLOAD is currently 100. This high difference (100 vs 292k gas) introduces a new DoS attack vector on those clients.
Geth doesn’t use a state cache, but a journal. It won’t be vulnerable.
However BESU uses the cache model, and I think it will.
A call frame gets a max_memory parameter; memory expansion beyond that value is forbidden. The outermost call frame gets max_memory = block.gaslimit * GAS_PER_MEMORY_BYTE
OK I did not realize this. For some reason I had thought that the cache model was a temporary measure back in 2016 because it’s easier to implement, but everyone had moved to a journal since then.
What’s the justification for any VM implementation using the cache model?
If we want to continue being friendly to the cache model, the perhaps we would need to stick to the 63/64 model (and perhaps even make the max fraction lower).
Reading back over this I’m inclined to just say that the cache model is not appropriate, but I don’t know if there are reasons that Besu or other clients can’t use a state log.
@vbuterin Do you still want to move this proposal forward? It would be a huge simplification of the existing rules. With EOF coming in Prague this would be a good time to do it.