So I did more careful testing, adjusting for the time spent generating random numbers to write and random positions to write to. The difference between random and sequential access became much less, and the effect of buffer size almost disappeared. My take is that 30MB of memory isn’t enough to cause a modern Core I7 with a 12MB L3 cache to thrash.
I would love to see it happen!
There is also a sizable cost associated to accurately accounting for memory usage. The EVM implementation needs to check the memory bound for each MLOAD/MSTORE and conditionally check gas, maybe allocate more memory, etc. For values that are in cache (i.e. nearly all) this is likely more expensive than the memory operation itself.
I suspect that even if the value is not in the cache, the accounting around memory is more expensive than the read or write itself. This is somewhat anecdotal but while working on a faster memory implementation for py-evm (titanoboa/boa/vm/fast_mem.py at b8a0f2ad549b7a905aec28e6772198c9ba07d9fb · vyperlang/titanoboa · GitHub) I found that most (something like 70-90%) of time involving the memory access itself was in the expansion check and converting between bytes and ints from the stack. I was able to remove this overhead in the common case where reads or writes are aligned by modeling memory as an array of words alongside the bytearrays and writing between them when bytes were needed instead of ints. Actually this suggests to me that we should charge more for unaligned accesses and less for unaligned accesses, Python isn’t super efficient though so I don’t know how that works on other clients.
With 1MB and a ~1024 call-depth limit, the EVM needs at most 1GB. This sounds like a lot, but memory doesn’t cost anything unless it is accessed and there is not enough gas to access the most of it.
Hmm I am not so sure about this, you have to allocate the memory which is expensive. You can either allocate it up-front or on-demand. I didn’t really see this cost addressed in the proposal but maybe I missed it.
you have to allocate the memory which is expensive.
Is it? On my Mac I can malloc() terabytes of memory in very little time. And I can write to it randomly in not much time until I write enough to start using a lot of physical pages. But as you say, the interpreter overhead and accounting dominate the cost of the writes themselves long before memory access starts to thrash noticeably.
I don’t think the issue is the amount of memory allocated but overhead per-call to malloc() (which memory resizes presumably trigger). At least, that is my understanding from talking to some client devs, that one of the more expensive aspects of issuing a CALL is allocating the memory frame.
For reference, here is a short benchmarking c++ script where I benchmark each 30MB allocation (including zeroing memory) costs 45ms(!), 32ms of which is spent in syscall land sorry, I made a mistake with the allocation size in my original post, it costs 1.1ms, 25us of which is in syscall land:
~ $ g++ --version
g++ (Ubuntu 11.3.0-1ubuntu1~22.04.1) 11.3.0
Copyright (C) 2021 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
~ $ cat test_malloc.cpp
#include <vector>
int main() {
for (int i = 0; i < 1000; i++) {
// EDITED: was originally std::vector<int>
std::vector<char> v(30*1000*1000, 0);
}
}
~ $ g++ -O2 test_malloc.cpp
~ $ time ./a.out
real 0m1.155s
user 0m1.130s
sys 0m0.025s
(I originally used malloc directly but it seemed gcc kept optimizing those out).
I also tested some variants and it seems for small enough sizes the allocator might be able to use a pool, but I didn’t investigate further.
Interesting, thanks There are a lot of variables. My tests used malloc(), and enough volatile declarations to keep the compiler from not calling it, or from writing to or reading from the allocated memory. Clients and their development languages will use different strategies for lazy or greedy allocation of memory, which are going to affect the cost of a CALL. Overall I think we undercharge.
Dug up some prior benchmarching that indicates that interpreter overhead runs about 1 gas. Even on a very slow CPU it takes 10ns to burn a unit of gas. On recent CPUs it takes less than a nanosecond to get a cached value to a register. One gas can pay for a lot of overhead.
So how badly could an attacker abuse the increasing cost of widely spread random access? Worst case, for this data, writing words randomly to fill 32Mb costs about 4 to 5 times more than filling 1Mb. (Sequential access is faster than random access, but not enough to change the results of this analysis.) So if the base cost for memory operations corresponds to randomly filling 1 mem of memory an attacker could could use a larger buffer to force an app to use about 4 times as much gas as paid for. However, there is also the memory expansion cost of 32 gas per word, which overwhelms the cost of access. Differences in these parameters are not going to matter much given the extension cost. So my former analysis holds – we can pick a cost for memory access that is independent of pattern of access. The 3 gas we have now likely suffices – 1 gas for the interpreter, 2 gas for the block copy of the data…
It’s also worth noting that the memory extension cost is not about the cost of allocating memory – on modern systems that’s almost free until memory is touched. It’s about limiting the amount of address space a client can possibly use. That matters because if the working set of a system – the total amount of address space used by a client – is larger that the available CPU cache, and worse, available RAM, (after the OS and other programs get their share,) then cache lines will spill to RAM and the system will start to thrash. With modern CPUs caching megabytes of data, held in gigabytes of RAM, 30Mb seems quite reasonable. Note that 30Mb of gas costs $1200 right now, and historically that is very low. So exploits involving extending memory would be expensive.
New memory needs to be zeroed before use though, which is not free. The benchmark I posted above suggests 1ns per 32 bytes. If 1 gas is supposed to reflect 10ns of CPU time then that means 1ms of overheard would be 100k gas. If you do something smarter and only zero memory before first use, then you need to start tracking which parts of memory have been touched etc.
So maybe the best thing then (subject to further benchmarking ofc) is to simply charge a linear cost of 1 gas per ~10 words (that is, pricing it at 1 gas per 10ns) for memory expansion. And maybe the cost for accessing memory should reflect the worst case cost of hitting RAM, which IIRC is about 70ns, so 7 gas (could be off here though since the last time I checked latency numbers was like 7 some years ago).
(The 10ns was a truly ancient machine.) My measurements didn’t see any difference between a write and a blind read. And pages obtained via mmap() come zeroed “for free”. But I think the fees here weren’t chosen by actual cost, but to behave close to the current gas cost function. That’s why they overwhelm the actual memory access. Which I think is appropriate – memory access to (predictably) cached data is almost free, but if the system can be made to thrash because of a bloated working set it is a horrible attack vector. I think we may be overcharging for that purpose, but we would need to measure the memory use of systems running clients on the range of machines we want to support. How light can a light client go?
1 Like
And pages obtained via mmap() come zeroed “for free”.
Ah, I see. Well I guess there is a small overhead once you need to fault the page but I’m guessing it’s negligible for our purposes (worth checking though ofc). I’m wondering though how many language runtimes actually guarantee returning mmap’ed pages when you allocate memory?
Btw so we have the numbers on hand, I just ran the numbers for mmap and it looks like about 230ns per mmap / munmap. Which is small, but not entirely trivial:
~ $ cat test_mmap.cpp
#include <sys/mman.h>
#include <cstddef>
int main() {
for (int i = 0; i < 1000 * 1000; i++) {
void *p = mmap(NULL, 30 * 1000 * 1000, PROT_READ | PROT_WRITE, MAP_ANONYMOUS, -1, 0);
munmap(p, 30* 1000 * 1000);
}
}
~ $ g++ -Os test_mmap.cpp
~ $ time ./a.out
real 0m0.241s
user 0m0.053s
sys 0m0.188s
I’m coming to believe that I would just mmap() the whole 30Mb.
1 Like
Was just tinkering, and redid the script to actually test how expensive writing to the allocated memory would be, and looks quite expensive:
$ cat test_mmap.cpp
#include <sys/mman.h>
#include <cstddef>
#include <cstdio>
int main() {
for (int i = 0; i < 1000 * 1000; i++) {
char *p = (char *)mmap(
NULL,
30 * 1000 * 1000,
PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS,
-1,
0
);
*(p + i * 10) = 10;
munmap(p, 30* 1000 * 1000);
}
}
$ gcc -O3 test_mmap.cpp
$ time ./a.out
real 0m6.638s
user 0m0.363s
sys 0m6.188s
6us per loop
Just so we have the numbers, I additionally benchmarked the cost to malloc a 4KB page. It’s about 1.3us:
#include <vector>
#include <cstdlib>
#include <cstring>
#define COUNT (1000*1000)
int main() {
std::vector<void*> v;
v.reserve(COUNT);
for (int i = 0; i < COUNT; i++) {
void *p = calloc(1, 4096); // ensure allocated memory is zeroed
v.push_back(p);
}
}
$ g++ -O3 test_malloc.cpp
$ time ./a.out
real 0m1.387s
user 0m0.227s
sys 0m1.147s
I wanted to be careful and account for the case where the EVM implementation is a bit smarter about allocating memory and uses a free list, in order to minimize calls to malloc. In that case, we only need to benchmark memset. It costs ~250ns per page on my machine (as is hinted by the user number in the previous benchmark):
~ $ cat test_memset.cpp
#include <vector>
#include <cstdlib>
#include <cstring>
// 100k pages, or 400MB
#define COUNT (100 * 1000)
int main() {
char *p = (char *)malloc(4096 * COUNT);
// run memset 10mm times
for (int i = 0; i < 10 * 1000 * 1000; i++) {
memset(p + (4096 * (i % COUNT)), 0, 4096);
}
}
~ $ g++ -O3 test_memset.cpp
~ $ time ./a.out
real 0m2.694s
user 0m2.556s
sys 0m0.136s
I’m running all these numbers on the same machine as the previous benchmarks in this thread – the CPU is an i7-10710U. The Linux might be updated compared to before, it’s 6.8.0-55-generic.
This benchmark is incorrect. Compiler Explorer
What’s incorrect about it?
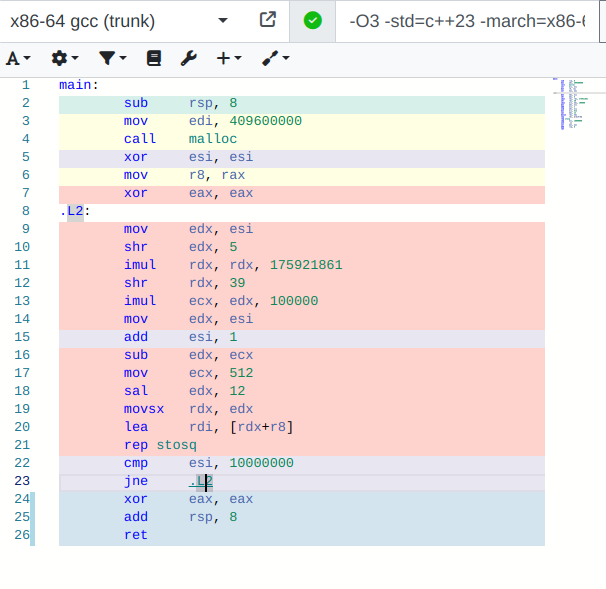
I forgot to mention by the way that I’m using gcc 13.3. But I just checked the output, and it doesn’t really make much difference (Compiler Explorer).
The compilers are significantly modifying your program. Either they completely remove both malloc and memset (clang), or they combine all memsets into single one and inline it as a single rep stosq instruction. This is because the loop count is constant. In other words, the is not even a single call to memset in this benchmark.
I said I used gcc for the benchmark. Not sure how clang is relevant here
That’s not what the assembly says. The assembly says that rep stosq (which zeroes memory) is executed in a loop. Even if you don’t believe my reading of the assembly, you can believe the CPU. The time to execute this program is linear in the loop bound, not in the size of memory allocated. For instance, if you increase the loop bound to 20mm, it takes twice as long to run.
Not sure why that’s relevant - it’s common for memset to be inlined and compiled using rep stosq (see for instance: What does the "rep stos" x86 assembly instruction sequence do? - Stack Overflow).
The point was to measure the CPU cost of zeroing memory, not literally measure the overhead of calling the memset builtin