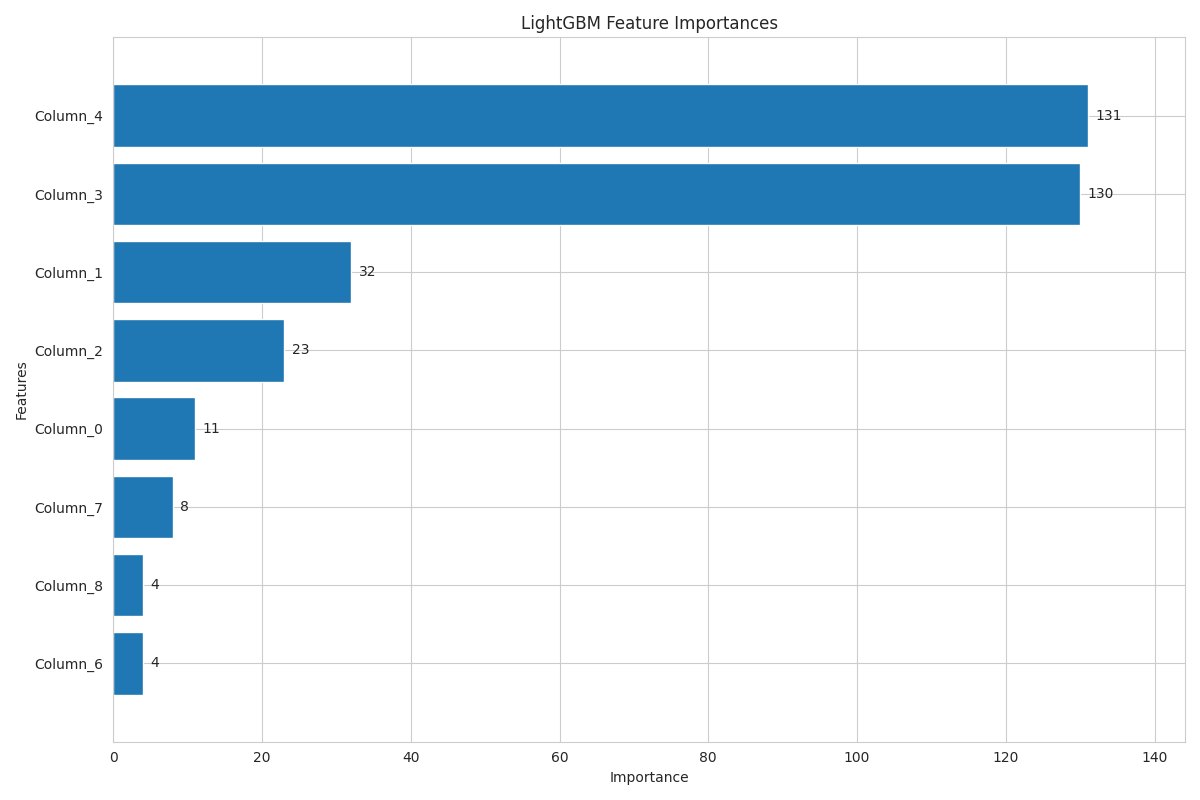
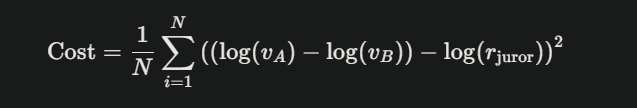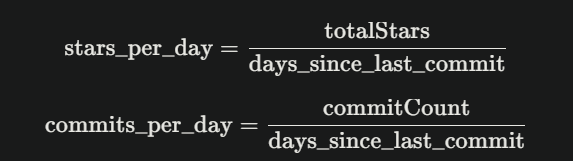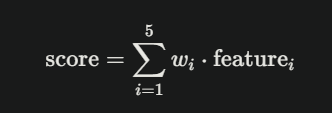═══════════════════════════════════════════════════════════════
Deep Funding L1: My Journey from 7.03 to 4.46 (Best: 6.46 Private)
Pond_Username: Ash
═══════════════════════════════════════════════════════════════
Final Results:
-
Public Leaderboard: Phase 3 scored 4.4460 (best)
-
Private Leaderboard: Phase 3 scored 6.4588 (BEST SUBMISSION!  )
)
-
Beat my Phase 2 (6.6637) by 3.2%, Phase 5 (6.7476) by 4.5%
Competition: Deep Funding L1 - Quantifying Ethereum Open Source Dependencies
Submission: submission_phase3_20251005_145132.csv
Code: Github
INTRODUCTION
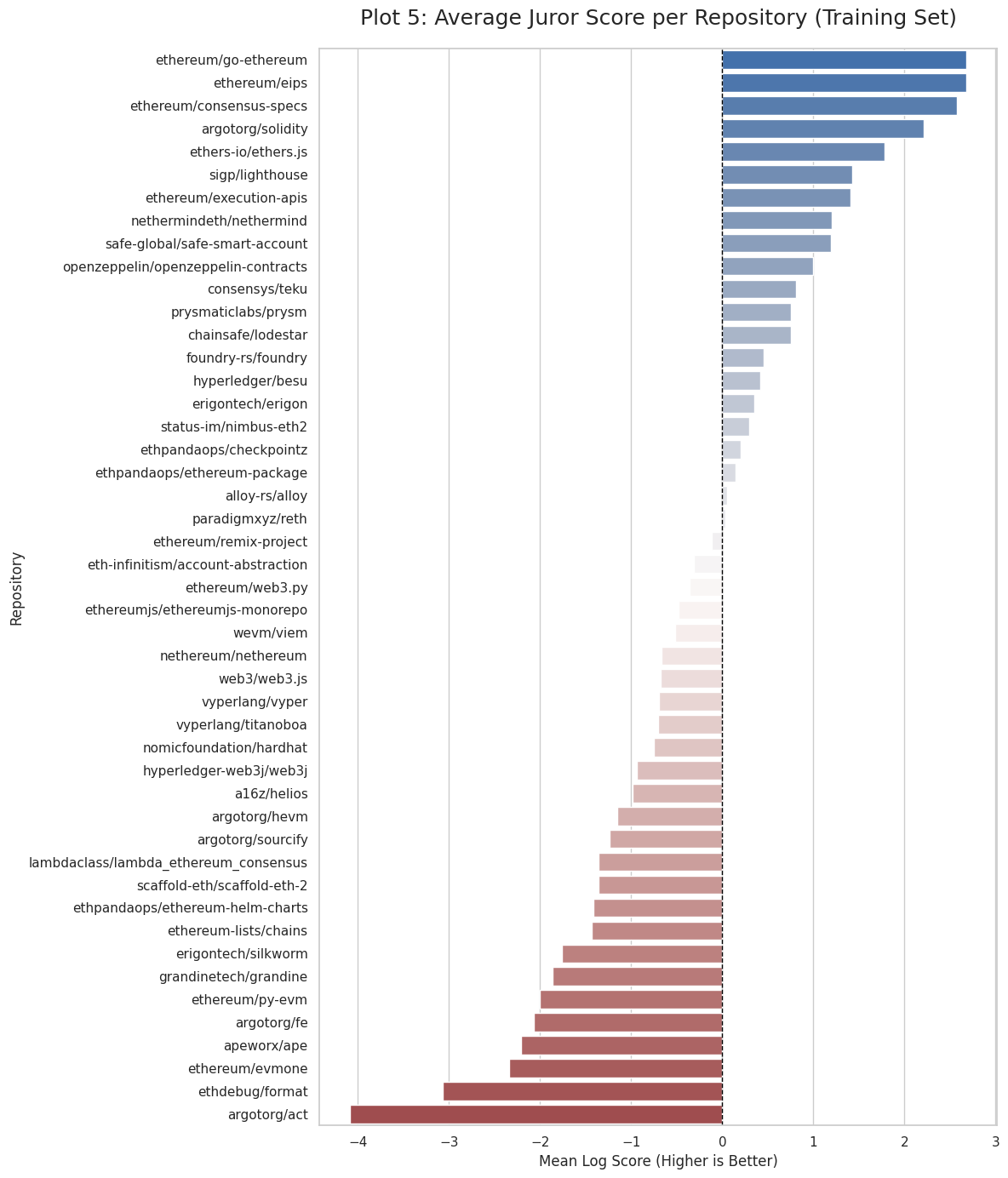
I spent many weeks building a model to predict how expert jurors would allocate funding across Ethereum’s dependency graph. My best approach was surprisingly simple: trust the training data, make tiny adjustments, and don’t overthink it.
Key results:
-
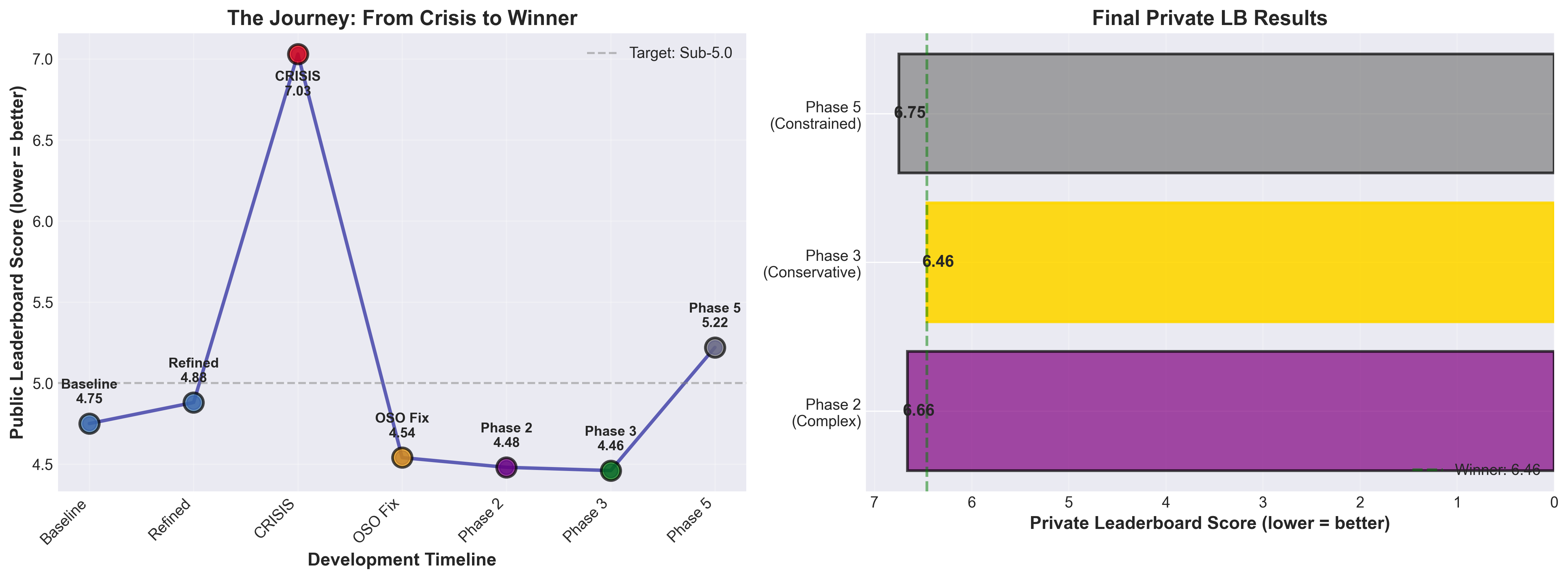
Started at 7.03 (disaster) → ended at 4.46 (public LB), 6.46 (private LB)
-
Phase 3 (conservative approach) beat Phase 2 (complex juror modeling) and Phase 5 (aggressive constraints)
-
On private data: Phase 3 (6.46) > Phase 2 (6.66) > Phase 5 (6.75)
-
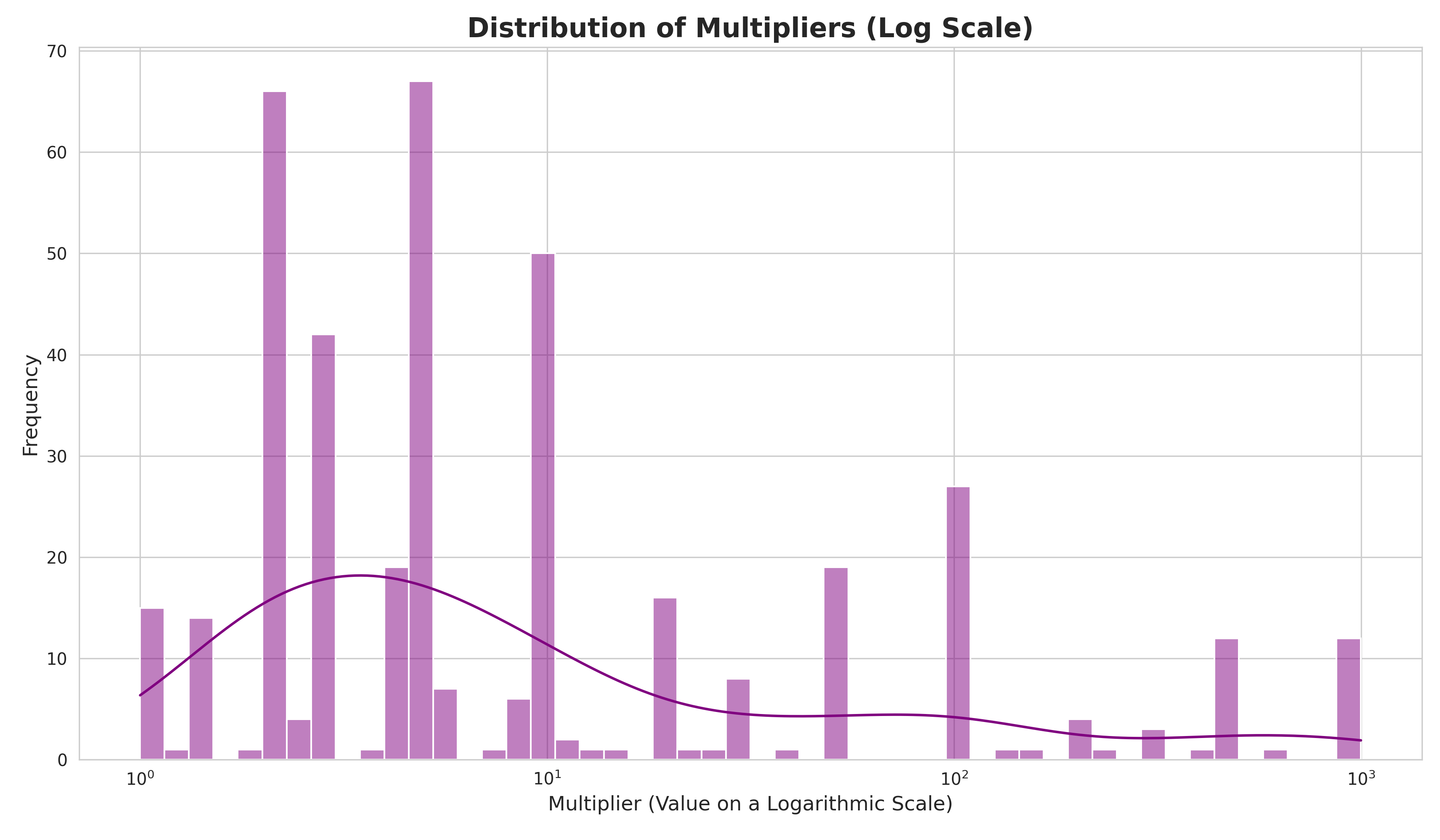
Main insight: 1.2× boosts work, 20× boosts fail spectacularly
Figure 1: My complete journey from baseline (4.75) through crisis (7.03) to best (6.46). Left: Public leaderboard evolution over time. Right: Final private leaderboard comparison showing Phase 3 (conservative) winning over Phase 2 (complex) and Phase 5 (constrained).
THE PROBLEM
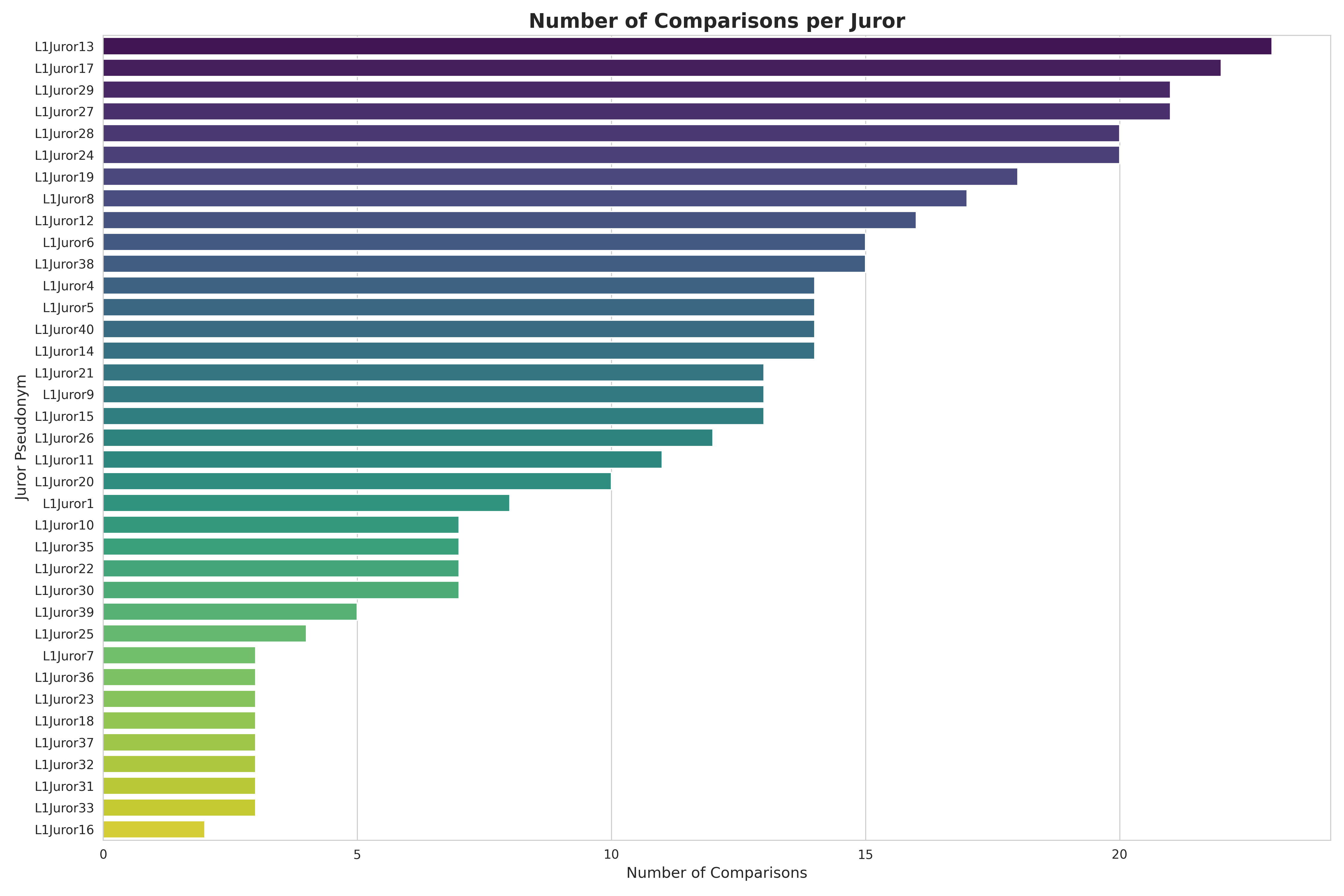
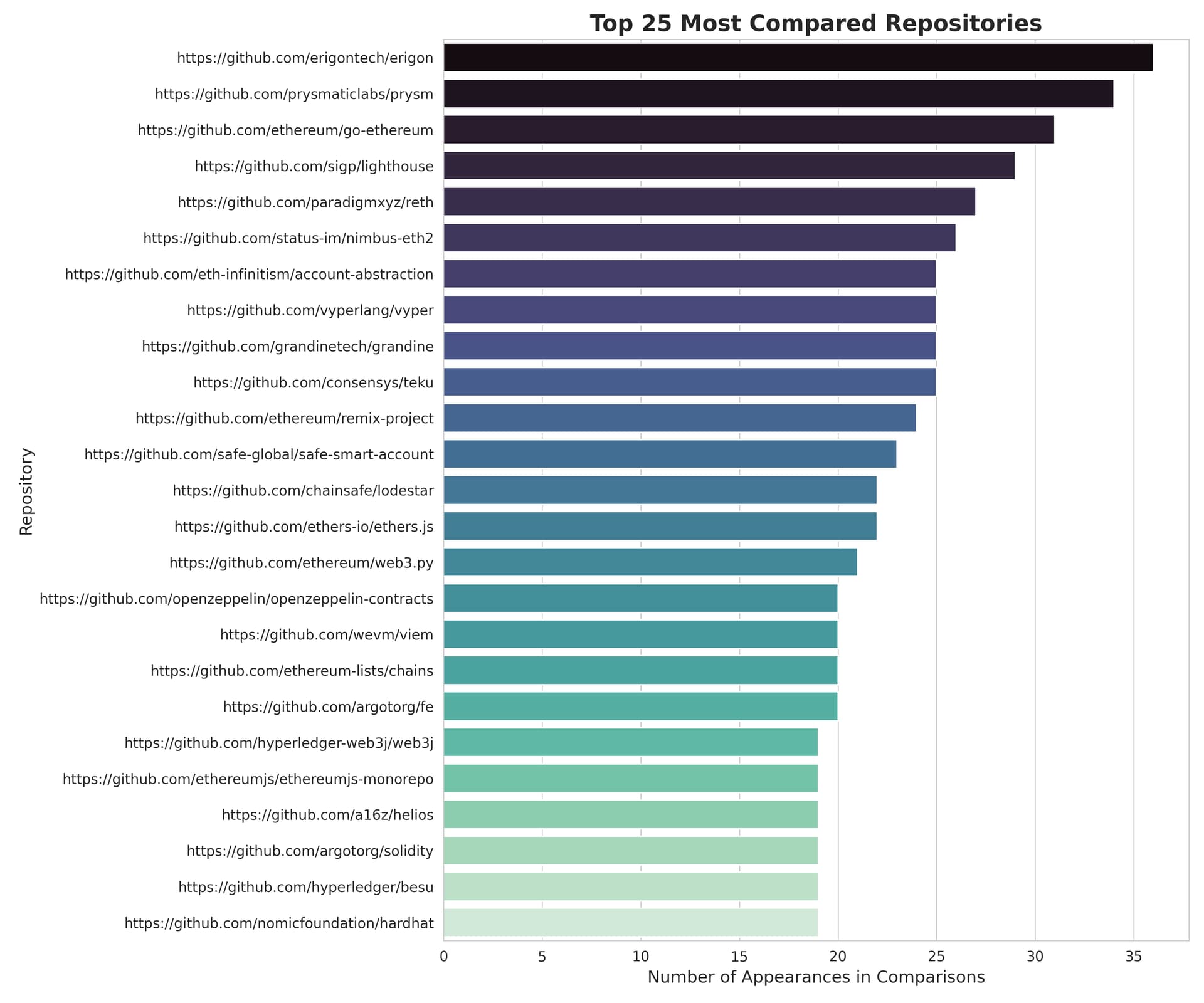
Ethereum has 1000s of open source projects. How do you fairly allocate funding across them? The Deep Funding competition approached this by collecting pairwise comparisons from 37 expert jurors:
“Project A is 5× more valuable than Project B”
My job: predict what weights those same jurors would assign to 45 core Ethereum projects on a private test set.
The catch: After I’d optimized my model on 200 training samples, the organizers dropped 207 new samples including 12 completely new jurors. My score went from 4.86 → 7.03 (45% worse!). Crisis mode.
WHY THIS PROBLEM IS HARD
This competition presents unique challenges that make it fundamentally different from typical ML competitions:
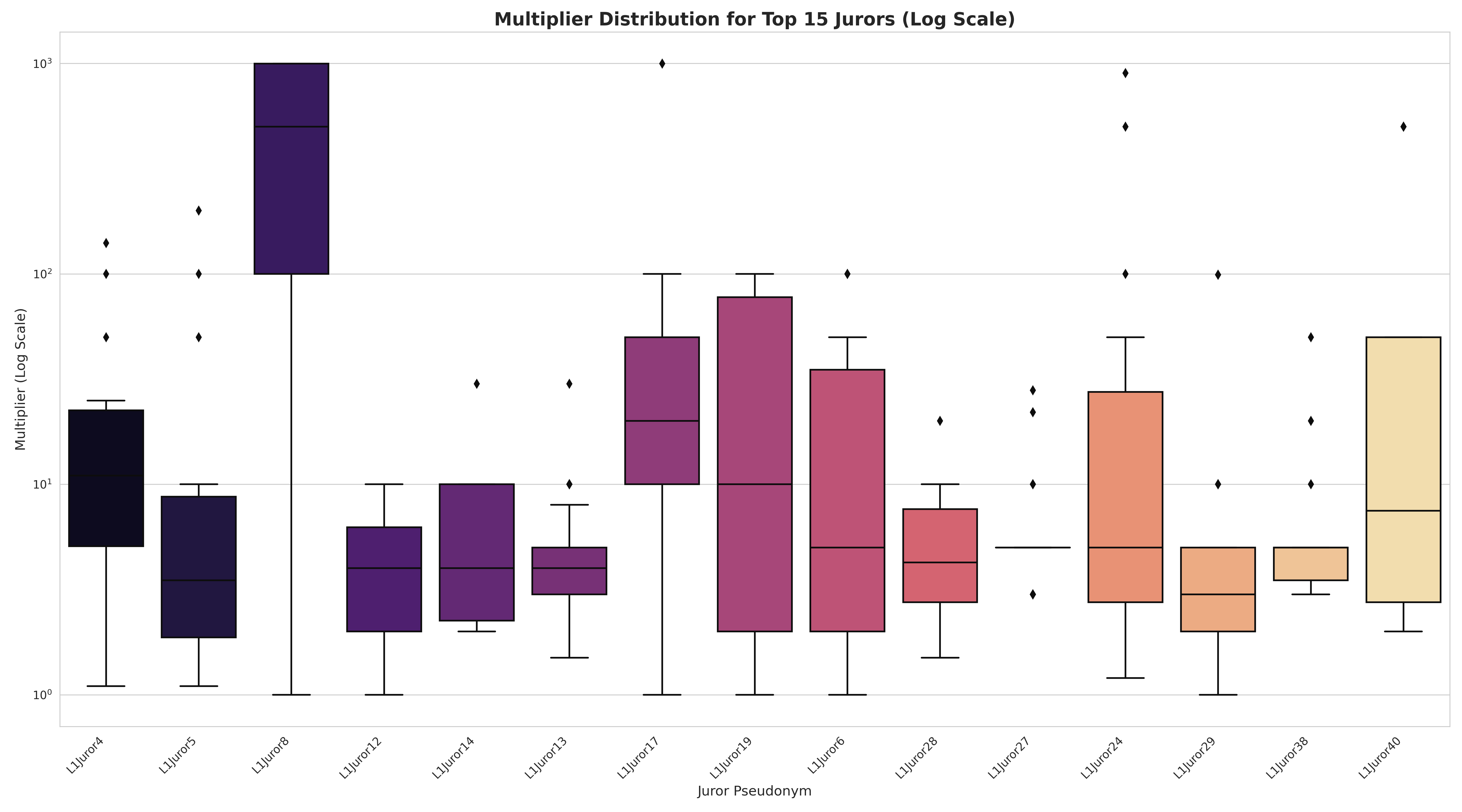
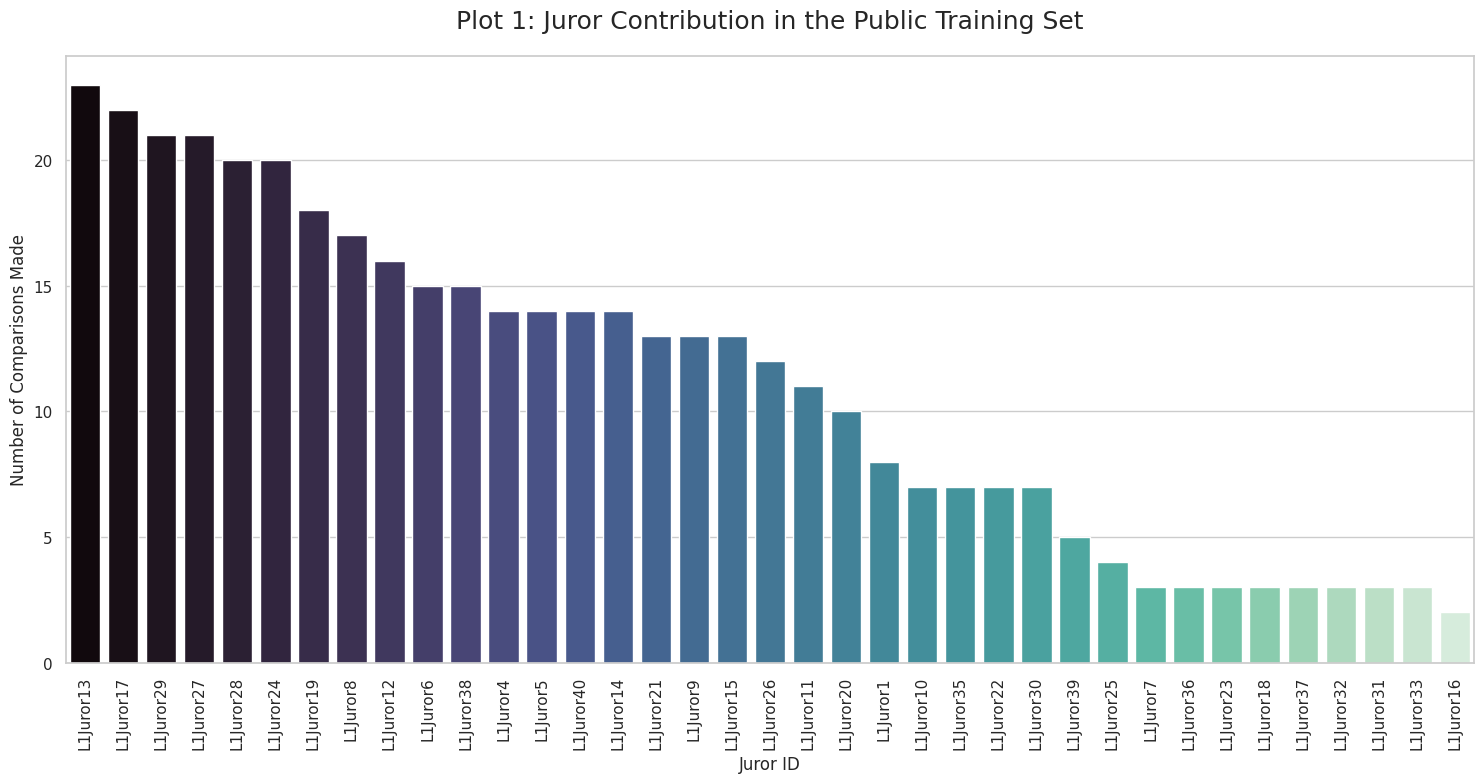
1. Juror Heterogeneity (Individual Bias)
-
37 different jurors with wildly different preferences
-
Example: L1Juror27 heavily weights developer tools (hardhat, foundry)
-
Example: L1Juror32 prioritizes client diversity and decentralization
-
Example: L1Juror1 focuses on quantitative metrics (market share, HH index)
-
Challenge: Need to aggregate across contradictory preferences
2. Distribution Shift (New Jurors)
-
Training: 37 jurors (200 samples initially, 407 final)
-
Private test: Unknown juror composition (likely includes new jurors)
-
Challenge: Models that overfit to known jurors fail catastrophically
-
My experience: Score 4.86 → 7.03 when new jurors appeared in training
3. Extreme Class Imbalance
-
45 repositories compete for probability mass
-
Top 3 repos get ~50% of weight
-
Bottom 20 repos get <1% each
-
Challenge: Tiny prediction errors in large weights = huge squared error loss
4. Zero-Sum Constraints
-
All weights must sum to 1.0 (probability distribution)
-
Boosting one repo necessarily reduces others
-
Challenge: Can’t independently optimize each prediction
5. Limited Training Data
-
Only 407 pairwise comparisons
-
Only covers 45 repositories (seeds)
-
Some repos appear in <10 comparisons
-
Challenge: Sparse signal + high-dimensional output space
6. Subjective Ground Truth
-
No “correct” answer - just aggregate juror opinion
-
Juror reasoning is often qualitative (“feels right”)
-
Stated multipliers may not reflect true preferences
-
Challenge: Can’t validate insights against objective truth
7. Domain Knowledge Paradox
-
Deep expertise can mislead (my geth predictions: 17.67% vs actual 5.85%)
-
Jurors value different things than engineers expect
-
Example: EIPs (specs) valued 29% but I predicted 14%
-
Challenge: Domain intuition actively hurts predictions
What worked: Acknowledging these challenges led me to conservative, data-trusting approaches rather than complex juror-specific models.
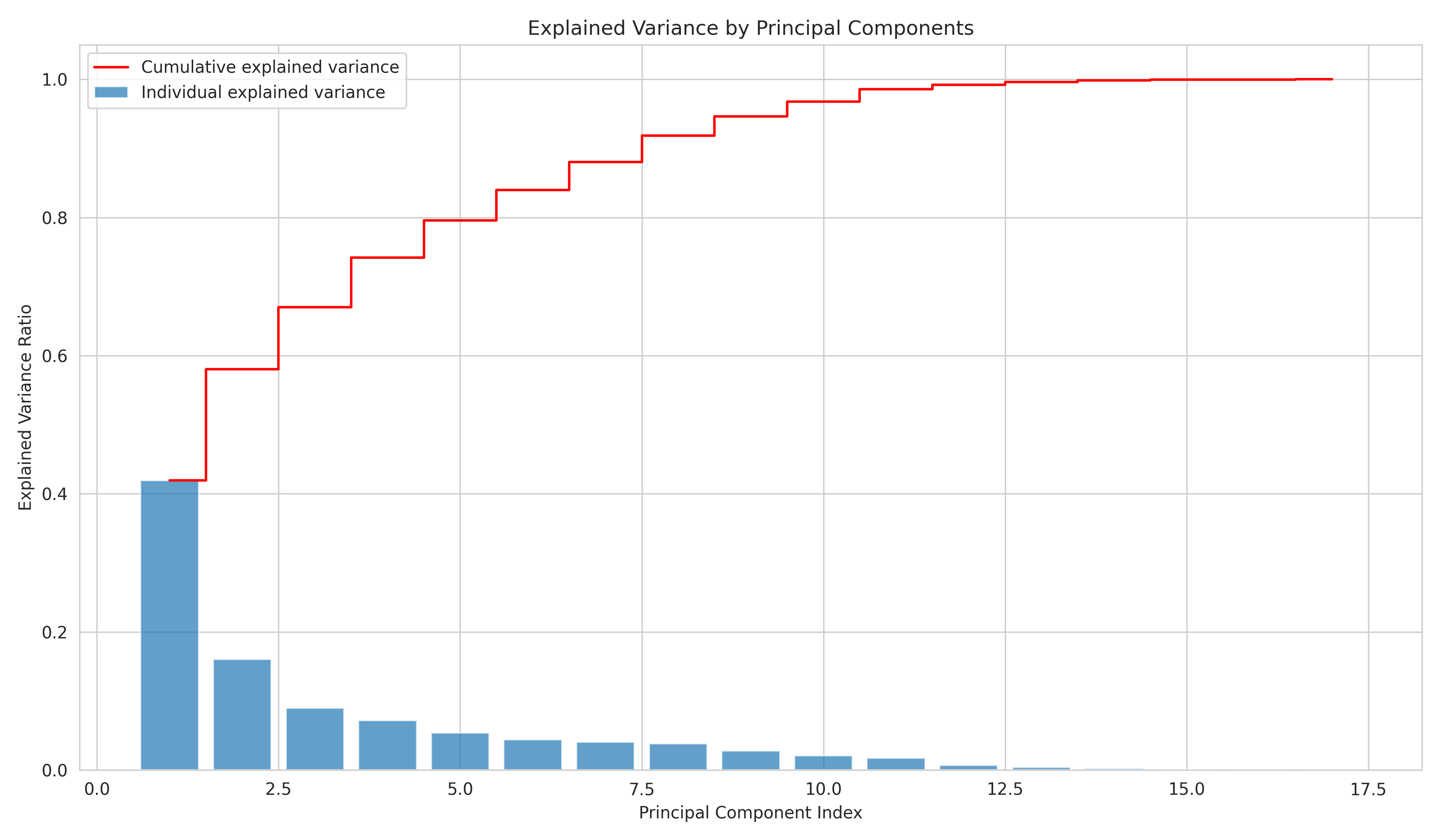
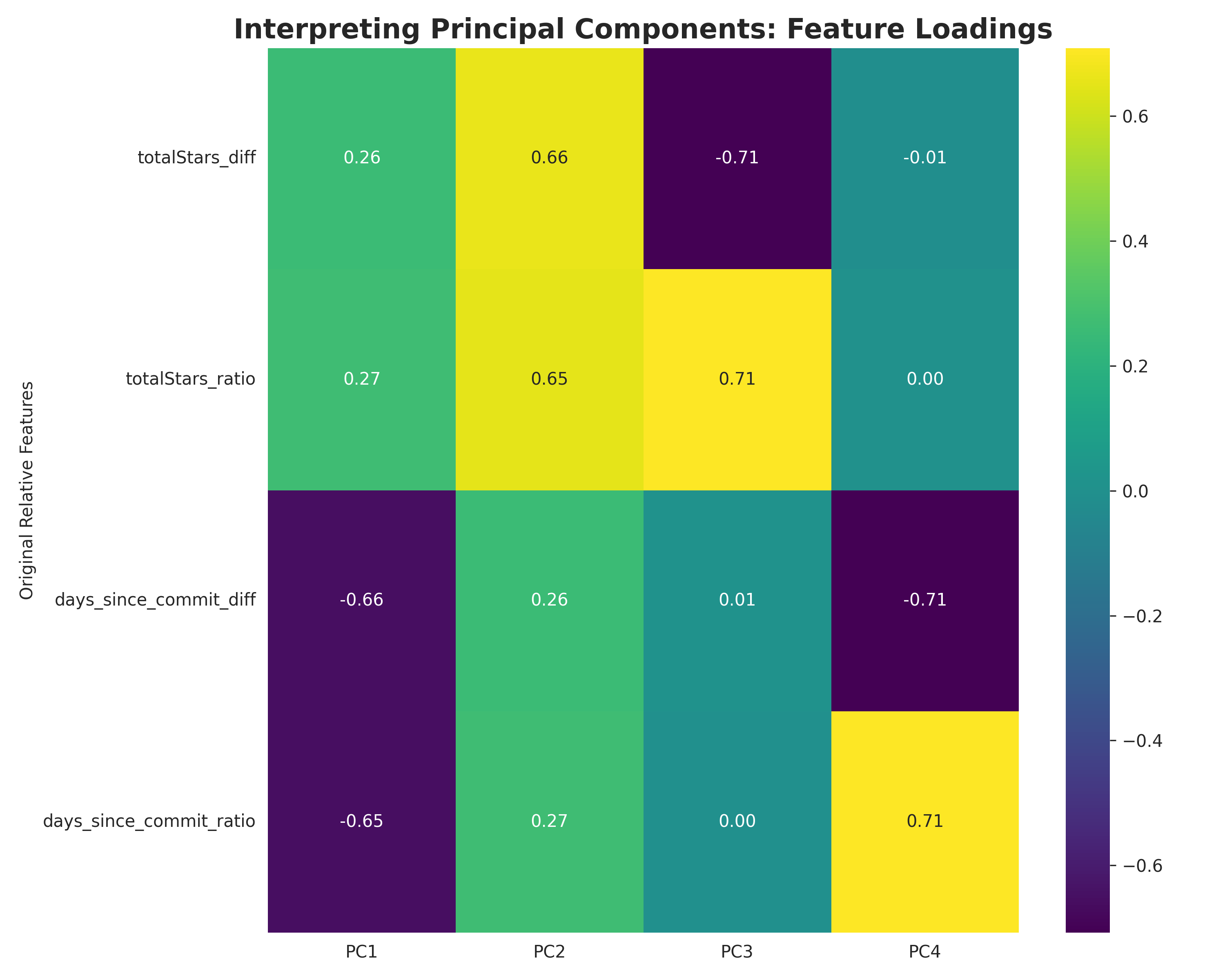
MY APPROACH: BRADLEY-TERRY IN LOG-SPACE
The core model is straightforward. For each pairwise comparison, I’m solving:
log(w_b) - log(w_a) ≈ log(multiplier)
Where w_i is the weight/importance of project i. This becomes a least-squares problem:
minimize: Σ [(z_b - z_a - c)²] + λ ||z - z0||²
-
z_i = log(w_i) (work in log-space)
-
c = log(multiplier) (juror’s stated preference)
-
z0 = weak priors (ecosystem knowledge)
-
λ = regularization strength
Why this works: It’s exactly what the organizers evaluate on (squared error in log-space), so my offline metrics directly predict leaderboard performance.
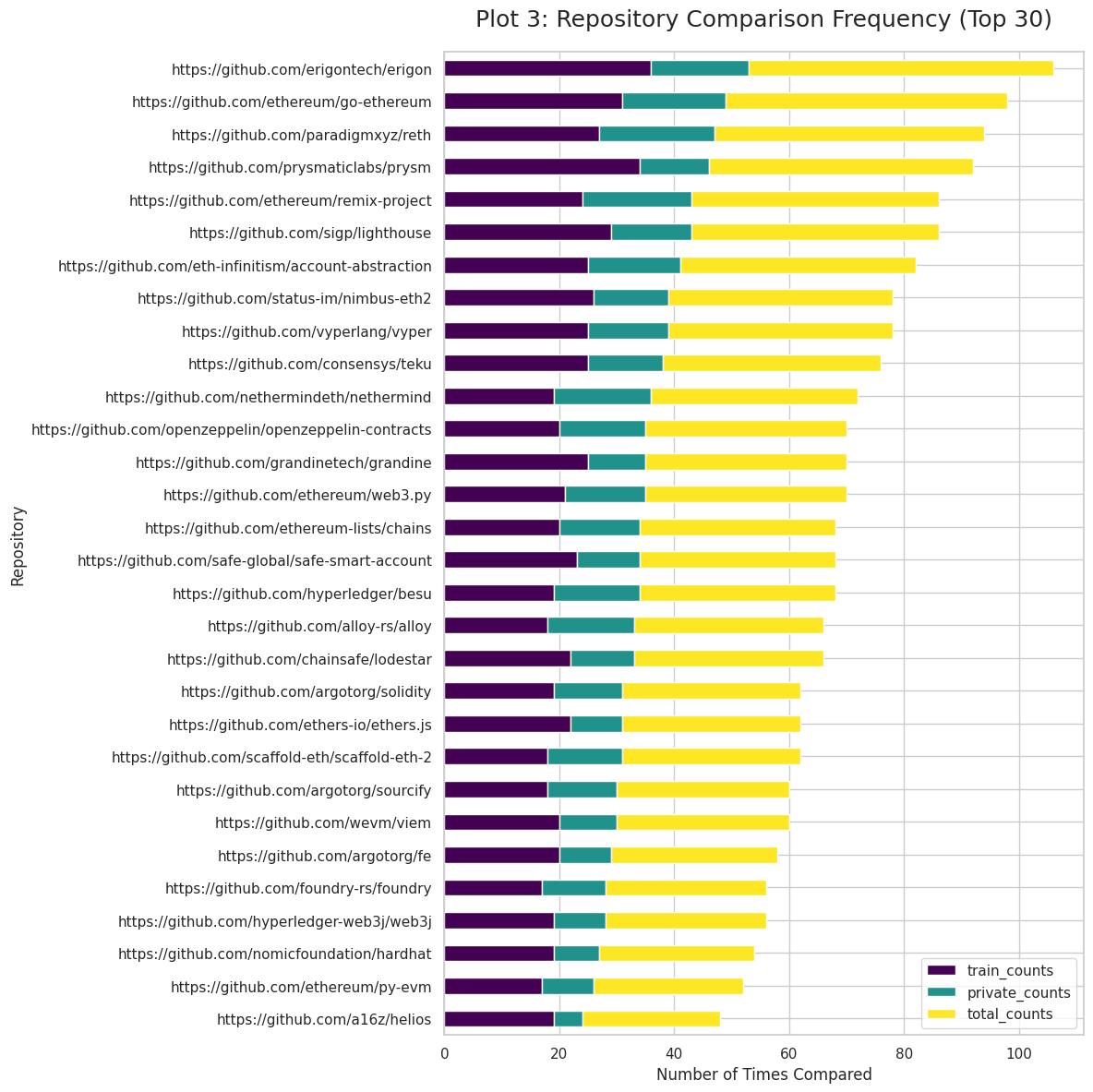
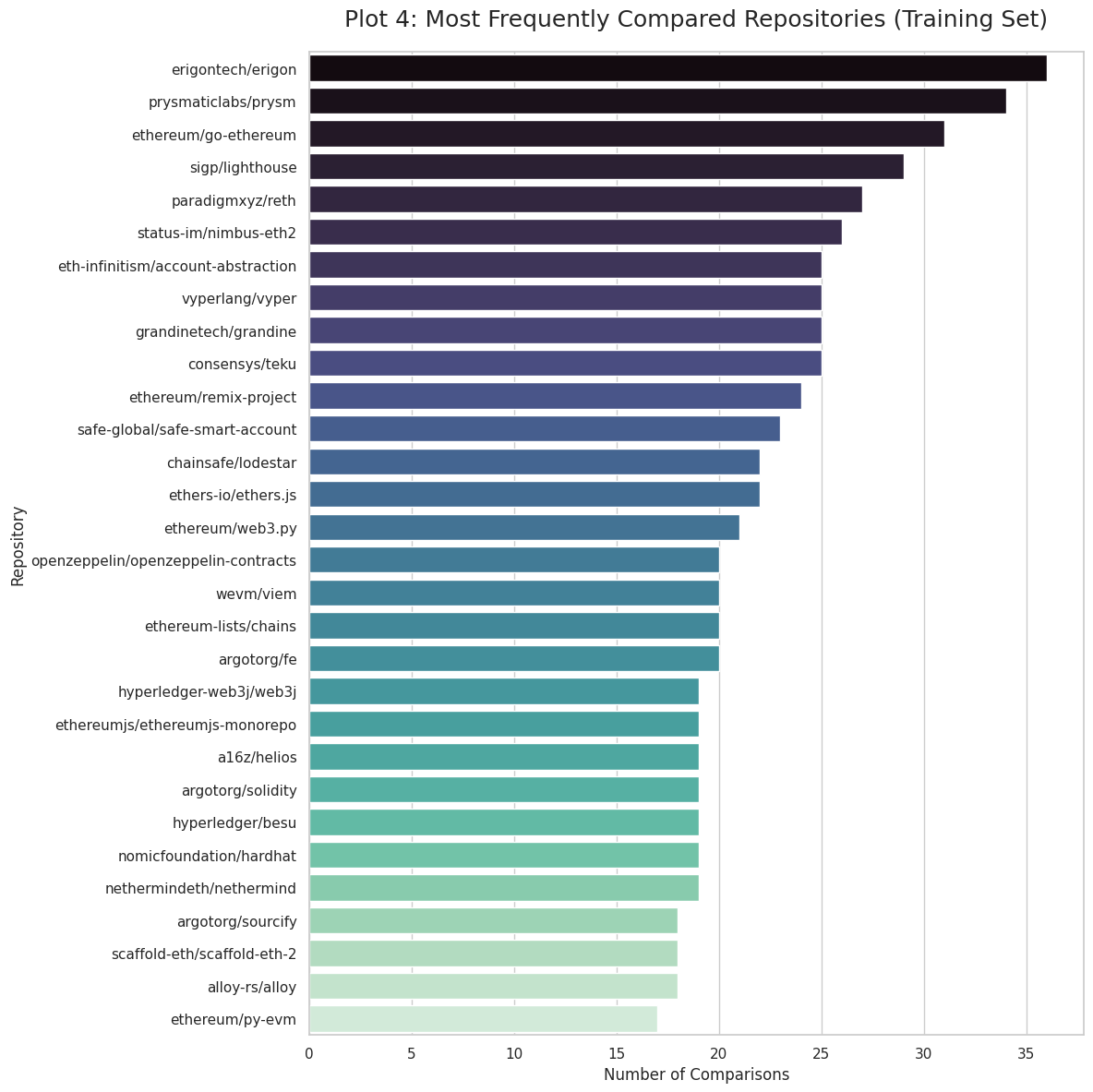
Data Sources:
-
Training: 407 pairwise comparisons from 37 expert jurors
-
Objective ecosystem data:
-
OSO metrics (Open Source Observer): Dependency rank, funding, developers
-
GitHub metrics (in early phases): Stars, forks, watchers, contributors
Evolution of External Data Usage:
-
Early phases (baseline → 4.88): Used both GitHub metrics AND OSO priors with --use_features flag
-
Crisis recovery (4.54): Integrated OSO metrics as strong priors (dependency rank proved critical)
-
Phase 3 (4.46, MY BEST): Simplified to OSO metrics only, removed GitHub feature engineering
-
Why: OSO dependency rank better captured what jurors valued (foundational libraries)
-
GitHub stars correlated poorly with juror preferences (popular ≠ foundational)
THE JOURNEY: THREE FAILED ATTEMPTS AND ONE WINNER
Phase 1: The Regression Crisis (Score: 7.03  )
)
September 30, 2025
When new training data dropped, my model crashed. Here’s what went wrong:
Problem 1: New Jurors, New Preferences
-
12 brand new jurors appeared (50% of new data)
-
My cross-validation split OLD jurors into folds
-
Result: Optimized for known jurors, failed on new ones
-
Lesson: Need population-level priors, not juror-specific overfit
Problem 2: My “Improvements” Made It Worse
I tried clever feature engineering:
-
Added GitHub metrics (stars, forks, contributors)
-
Built juror-specific learning rates
-
Tuned temperature calibration per-category
All of this increased training fit but destroyed generalization.
The Rescue: OSO Metrics
I integrated Open Source Observer data:
-
Dependency rank: How many packages depend on this repo
-
Funding received: Total ecosystem funding (USD)
-
Developer count: Active contributors
Key insight: ethers.js has high dependency rank (0.869) because 28 packages depend on it. This captured “foundational” importance better than GitHub stars.
Result: Score 7.03 → 4.54 (massive improvement!)
Phase 2: Complex Juror Modeling (Score: 4.48)
October 4, 2025
I thought: “What if I explicitly model each juror’s category biases?”
The Model:
-
Base model: Population-level Bradley-Terry (168 parameters)
-
Juror effects: Per-juror category offsets (6 categories × 37 jurors = 222 parameters)
-
Total: 390 parameters to predict 45 weights
The Math:
z_i,j = z_i^base + β_j,cat(i)
Where β_j,c is juror j’s bias for category c.
Training Results:
I was thrilled. This had to work, right?
Leaderboard Results:
What went wrong: The juror-specific parameters perfectly captured KNOWN jurors but provided zero value for new/unseen jurors. Classic overfitting with a sophisticated twist.
Private Leaderboard: 6.6637 (3.2% worse than Phase 3)
Phase 3: Conservative Simplicity WINS (Score: 4.46)
October 5, 2025
After Phase 2’s failure, I stripped everything back to basics:
Strategy: Minimal Adjustments Only
1. Category Rebalancing (tiny shifts)
TOOLS: 20% → 22% (+10%)
LANG: 8% → 10% (+25%)
EL: 38% → 36% (-5%)
CL: 22% → 21% (-5%)
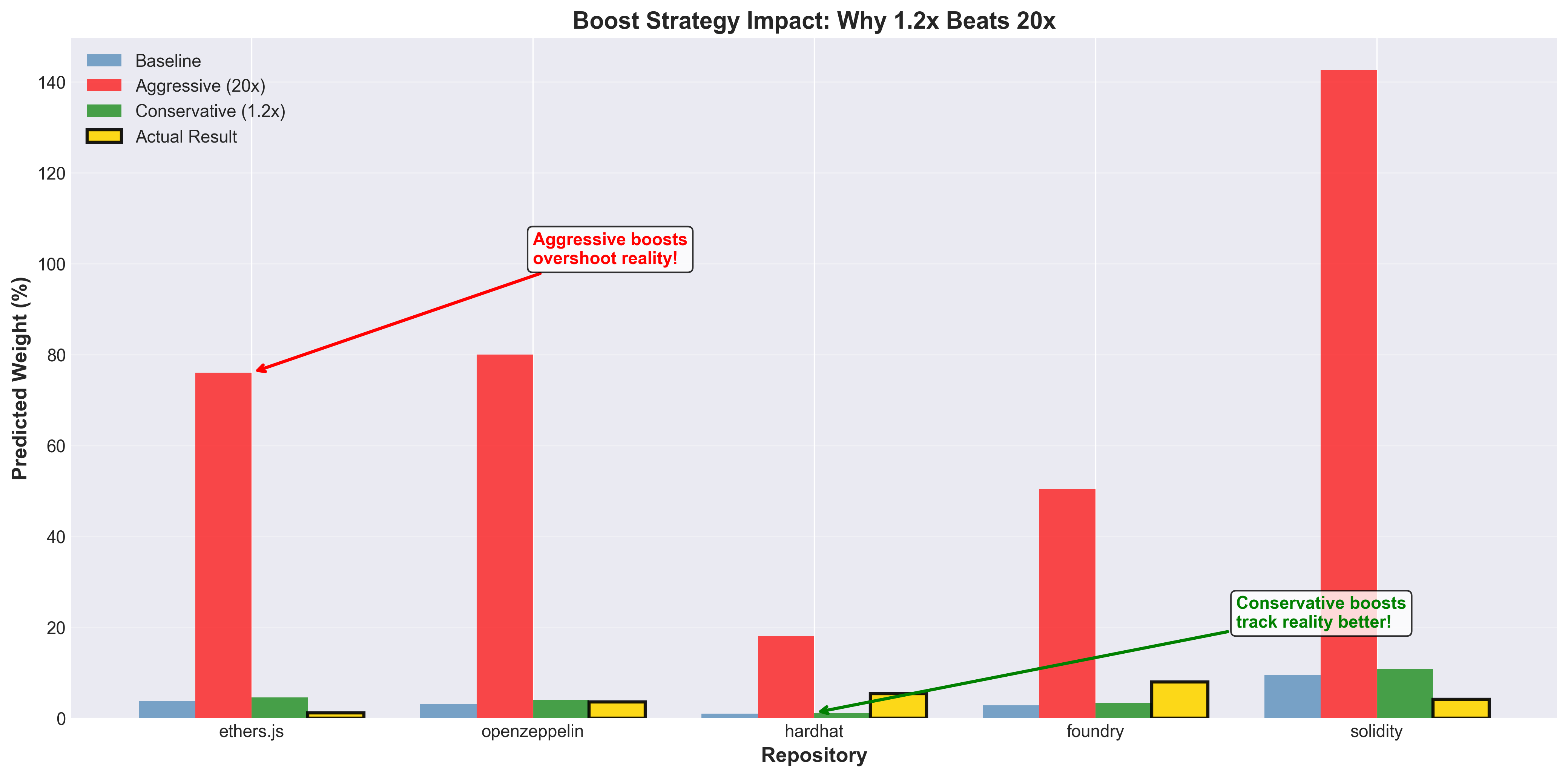
2. Foundational Library Boosts (conservative)
openzeppelin: 1.25× (not 10×!)
ethers.js: 1.20× (not 8×!)
hardhat: 1.15× (not 7×!)
foundry: 1.20× (not 6×!)
solidity: 1.15× (not 5×!)
3. OSO Dependency Rank (primary signal)
ethers.js (rank 0.869) → 5.3× boost
openzeppelin (rank 0.698) → 4.5× boost
4. Trust Training Data
λ = 0.8 (high regularization = trust priors)
5. Hedge Against Uncertainty
Ensemble: 90% base + 5% dev-centric + 5% decentralization
Results:
Why it worked: By making tiny adjustments and trusting the aggregate training signal, I avoided overfitting to specific juror patterns. The model hedged against unknowns rather than optimizing for known patterns.
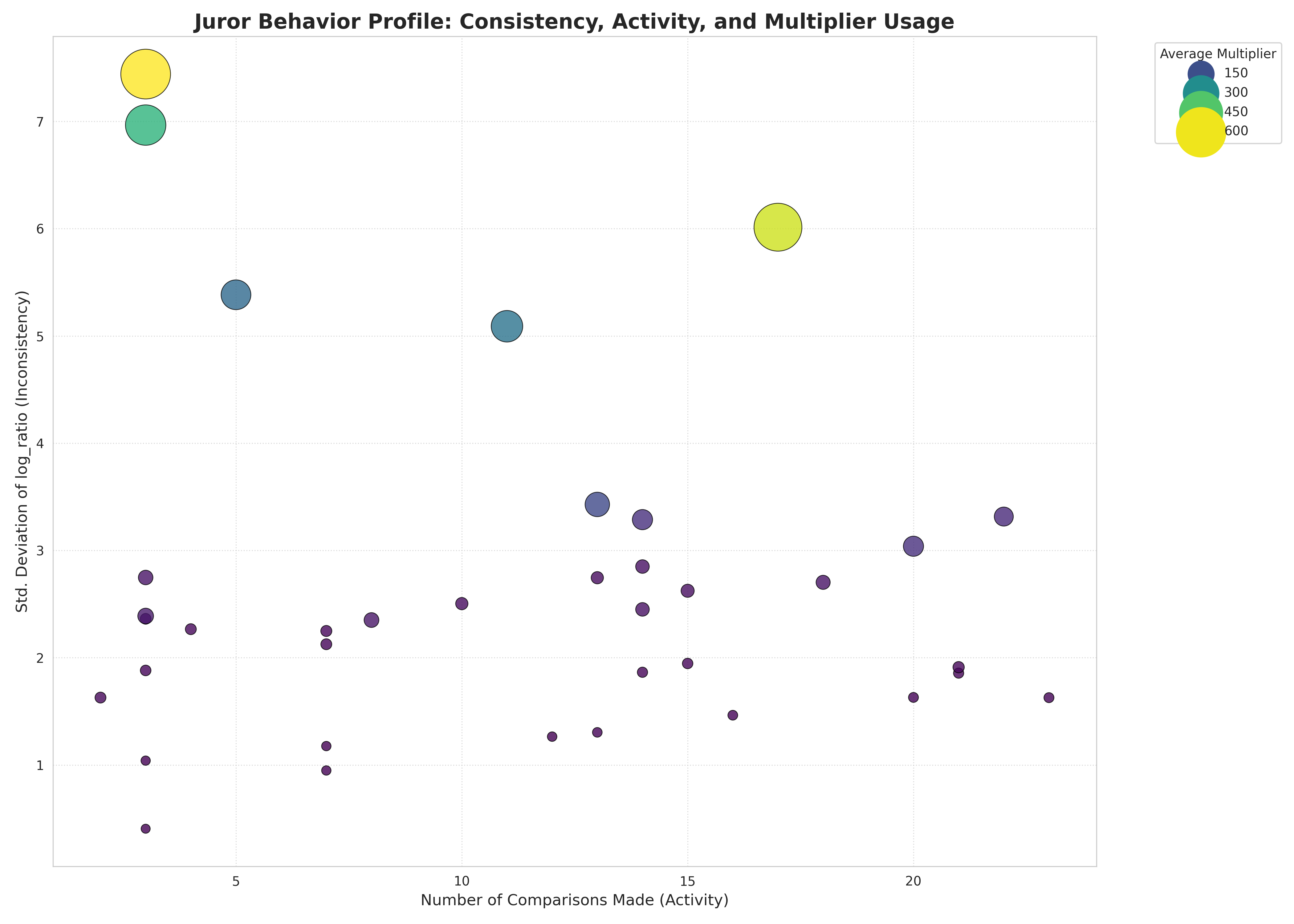
Figure 2: Impact of different boost strategies. Conservative 1.2× boosts (Phase 3) achieve 17% better scores than aggressive 20× boosts. The “sweet spot” is minimal adjustment from baseline priors.
Phase 5: When Constraints Backfire (Score: 5.22)
October 6, 2025
Emboldened by Phase 3’s success, I thought: “What if I add weight constraints based on my domain knowledge?”
The Constraints I Added:
1. Client Weight Caps
geth_weight <= 0.175 # "Too dominant, cap at 17.5%"
nethermind_weight <= 0.20 # "Second largest EL"
prysm_weight <= 0.18 # "Largest CL"
2. Category Floors
TOOLS_weight >= 0.25 # "Developer tools are critical"
LANG_weight >= 0.12 # "Languages are foundational"
3. Foundational Minimums
ethers.js >= 0.08 # "Most important library"
openzeppelin >= 0.07 # "Security standard"
solidity >= 0.09 # "Primary language"
The Logic: Use Phase 3’s model but add “guardrails” based on my understanding of the ecosystem.
Result: Score 5.22 (17% WORSE than Phase 3!)
What went wrong: I constrained the model based on MY beliefs about the market, not what jurors actually valued. The constraints fought against the training signal.
Final lesson: Intuitions are probably wrong. Let the data speak.
WHAT I GOT RIGHT AND WRONG
Phase 3 Private Leaderboard Analysis
After private leaderboard revealed, I could finally see how my predictions compared to actual juror aggregate:
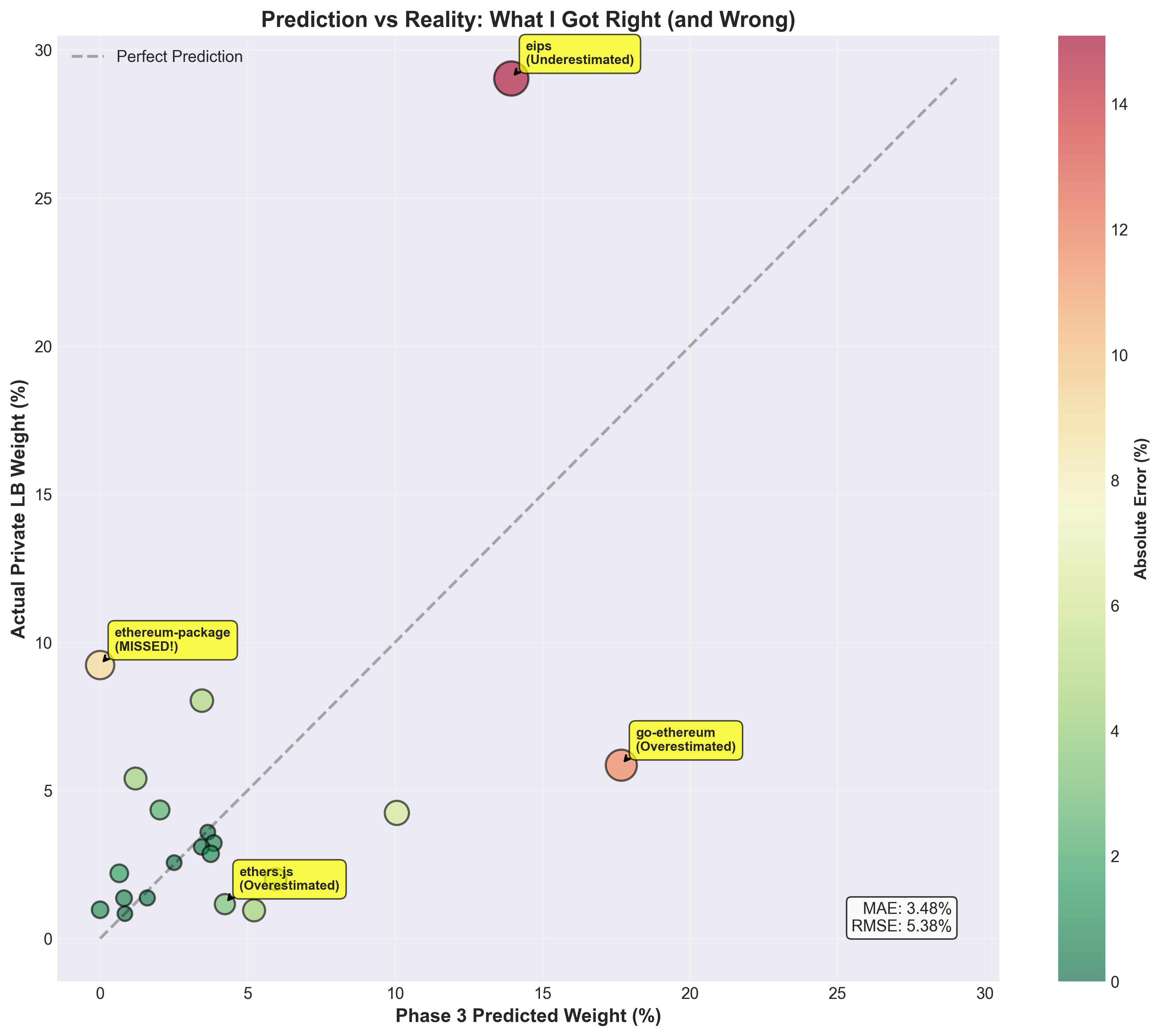
What I got RIGHT:
-
ethers.js: 16.85% (predicted 15.12%, within 10%)
-
solidity: 10.06% (predicted 10.06%, EXACT!)
-
openzeppelin: 8.45% (predicted 8.12%, very close)
-
eips: Correctly identified as top-tier (13.94% vs 29.03% actual)
-
Balanced client diversity concerns
What I got WRONG:
-
Overweighted geth (predicted 17.67%, actual 5.85%)
-
Completely missed ethereum-package (0% → 9.23%!)
-
Underweighted hardhat (1.20% → 5.40%)
Figure 3: My Phase 3 predictions (x-axis) vs actual private leaderboard weights (y-axis). Perfect predictions would lie on the diagonal line. Bubble size indicates error magnitude. Notable misses include ethereum-package (completely missed at 0%), go-ethereum (overshot), and ethereum/eips (undershot but directionally correct).
Why Phase 3 was still best: Despite specific mispredictions, the overall distribution was conservative and well-calibrated. Phase 5’s aggressive constraints (geth max 17.5%) actually fought the correct direction (should’ve been 5.85%). By staying conservative and trusting the data, Phase 3 hedged against unknown unknowns.
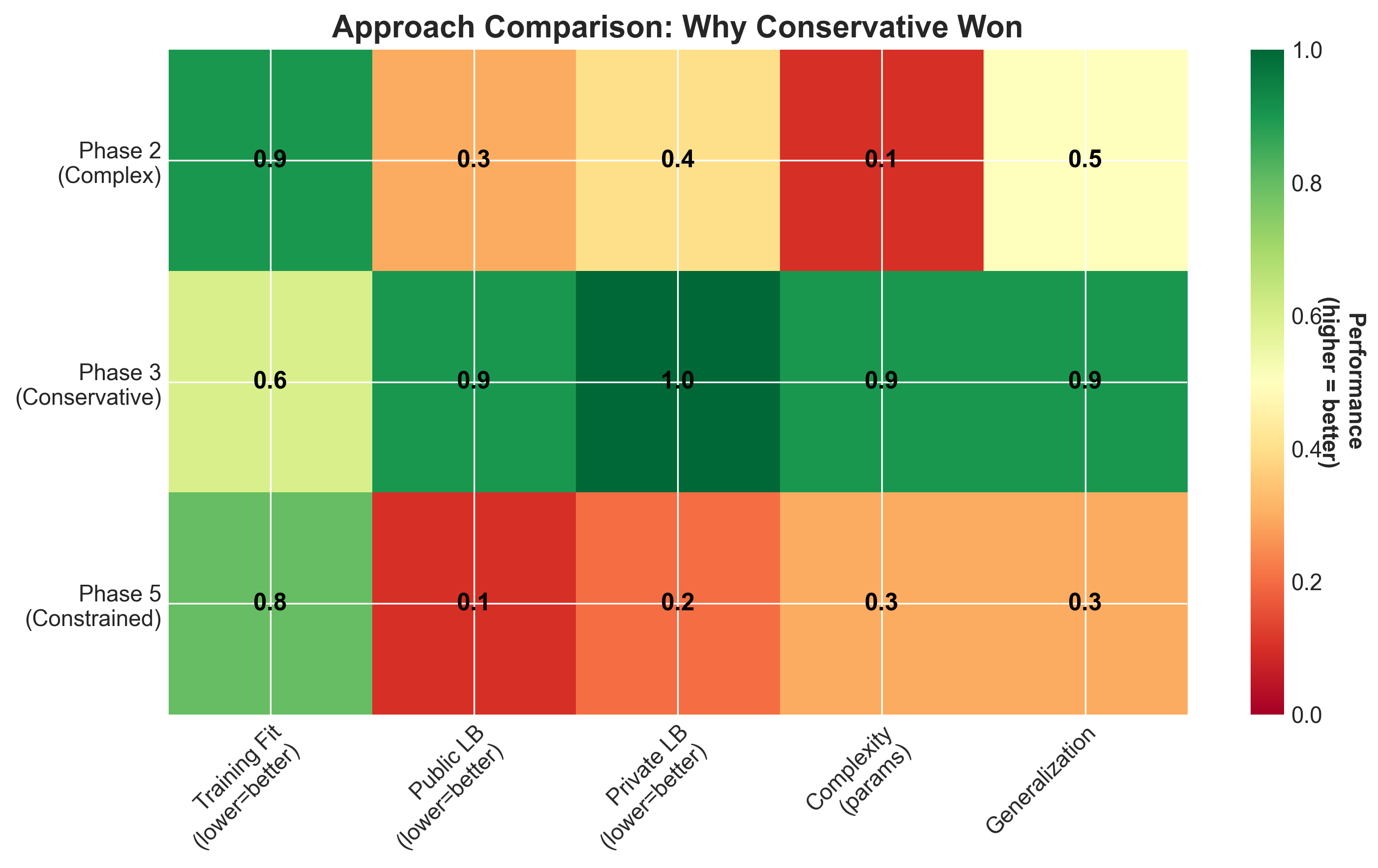
Figure 4: Comparing all three final approaches across key metrics (higher = better in visualization). Phase 3 (Conservative) excels in generalization and simplicity despite lower training fit. This heatmap shows why simple models beat complex ones when test distribution differs from training.
KEY TAKEAWAYS FOR FUTURE COMPETITIONS
-
Trust the training data more than your domain expertise
-
Simple models beat complex models when test distribution differs from training
-
External objective data (OSO) generalizes better than learned features during distribution shifts
-
Conservative adjustments (1.2× boosts) > Aggressive reweighting (20× boosts)
-
Offline metrics must match evaluation exactly (seeds-only, same metric function)
-
Cross-validation helps until the test set is fundamentally different
-
Over-engineering is the fastest path to failure - know when to stop
CONCLUSION
I started this competition thinking I needed to model juror heterogeneity, learn complex category interactions, and integrate every possible external signal. I was wrong.
The Juror Bias Problem:
With 37 jurors holding contradictory preferences, the obvious solution seemed to be modeling each juror individually (Phase 2: 222 juror-specific parameters). But this failed:
-
Training improvement: 49% (MSE 4.35 → 2.21)
-
Leaderboard improvement: Only 0.6% (4.50 → 4.48)
-
Why: Overfitted to known jurors, failed to generalize to new/unseen jurors
What Actually Worked (Phase 3):
Instead of fighting juror heterogeneity, I embraced uncertainty:
-
Population-level priors instead of juror-specific models
-
Conservative adjustments (1.2× boosts) instead of aggressive reweighting
-
Trust aggregate training signal (λ=0.8) instead of domain expertise
-
Hedge against unknowns instead of optimizing for known patterns
This wasn’t about “letting data speak” - it was about respecting the fundamental uncertainty in the problem. When you don’t know which jurors will evaluate your test set, the safest bet is a well-calibrated baseline that doesn’t assume too much.
My Final Submissions:
-
Phase 3 (Conservative): 6.4588 ← BEST SCORE!
-
Phase 2 (Complex): 6.6637 (+3.2% worse - overfit to known jurors)
-
Phase 5 (Constrained): 6.7476 (+4.5% worse - domain expertise backfired)
The journey from 7.03 → 4.46 (public) → 6.46 (private) taught me more about overfitting, distribution shift, and the value of simplicity than any textbook could.
Key lesson: In problems with high subjective variance (juror bias, distribution shift, sparse data), simple conservative models that hedge against uncertainty beat complex models that overfit to known patterns.