Z-Order Mapped Responsibility-Driven Dissemination (ZORDD)
This is intended for ‘supernodes’, assumes they are already sync’d (no backfilling in progress)
ZORDD
ZORDD changes the data dissemination method and the peer selection logic by creating a stronger correlation between network topology and eventual data custody responsibilities. It relies on several key principles:
- Z-Order Mapping: Data is mapped to positions on a Z-order curve (a space-filling curve that preserves locality)
- Responsibility-Driven Forwarding: Messages are primarily forwarded to nodes whose responsibility zones align with the target data
- Adaptive Redundancy: Limited redundancy is applied based on network conditions, data criticality, and Z-distance to target
- Optimized Connection Topology: The network connection pattern is optimized for Z-order traversal
- Non-supernodes retain the existing PeerDAS gossiping, and can use the peer selection logic when searching for missing columns.
- Supernodes adopt the peer selection logic
Z-Order Mapping
The Z-order curve (also known as Morton ordering) maps multi-dimensional data to a one-dimensional space while preserving locality relationships. In ZORDD, we map both data objects and node responsibilities to positions on this curve.
For a data column, we calculate its Z-order position using the block root and column index:
def compute_subnet_for_data_column_sidecar_zordd(column_index: ColumnIndex, block_root: Root) -> SubnetID:
# Extract coordinates from block_root and column_index
coordinates = []
coordinates.append(uint64(int.from_bytes(block_root[:16], byteorder='big')))
coordinates.append(uint64(column_index))
# Calculate Z-order position
z_position = calculate_z_order(coordinates, BITS_PER_DIMENSION)
# Map Z-order position to subnet
return SubnetID(z_position % DATA_COLUMN_SIDECAR_SUBNET_COUNT)
This creates a relationship between data positions and node responsibilities that can be leveraged for efficient routing.
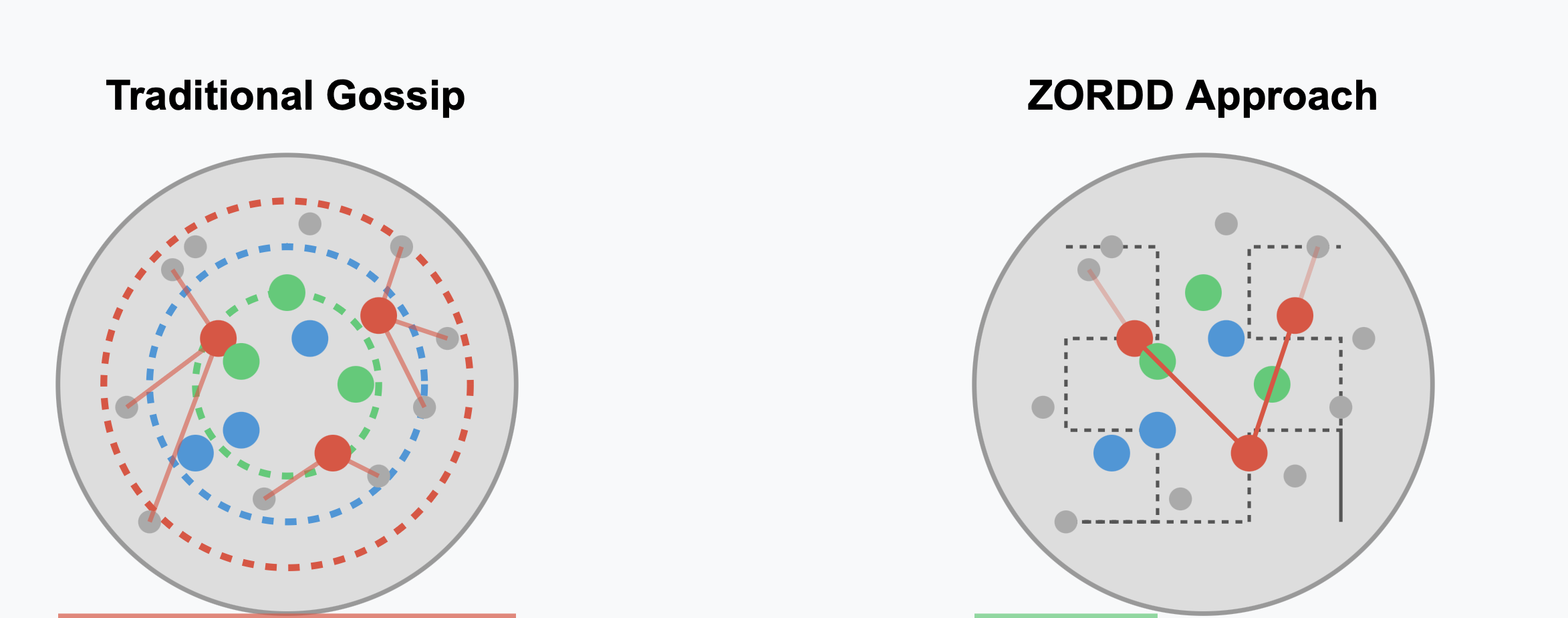
Responsibility-Driven Forwarding
Instead of broadcasting to all peers, nodes forward data primarily to peers whose responsibility zones are close to the data’s Z-order position. This dramatically reduces unnecessary transmissions.
Responsibility zones are just a subnet cluster of nodes
Traditional Gossip
Where N is the number of target nodes
- O(N × log(N) × redundancy_factor)
ZORDD
- O(N × (1 + limited_redundancy))
The peer selection algorithm uses a scoring formula:
Score(peer) = 0.6 * (1 - Z_distance/Z_max) + 0.3 * NetworkQuality + 0.1 * ReliabilityHistory
Where:
Z_distanceis the distance between the peer’s responsibility zone and the data positionNetworkQualityconsiders latency, bandwidth, and congestionReliabilityHistoryreflects past delivery success rates
Tuneable Parameters
Adaptive Redundancy
To ensure reliable delivery while minimizing redundancy, ZORDD applies an adaptive redundancy factor:
RedundancyFactor = BASE_REDUNDANCY * (1 + NetworkLossFactor) * CriticalityMultiplier * DistanceFactor
This formula increases redundancy when:
- Network conditions deteriorate (higher loss rates)
- Data is particularly critical
- Target responsibilities are distant from the current node
This can be done in response to node churn results, mass exists, etc.
Remarks
Feedback welcomed