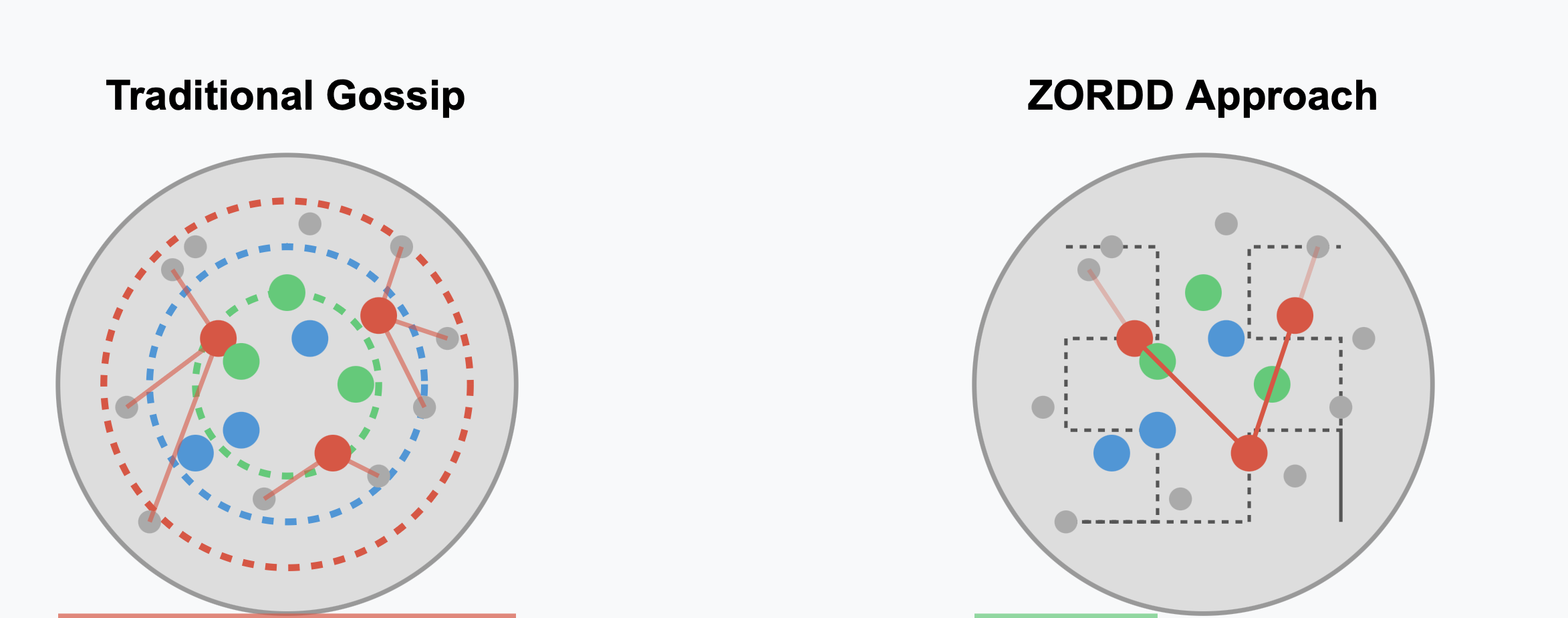
Z-Order Mapper
class ZOrderMapper:
def __init__(self, dimensions=2, bits_per_dimension=16):
self.dimensions = dimensions
self.bits_per_dimension = bits_per_dimension
# Calculate max distance based on total bits
self.total_bits = self.dimensions * self.bits_per_dimension
self.max_z_value = (1 << self.total_bits) - 1
# Max distance is conceptually the full range, simplify for scoring
self.max_distance = self.max_z_value
def calculate_z_order(self, coordinates):
"""Calculates the Z-order value for a list of coordinates."""
result = 0
if len(coordinates) != self.dimensions:
raise ValueError(f"Expected {self.dimensions} coordinates, got {len(coordinates)}")
for bit_position in range(self.bits_per_dimension - 1, -1, -1):
for dimension in range(self.dimensions):
# Ensure coordinate doesn't exceed bits_per_dimension limit
if coordinates[dimension] >= (1 << self.bits_per_dimension):
# Option 1: Raise error
# raise ValueError(f"Coordinate {coordinates[dimension]} exceeds limit for {self.bits_per_dimension} bits")
# Option 2: Clamp or wrap (Using modulo here for simplicity, clamping might be better)
coord_val = coordinates[dimension] % (1 << self.bits_per_dimension)
else:
coord_val = coordinates[dimension]
bit_value = (coord_val >> bit_position) & 1
result = (result << 1) | bit_value
return result
# Helper to generate coordinates (example - adapt based on actual Root/ColumnIndex types)
def hash_to_coordinates(self, block_root: bytes, column_index: int) -> list[int]:
# Example: use first 16 bytes of root for one dimension, column index for other
# Ensure types match expected coordinate types (e.g., uint64)
# This needs refinement based on final spec for coordinate generation
coord1 = int.from_bytes(block_root[:8], byteorder='big') # Example: uint64 from first 8 bytes
coord2 = int(column_index) # Example: uint64 for column index
# Adjust number of dimensions and extraction logic as needed
if self.dimensions == 2:
# Clamp coordinates to fit within bits_per_dimension
max_coord_val = (1 << self.bits_per_dimension) - 1
coord1 = min(coord1, max_coord_val)
coord2 = min(coord2, max_coord_val)
return [coord1, coord2]
else:
# Extend logic for more dimensions
raise NotImplementedError("Coordinate generation for >2 dimensions not defined here")
Forwarding Decision Engine
import math
import random # For redundancy tie-breaking or selection
# Placeholder types/classes
class DataColumn: # Simplified representation
def __init__(self, index: ColumnIndex, block_root: Root, data: bytes):
self.index = index
self.block_root = block_root
self.data = data
class Peer: # Simplified representation
def __init__(self, peer_id: str):
self.id = peer_id
# Other attributes like IP, port etc.
class NetworkMonitor: # Placeholder
def get_quality(self, peer: Peer) -> float:
# Returns a score 0.0-1.0 indicating network quality (latency, bw)
return random.uniform(0.5, 1.0) # Dummy value
def get_reliability(self, peer: Peer) -> float:
# Returns a score 0.0-1.0 indicating historical reliability
return random.uniform(0.7, 1.0) # Dummy value
def get_loss_factor(self) -> float:
# Returns estimated network loss factor (e.g., 0.05 for 5% loss)
return random.uniform(0.01, 0.1) # Dummy value
class ForwardingDecisionEngine:
def __init__(self, z_order_mapper: ZOrderMapper, profiler: ResponsibilityProfiler, network_monitor: NetworkMonitor):
self.z_order_mapper = z_order_mapper
self.profiler = profiler
self.network_monitor = network_monitor
self.BASE_REDUNDANCY = 3 # Example base redundancy
def calculate_z_distance(self, z_position: int, peer: Peer) -> int:
"""Calculates the minimum Z-distance from a position to any of a peer's zones."""
peer_zones = self.profiler.get_peer_zones(peer.id)
if not peer_zones:
# If no zone info, treat as max distance or use alternative metric
return self.z_order_mapper.max_distance
min_dist = self.z_order_mapper.max_distance
for segment in peer_zones:
if z_position >= segment.start and z_position <= segment.end:
return 0 # Position is within this segment
# Calculate distance to the closer end of the segment
dist = min(abs(z_position - segment.start), abs(z_position - segment.end))
min_dist = min(min_dist, dist)
return min_dist
def calculate_redundancy(self, z_position: int) -> int:
"""Calculates the adaptive redundancy factor."""
# This uses the calculate_redundancy function structure from the appendix
base_redundancy = self.BASE_REDUNDANCY
network_loss_factor = self.network_monitor.get_loss_factor()
criticality = 1.0 # Could vary based on data type or context
# Calculate distance factor based on distance to *closest responsible peer zone known*
# This is complex: requires finding minimum distance across *all* peers' zones
# Simplified: use distance to *local* zones as a proxy for how far data is 'from home'
node_min_distance = self.z_order_mapper.max_distance
for segment in self.profiler.local_responsibility_zones:
if z_position >= segment.start and z_position <= segment.end:
node_min_distance = 0
break
dist = min(abs(z_position - segment.start), abs(z_position - segment.end))
node_min_distance = min(node_min_distance, dist)
# Normalize distance (ensure max_distance is not zero)
if self.z_order_mapper.max_distance > 0:
normalized_distance = min(1.0, node_min_distance / self.z_order_mapper.max_distance)
else:
normalized_distance = 0.0
distance_factor = 1.0 + (normalized_distance * 0.5) # Ranges from 1.0 to 1.5
# Calculate final redundancy count, ensuring it's at least 1
redundancy_count = math.ceil(base_redundancy * (1 + network_loss_factor) * criticality * distance_factor)
return max(1, int(redundancy_count)) # Ensure at least one target
def decide_forwarding(self, data_column: DataColumn, peers: list[Peer]) -> list[Peer]:
"""Decides which peers to forward a data column to."""
# Calculate Z-order position for the data column
coordinates = self.z_order_mapper.hash_to_coordinates(data_column.block_root, data_column.index)
z_position = self.z_order_mapper.calculate_z_order(coordinates)
# Rank peers by score
ranked_peers = []
for peer in peers:
# Calculate Z-proximity score (higher is better/closer)
z_distance = self.calculate_z_distance(z_position, peer)
# Ensure max_distance > 0 to avoid division by zero
if self.z_order_mapper.max_distance > 0:
# Clamp distance to max_distance to prevent negative scores if calculation exceeds max
clamped_distance = min(z_distance, self.z_order_mapper.max_distance)
z_proximity_score = 1.0 - (clamped_distance / self.z_order_mapper.max_distance)
else:
z_proximity_score = 1.0 if z_distance == 0 else 0.0 # Max proximity if distance is 0
# Get other metrics
network_quality = self.network_monitor.get_quality(peer)
reliability = self.network_monitor.get_reliability(peer)
# Calculate final score using weighted factors
score = (0.6 * z_proximity_score +
0.3 * network_quality +
0.1 * reliability)
ranked_peers.append((peer, score))
# Sort peers by score, descending (highest score first)
ranked_peers.sort(key=lambda x: x[1], reverse=True)
# Determine number of peers to forward to based on redundancy factor
num_peers_to_select = self.calculate_redundancy(z_position)
# Select the top N peers
selected_peers = [peer for peer, score in ranked_peers[:num_peers_to_select]]
return selected_peers
Commitment Root
Use the root of the blob_kzg_commitments list from the BeaconBlockBody. We can call this the CommitmentRoot.
- ZPos = map_column_to_z_position(ColumnIndex, CommitmentRoot)