Now that stateless clients are looking like the most promising path for eth1.x development, and for early eth1.x merge into eth2, it’s worth looking into exactly what changes are going to be required to make stateless clients viable.
The main challenge that this post explores is looking at stateless client witness sizes (ie. the size of the Merkle proofs that must be provided to help a stateless node verify a block), and how to put practical upper bounds on them.
The status quo
Here I will go over three cases: (i) pure ETH transfers and ERC20 transfers, (ii) “average” blocks, (iii) worst-case DoS blocks.
A Merkle proof for a single account is, assuming 2**28 ~= 16**7 ~= 250m accounts, ~7 512-byte hexary Patricia tree nodes, followed by a ~32 byte key-value node, followed by ~80 bytes of the account data. In a Merkle proof of N accounts, we can ignore the top log_16(N) layers of the tree, because those would be copied between proofs and could be reconstructed from the lower layers. For storage slots of the same account, proofs are slightly less deep, because contracts tend to have fewer storage slots than Ethereum as a whole has accounts (eg. because there are fewer users of MKR than users of ethereum).
We can replicate this logic in these functions:
def estimate_proof_size(accessed_nodes, total_nodes):
return accessed_nodes * 512 * math.log(total_nodes / accessed_nodes) / math.log(16)
def account_proof_size(n): return estimate_proof_size(n, 2**28) + n * 112
def storage_key_proof_size(n): return estimate_proof_size(n, 2**24) + n * 32
Currently, the Ethereum gas limit is 10 million. A pure ETH transfer costs 21000 gas, and touches two accounts: sender and recipient. Hence, a pure ETH transfer block touches a total of 952 accounts, so the proof size would be 2.31 MB.
An ERC20 transfer touches the sender and recipient storage keys of the same ERC20 contract, plus the sender address, plus the ERC20 contract code. It costs ~50k gas (eg. see this MKR transaction costing ~52k). A block full of 200 ERC20 transfers, touching 10 distinct token contracts (taking a random guess) would touch 210 accounts (568 kB proof), 10 contract codes (the MKR contract is 3379 bytes, we’ll say 34 kB), and per contract 40 storage slots (400 storage slots total), giving 969 kB. So that’s 1571 kB total.
As for “real world” blocks, preliminary data provided by @AlexeyAkhunov suggests that Merkle proof sizes are around 600-2200 kB, and code accessed is 200-700 kB.
Now, we get to “worst case” blocks. A worst case block today would consist of 12500 calls (assuming 800 gas cost of calling, including 700 gas for the call + 100 gas to setup parameters for the opcode), each to a max-sized 24 kB contract. That is, 24 MB Merkle proofs, and 300 MB code length, for a total proof size of 324 MB (!!!).
Step 1: hexary trees to binary trees
Binary trees have much lower witness sizes than hexary trees, because while they have 4x more depth, each layer is 16x smaller (8x smaller, but you can elide the parts going directly downward toward the leaf we’re proving and only include sister nodes). The new proof size estimating functions become:
def estimate_proof_size(accessed_nodes, total_nodes):
return accessed_nodes * 32 * math.log2(total_nodes / accessed_nodes)
def account_proof_size(n): return estimate_proof_size(n, 2**28) + 112 * n
def storage_key_proof_size(n): return estimate_proof_size(n, 2**24) + 32 * n
For example, pure ETH transfer blocks decrease from 2.31 MB to 658 kB: about the same as the size of a maximally CALLDATA-filled regular ethereum block post-Istanbul. Pure ERC20 transfer blocks decrease from 1571 kB to 445 kB. Worst case DoS blocks decrease from 324 MB to… 307 MB - no surprise, since we’ve done nothing against code size. But the good news is that if code somehow stops being a problem, a worst case witness is reduced to 7 MB.
Converting our Merkle tree to binary
IMO, the simplest way to convert our Merkle tree from the current hexary Patricia structure to a more efficient binary tree is a “progressive” strategy that works as follows. First of all, we nominally keep the hexary structure, eg. the DB stays hexary. However, for a “new-style” trie node, we change the contents from rlp_encode([node 0, node 1 .... node 15]) to a simple concatenation node 0 ++ node 1 ++ node 15, where each node is filled to 32 bytes even if it is empty. We then, instead of simply sha3’ing the node, Merkle-hash it.
When an account is modified or created after the fork, we add a isNewStyle flag to it. To determine whether a node in the middle of the tree is old-style or new-style, we use a recursive approach: if any of the children of a node is new-style, then that node is new-style. Accounts convert to new-style as soon as they are touched after the fork (so we would need a “poking” strategy similar to that used to delete empty accounts back in 2016).
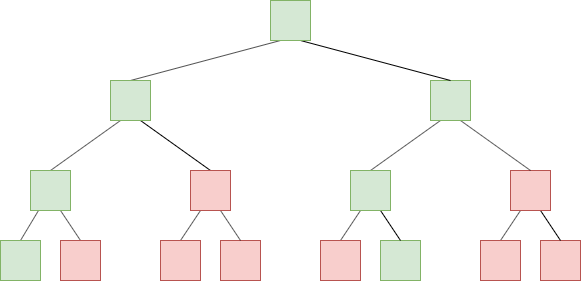
Green = new-style nodes
Red = old-style nodes
Binary used for illustration; in reality this is 16-ary.
Note that this mechanism preserves the property that the state root can be uniquely computed only from the contents of the leaves.
The result here is to progressively migrate toward a tree that is nominally hexary in presentation, but in terms of hash construction is actually a binary tree, and for which we can provide witnesses with similar space efficiency to a binary tree. We also get the benefit that we get rid of RLP at the tree level, and we can also simplify how key-value nodes work (eg. no intermediate key-value nodes, and leaf-level key-value nodes would contain the full key); this greatly simplifies implementation of Merkle proof verification in-EVM.
Increasing gas costs
To bound witness sizes further, we have no choice but to increase some gas costs. First, let us talk about code. We need to add some form of per-byte fee for calling contracts (we’ll say 3 gas per byte to set the max witness size to 3.3 MB). There are two ways that I can think of to do this:
- CALL costs 72000 gas, if the contract called is x < 24000 bytes long or if it was already accessed during this block execution (in that case let x=0), refund either the child or the parent
3 * (24000 - x)gas. - In a new-style account, we also store the size of the contract code in the account body (note that this also allows EXTCODESIZE to work without reading the code). A CALL then works as follows: first pay a little gas to initiate, then charge of the parent
3 * code_size; if insufficient, abort.
(1) is easier to implement but breaks more, as any call even to the smallest contract would require the transaction to have a gaslimit of > 93000. (2) requires more changes, but not that much more if we implement my proposal for progressively changing the trie structure, but is “gentler”.
As option (3), rather than charging for the whole contract code, we could also split up the code into chunks (eg. along JUMPDEST boundaries), use this chunking as the basis for Merkelizing the code root instead of it being a plain hash, and charge 3 gas per byte for only those chunks that are accessed. We could then simply charge code access fees to the child. However, this would require EVM modifications to allow the EVM to return which chunks were accessed by a given code execution. Note also that the code access fees would not just be for the bytes of code accessed; they would also be for the length of a Merkle multiproof for the chunks (we can import logic from eth2 for calculating this). The length of a Merkle multiproof is monotonic in the input, so the “marginal Merkle proof size” for accessing a not-yet-accessed chunk will always be positive, and can easily be computed.
If we do options (1) and (2), then many contracts would likely need to be rewritten for efficiency, breaking themselves up into smaller pieces. Though the average extra gas costs would not be that high; Alexey’s numbers of 200-700 kB per block would imply gas spending per block would go up by 600-2100k, so the de-facto capacity of the chain would decrease by ~6-17% (we could just bump up the gas limit to 12M to compensate for this; this is safe because these changes reduce the harm of the worst possible DoS attacks as a side effect).
If we want to target a worst-case witness size of 3.3 MB (or 4 MB with a 12M gas limit), we would also need to increase the cost of account-reading and storage-accessing opcodes, to also match the 3 gas per byte level. This implies a ~2400 base cost for EXTCODESIZE, BALANCE, CALL and similar opcodes (refundable if the account was already accessed in the block), and ~2000 base cost for SLOAD (multi-accesses would also be refundable).
Summary of gas cost change recommendations
- Charge 3 gas per byte for accessing contract code. This could be either charging for the full contract, or we could implement a scheme where you are only charged for the chunks you access plus Merkle proofs for those chunks.
- Increase gas cost of EXTCODESIZE, BALANCE, *CALL to 2400
- Increase gas cost of SLOAD to 2000
- In all of the above cases, charge only for first-time accesses in a block.
Summary of effects of gas cost changes plus tree binarification
- ETH transfer block witness size drops from 2.31 MB to 658 KB (~780 KB if we increase gas limit to 12M)
- ERC20 transfer block witness size drops from 1.57 MB to 445 KB (~512 KB if we increase gas limit to 12M)
- Worst-case block witness size drops from 324 MB to 3.3 MB (~4 MB if we increase gas limit to 12M)