The Path to Decentralization
By Kevin Liu, Metis Co-Founder and ZKM CEO
In the evolving landscape of blockchain technology, the concept of decentralization has emerged as a guiding principle, especially for Ethereum, where decentralization is the key differential factor and advantage compared with other blockchain ecosystems. However, the problem remains the same now as it did going back to Ethereum’s first baby steps: How do we get there?
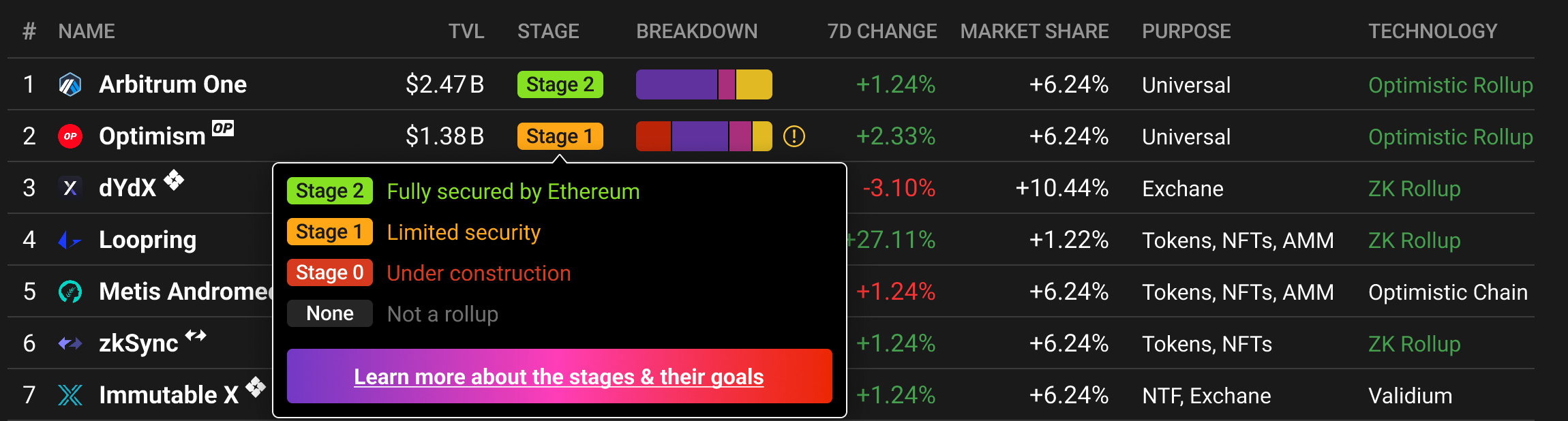
As in this post, Vitalik proposed milestones that Ethereum rollups would need to take to achieve full functionalities and true decentralization. By making it through these stages, rollups would shed their training wheels and meet the most challenging of the three sides of the Blockchain Trilemma.
Vitalik’s proposal did a great job of outlining the What: rollups should become fully functional and technically decentralized. However, decentralization is not just on the technology side, it is a complicated architecture we need to build, so How, exactly, do rollups reach that elusive Decentralization goal?
Having co-founded Metis and then leading a project that’s building infrastructure to enable hybrid rollup technology (ZKM), it’s that How which keeps me up at night.
Stages of Decentralization: A Strategic Blueprint
The journey to full decentralization unfolds in four stages.
Stage 0: Cold Start - Laying the Foundation for Decentralization
Stage 0, the “Cold Start,” initiates the blockchain project and focuses on establishing robust infrastructure. Similar to a heavy construction phase, a core team takes a central role in development and management. While encouraging general community participation, challenges arise in wielding control during this heavy construction phase.
In Stage 0’s complexities, community involvement is integral. While the core team leads heavy construction, projects encourage community participation with activities such as voting and token delegation. The problem is that these activities offer only a superficial sense of decentralization within limited parameters.
To truly advance decentralization, strategic community engagement is crucial. Beyond token-based voting, it’s important to foster genuine community ownership through transparent communication, education, and collaboration. Building a community truly invested in the project’s success lays the groundwork for meaningful decentralization.
Stage 0 Tldr;
- Objective: Lay the groundwork for the business.
- Key Focus: Establish a solid foundation for future development and decentralization efforts.
- Approach: Concentrate on efficiency and execution by building your team, while giving the community a feeling of ownership, if not yet literal ownership.
Stage 1: Infrastructure Decentralization - Unleashing the Power of Utility Tokens
Utility tokens play a dual role in Stage 1. Beyond transactional utility, they become instruments of network security and decentralization. True contributors use utility tokens for staking, mining, voting, and governance, actively shaping the project’s trajectory.
Empowering True Contributors: A Collaborative Construction Approach
Stage 1 heralds an era where infrastructure construction and operation are no longer exclusive to a central authority. True contributors, actively fostering network growth, gain tools and incentives for critical processes. This democratization aligns with decentralization principles and nurtures collective ownership.
Recognizing the significance of infrastructure decentralization is paramount. As the network infrastructure becomes more decentralized, it becomes more resilient, adaptive, and capable of withstanding the challenges that may arise in the dynamic landscape of blockchain technology.
By removing single points of control, leveraging the power of utility tokens, and empowering true contributors, blockchain projects set the stage for a more robust and participatory ecosystem. This evolution is not an isolated accomplishment but a strategic stepping stone towards a decentralized future.
Stage 1 Tldr;
- Objective: Remove technical single points of control.
- Key Focus: Distribute control and ownership of essential components, utilizing utility tokens to secure the network.
- Approach: Enable true contributors to participate in infrastructure construction and operation, fostering a more resilient and censorship-resistant network.
Stage 2: Revenue Sharing - Aligning Interests for Sustainable Growth
Many blockchain projects and ecosystems struggle to handle the diverging goals of short-term token holders vs. long-term stakeholders (such as the core team and key contributors). Short-term token holders prioritize immediate price movements, seeking quick returns, while long-term stakeholders want to build a sustainable future.
Shifting Mindsets: From Airdrop Farming to Ecosystem Participation
The key to resolving these conflicts lies in transforming community members’ mindset. Moving beyond the tendency to join an ecosystem solely for airdrop farming, participants must embrace a more active role in the growth of the ecosystem. This shift entails an understanding that rewards are earned through active participation rather than passive speculation.
Metis: Decentralizing Sequencers through Revenue Sharing
An illustrative example of this transformative approach is Metis’ decision to decentralize its sequencer. Metis adopts a model of revenue sharing with all node operators, creating a system where token holders can stake their assets to earn revenue and mining rewards. This approach establishes a direct correlation between community participation, staking to secure the network, and the overall value of the Metis network.
Ecosystem Growth and Stakeholder Benefits
The beauty of this model is its self-reinforcing nature. More active nodes and increased community participation lead to higher levels of staking, enhancing the network’s security. As the Metis ecosystem expands, attracting more dApps and builders, the overall value of the network grows. Consequently, all stakeholders, whether short-term or long-term, benefit from the prosperity of the ecosystem.
Aligned Interests: A Prerequisite for Sustainable Development
Stage 2 focuses on aligning the interests of all parties involved in the ecosystem. By incentivizing active participation and contribution over passive speculation, blockchain projects can foster a community that is genuinely invested in the long-term success of the network. The shift from short-term gains to a collective vision of sustained growth ensures that the interests of all stakeholders are harmonized, creating a foundation for sustainable development.
Revenue sharing is not just a mechanism for distributing rewards; it is a transformative force that reshapes community dynamics and aligns the interests of diverse stakeholders. As exemplified by Metis, this approach sets the stage for a decentralized ecosystem where every participant is not just a beneficiary but an active contributor to the shared success of the project.
Stage 2 Tldr;
- Objective: Align the interests of short-term token holders and long-term builders.
- Key Focus: Introduce revenue-sharing mechanisms to incentivize active community participation.
- Approach: Shift the community mindset from short-term gains to active participation in ecosystem growth, exemplified by models like Metis, where revenue-sharing encourages collaboration and contribution.
Stage 3: Full Governance - Navigating Complexities with Dual-Layered Governance
The end goal in this whole journey is to establish a comprehensive governance structure that harmonizes the interests of the broader community, small token holders, and key stakeholders. While token amount-based voting power can risk being dominated by large holders, a more nuanced approach is required. The solution lies in drawing inspiration from modern political structures, to create a dual-layered governance system that ensures inclusivity and balances the influence of various stakeholders.
Addressing the Giant Whale Conundrum
The challenge at this stage is twofold: empowering small token holders to impact ecosystem decisions, and preventing the undue influence of huge token holders. A traditional one-layered governance structure, solely based on token amounts, might inadvertently favor the whales, overshadowing the voices of smaller contributors and community members.
The Dual-Layered Governance Model at Metis: Commons and Eco Nodes
Metis’ dual-layered governance model comprises Commons and Eco Nodes. The Commons, akin to a decentralized autonomous organization (DAO), is where every community member can create, join, and form interest groups. Commons work like the House in most Western political structures. Within Commons, small token holders pool their voting power, staking collectively into the governance platform, thereby amplifying their influence. This collective power allows smaller token holders to have a more substantial say in decision-making processes, counterbalancing the influence of giant whales.
The Commons as the First Layer of Governance: A Democratic Forum
Within the Commons, members can submit proposals, engage in debates, and collectively decide on matters that impact the ecosystem. This dynamic and inclusive space ensures that even small token holders can actively participate and contribute to the governance of the project. The proposals approved by the Commons then proceed to the second layer of governance.
The Eco Nodes as the Second Layer: Guardians of Long-Term Interests
The Eco Nodes form the upper layer of governance; they consist of core builders, contributors, and stakeholders deeply invested in the long-term success and growth of the ecosystem. The Eco Nodes work like the Senate in most Western political structures. Unlike the Commons, Eco Nodes hold a dual responsibility – validating proposals and taking decisive action. Their voting power is not solely determined by token amounts; rather, it is intricately adjusted based on Reputation Power. Reputation Power is earned through past contributions, creating a more meritocratic system.
Striking a Balance and Ensuring Accountability
The dual-layered governance model maintains a delicate balance by enabling small token holders to collectively influence decisions, while the Eco Nodes act as gatekeepers, scrutinizing proposals for rationality and long-term viability. The system is designed to be adaptable, allowing Commons to grow into Eco Nodes when certain criteria are met, while Eco Nodes can be subject to slashing in case of malicious behavior. This checks-and-balances approach ensures accountability and promotes a dynamic and responsive governance structure.
By leveraging the power of collective influence within Commons and incorporating the wisdom and experience of Eco Nodes, Metis aims to ensure a fair and transparent representation of all stakeholders. This innovative governance structure shows a commitment to true decentralization and community empowerment.
Stage 3 Tldr;
- Objective: Build the right structure for different types of stakeholders.
- Key Focus: Create a dual-layered governance model to balance the influence of various stakeholders, including small token holders and key contributors.
- Approach: Establish a Commons layer for community engagement and proposal approval, and an Eco Nodes layer for validation and decision-making, ensuring a fair and accountable governance structure.
Summary
The time has come to move from general discussion of milestone scaling to concrete, unique steps on the path to decentralization. Becoming the first Optimistic Rollup to decentralize its sequencer and share the revenue is one such step. Another is a dual-layered governance structure that aligns the interests of a blockchain project’s core team with that of its token holder community.
By following steps like these, we can navigate the seemingly conflicting goals of decentralization and growth harmoniously. I can’t wait to see the fresh ideas that other blockchain projects put forth on their own journey.