Motivation
Multiple similar but different approaches are considered for Payload Chunking. The goal of this post is to explain differences, describe trade-offs and analyze how they interact with other EIPs.
Problem
We can model block propagation and execution on Ethereum with the following chart:
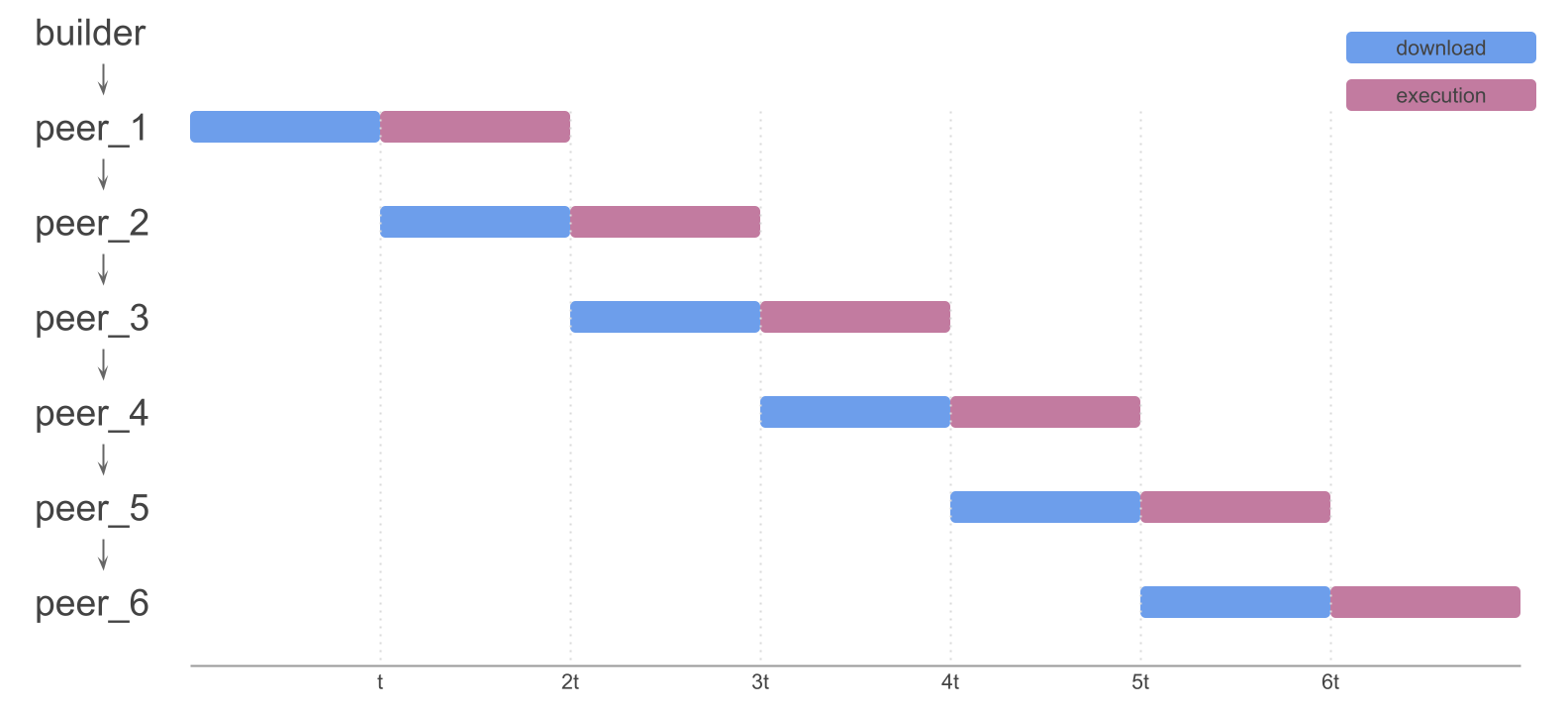
The main idea behind Payload Chunking is to split blocks into smaller chunks and propagate them separately over the network. In the simplest design, each node would have to download and merge all chunks before it can execute the block. For the rest of this article, we will refer to this model as Simple Chunking:
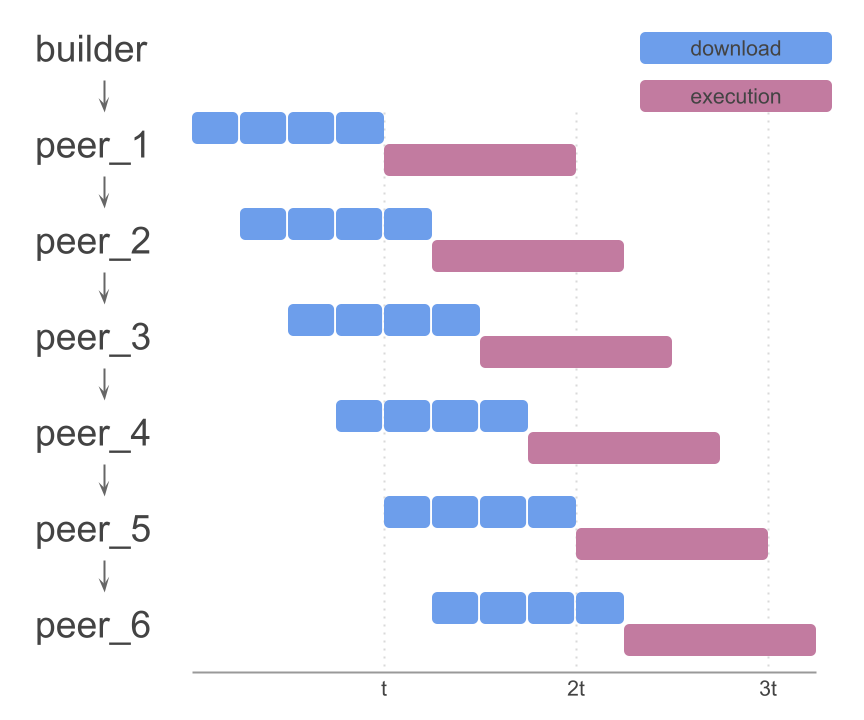
If we can also execute chunks as they arrive, we can parallelize block downloading and execution, which would bring us to this model:
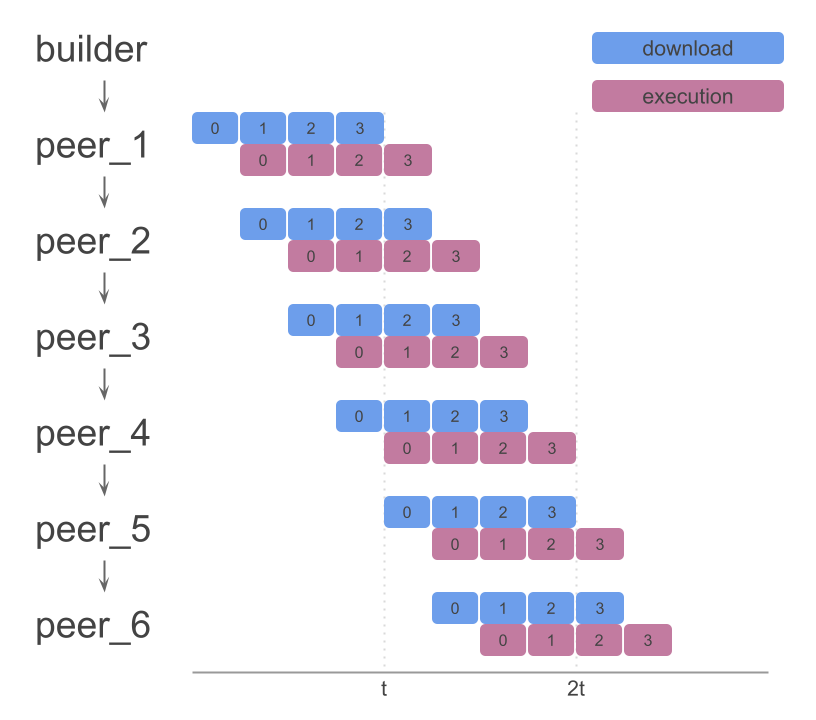
Chunks could arrive in any order. Natural order provided for simplicity.
Benefits
We identify two improvements that this brings us.
Parallel Propagation
Being able to propagate each chunk as it arrives, makes the entire block propagation faster. Smaller chunks and bigger network (more hops to reach all peers) increases the effectiveness of chunking (see analysis below).
The Simple Chunking model is just this. Several proposals already dive into this design, e.g. Block in Blobs (EIP-8142), using RLNC (link).
Parallel Download and Execution
Executing chunks independently reduces the total time spent between receiving first bits of block’s data and verifying the block.
It’s worth highlighting that in the best case this gives us a speedup by factor of 2 (i.e. when download time = execution time). In other cases, speedup is smaller because download / execution alone takes more than 50% of total time.
Since designs that only provide the first benefit (parallel propagation) already exist, this article will mostly focus on designs that allow both.
The protocol changes
Assuming inclusion of ePBS and BAL proposals (scheduled for Glamsterdam), we can make some assumptions and consider some concrete payload chunking implementations.
Firstly, we observe that transactions and BAL represent that majority of data that is propagated over the network. The simplest design for payload chunking would be to remove them from ExecutionPayloadEnvelope (see ePBS EIP). The ExecutionPayloadEnvelope will instead contain the commitment to chunks, which are propagated separately. Each chunk would contain only part of transaction / BAL data.
This opens some design questions.
Chunkifying Block Access List
The BAL is on average smaller in size than transactions, but in the worst case, it can be bigger (e.g. a small number of transactions that are reading from / writing to many storage slots). Chunkifying BAL seems like a logical approach, but we have to consider some things.
BAL is what allows us to execute chunks independently even if they come out of order. If we want to preserve that property, we have to split it into Chunk Access Lists (aka CALs). We would have to design CAL in one of the following ways:
Dependent CALs
We can make CALs from previous chunks required when executing the current chunk. Meaning, in order to execute chunk i, we would need chunk_i (txs from chunk i), and all CAL_0, CAL_1, …, CAL_i.
This causes some fields to be duplicated across CALs (in comparison to BAL):
- addresses and storage slots that are modified across multiple chunks
- storage slots that are read in earlier and modified in later chunks
Because CAL_i is useful even without chunk_i (state pre-fetching, executing later chunks), these objects should propagate separately.
Independent CALs
The other approach is to make CAL independent, i.e. each CAL_i would contain all required data in order to execute chunk_i.
This increases data duplication even further. In comparison to previous approach, we would also have:
- all storage slots that are accessed in earlier chunks
- if they were modified, we have to include latest modification as well
With this design, we can send CAL and chunk transactions together, reducing complexity. But it is not compatible with non-semantic chunking (see below).
Making CALs dependent is more pragmatic, as data duplication is significantly smaller in the worst case. The downside is that early CALs are needed in order to execute any of the later chunks (i.e. CAL_0 is required in order to execute any chunk, causing delays if it is received late).
Semantic vs Non-semantic chunking
When deciding how to chunk transactions, two approaches naturally emerge.
Non-semantic chunking
By non-semantic chunking we consider the process where all transactions are encoded into one byte array, which is then split into even sizes. This ensures that each chunk propagates through the network in similar time.
However, if we want to be able to execute chunks as they arrive, we would have to propagate some extra information about encoding (e.g. in which chunk and at what index each transaction starts). This complicates design (some tx would span over multiple chunks, less options for BAL chunking) and extra data can be non-negligible as we scale gas limit up and reduce intrinsic tx gas cost (EIP-2780).
Most Simple Chunking designs are a form of non-semantic chunking, without the benefit of executing chunks independently. For example, Block-in-Blobs (aka BiB) encodes BAL and transactions into single byte array, that is then split into predefined sizes and converted into Blobs. The downside of BiB is that since we can’t enable DAS (data availability sampling) until we switch to zkEVM, every node has to download all chunks/blobs. In current design where we use the same encoding as for regular blobs, we double the size of data that needs to be propagated, without many benefits. Builders would also have to calculate KZG commitments and proofs during critical slot time.
Semantic chunking
One of the downsides of non-semantic chunking is that we have no guarantees that chunk execution would be similar across chunks (e.g. one chunk can contain all execution heavy transactions).
To create more uniform distribution of execution complexity across chunks, we can split transactions and create “mini-blocks” in the following way:
- each chunk has at least one transaction
- transactions are not split across chunks
- used gas in a chunk is at most 16.8 Mgas (picked based on EIP-7825, can be adjusted)
- we can also ensure that average chunk is not too small (e.g. two consecutive chunks that together have less than 16.8 Mgas are not allowed)
Since transaction size affects used gas, we are also limiting and balancing chunk’s byte size, making propagation also somewhat uniformly distributed.
A more natural division of transactions into chunks makes chunk execution simpler in comparison to non-semantic chunking. These chunks can be considered mini-blocks, with their own chunk header (with chunk specific fields, e.g. chunk_gas_used, pre_chunk_tx_count…), but without some complexity that blocks have (no need to calculate state root, send attestations, etc.).
See EIP-8101 for detailed spec of this design. Check here for proof of concept implementation.
Related approaches from other ecosystems
Other ecosystems introduced similar improvements.
Solana splits data into “shreds” and uses Turbine protocol to propagate it faster. While data splitting is analog to non-semantic chunking, the Turbine innovated on networking layer to improve propagation speed even further.
Base and few other OP Stack networks use Flashblocks. Instead of propagating blocks every 2 seconds, Base produces and propagates sub-blocks every 200 ms. These sub-blocks are later combined into a single block. This approach is similar to semantic chunking, but it allows Builders to create sub-blocks before finalizing the block. This type of “Streaming Semantic Chunking” wouldn’t be possible on the Ethereum mainnet with current design of ePBS. The ePBS design would have to change to Slot Auction model, which has well documented trade-offs.
Scaling L1
The main benefit of Payload Chunking is that it allows us to scale L1. Shorter propagation and execution time allows us to either increase block size (i.e. GasLimit), reduce slot time, or combination of those.
These improvements become less relevant once we have zkEVM and BiB, so we have to analyze the potential scaling factor and consider whether it’s worth doing it (the exact timeline of zkEVM plays a role in this discussion, but it will be left out of this article).
In order to safely scale L1, we have to consider the worst case scenario and the benefits that it gives us. Let’s analyze each improvement.
Parallel download and execution
As observed earlier, independent chunk execution allows us to scale at most by a factor of 2. That is the best case estimate, which is far from realistic.
If we take a deeper look and consider the worst case scenario, the non-semantic chunking doesn’t provide almost any guaranteed improvement in this regard. The worst case would be the block in which most of the execution is happening in one chunk that clients happen to receive the last. In that case, the diagram from the start would look something like this
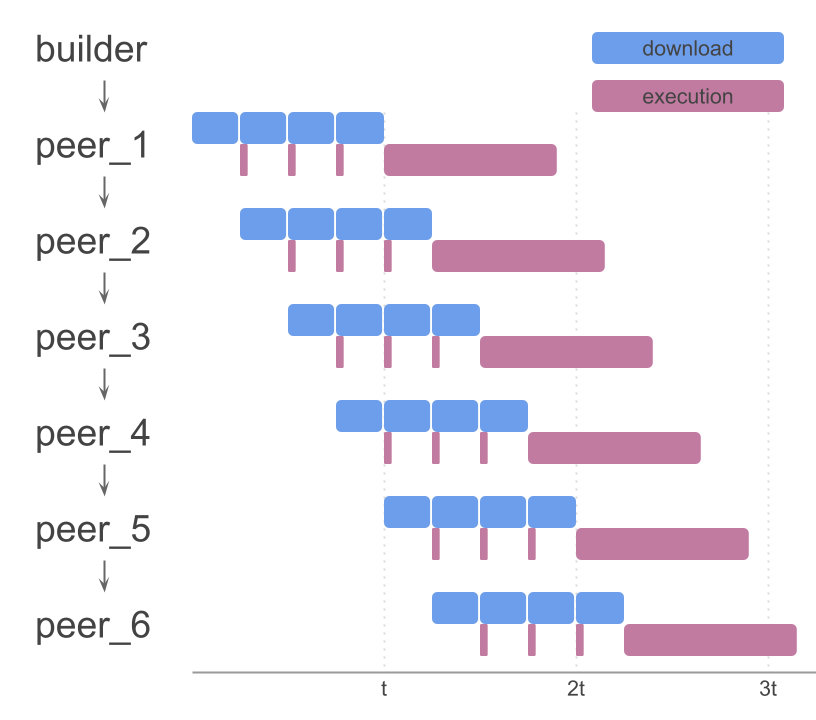
On the first look, semantic chunking should solve this problem (since it limits used gas per chunk), but its effectiveness depends on parameters. BAL already allows transactions to be executed in parallel. So if a block is full of transactions that use maximum gas (16.8M) and are execution heavy, we don’t actually scale that much.
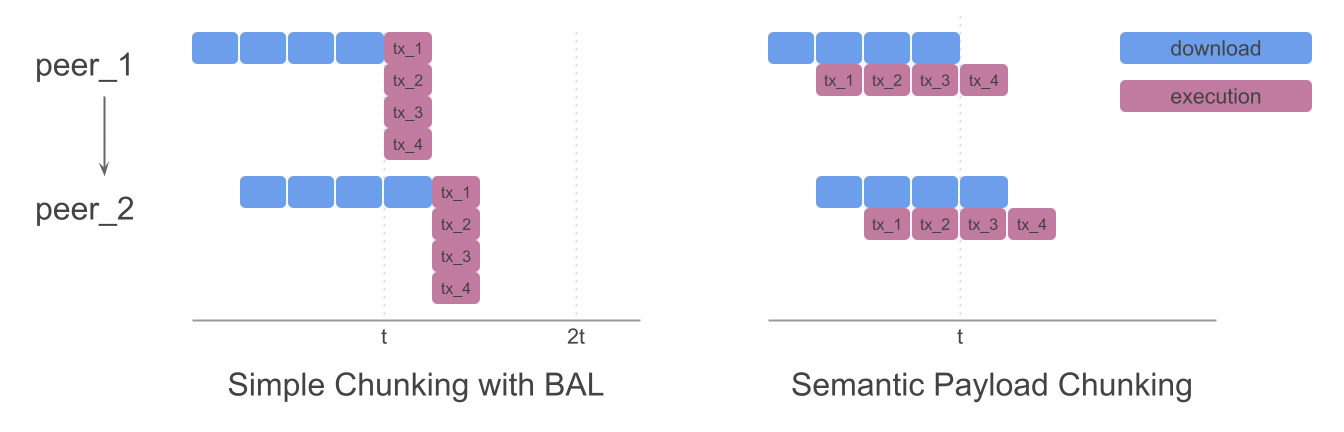
In the diagram above, we have a block with only 4 transactions that use the entire block’s GasLimit. If we compare Simple chunking with BAL (where transactions execute in parallel) and Semantic chunking, we see that Semantic Chunking doesn’t provide any speed up. There will be some benefit as GasLimit increases (since we can’t parallelize all transactions), but it’s not going to be major.
It becomes obvious that in the worst case, the scaling factor is less than 2. It’s also hard to estimate how much it is as it depends on many parameters (GasLimit, number of cores used for parallel execution, etc.).
With zkEVM on the way, chunk execution becomes even less valuable in the future.
Parallel propagation
Parallel propagation guarantees scaling, regardless of the approach. The best case is when chunks are the same size, which is what non-semantic chunking (including many Simple Chunking designs) gives us by default. Semantic chunking doesn’t provide any guarantees on this, but because we have a limit on usedGas per chunk, we indirectly have a limit on chunk size as well.
Without chunking, if sending the entire block between two peers takes t seconds, then the peer that receives block after h hops will finish receiving block at time T_h = t*h. If block is split into N chunks, it will instead finish receiving block at T'_h = (h-1)*t/N + t = t*(h-1+N)/N. The scaling factor in that case would be T_h/T'_h = h*N/(h-1+N).
If we take that h=6 hops is needed to reach the majority of peers (estimated based on current size of the network), and blocks are split into N=10 chunks, we get the scaling factor of 4.
In most designs, we don’t have direct control over the number of chunks N. As block size grows (i.e. as GasLimit grows), we will naturally have more and more chunks. More chunks implies better scaling, but the relationship is not linear. We should also not forget that each chunk also carries some extra data with it (inclusion proof, signature) and requires some extra processing time (validation). This overhead can become impactful if there are too many very small chunks.
If we use Non-semantic or Simple Chunking, chunk size is a very flexible parameter that we can set based on benchmarks and other parameters (GasLimit, calldata pricing, etc.). We can also consider compatibility with BiB and other proposals.
Conclusions
When considering which approach is worth adding to the protocol, we have to consider potential benefits, complexity, and interaction with other planned improvements.
| Advantages | Disadvantages | |
|---|---|---|
| Simple Chunking | simple, efficient parallel propagation, compatible with future EIPs | no parallel download and execution |
| Non-semantic Chunking | efficient parallel propagation, compatible with future EIPs | complex design for parallel execution without guaranteed scaling |
| Semantic Chunking | medium complexity, efficient parallel execution | parallel execution scaling factor hard to calculate (likely small), not useful after zkEVM |
All explored designs provide parallel propagation, with similar effectiveness. Individual chunk execution, as explained above, doesn’t provide big or guaranteed scaling, but it increases complexity. If we remove this requirement, we also don’t have to split BAL into CALs, which simplifies design even further. Protocol also remains more aligned with future improvements, like BiB and zkEVM.
This leads to the conclusion that if we want to do any kind of payload chunking, it makes the most sense to do Simple Chunking. One approach would be to simply commit to the hash of each chunk. We can set the size of the chunk to be compatible with BiB, and later switch to BiB once we decide to enable DAS. We could also decide to go directly with BiB. The exact design is to be further analyzed and is outside of the scope of this article.