Hi @0xTraub ,
great questions, let me try and answer them:
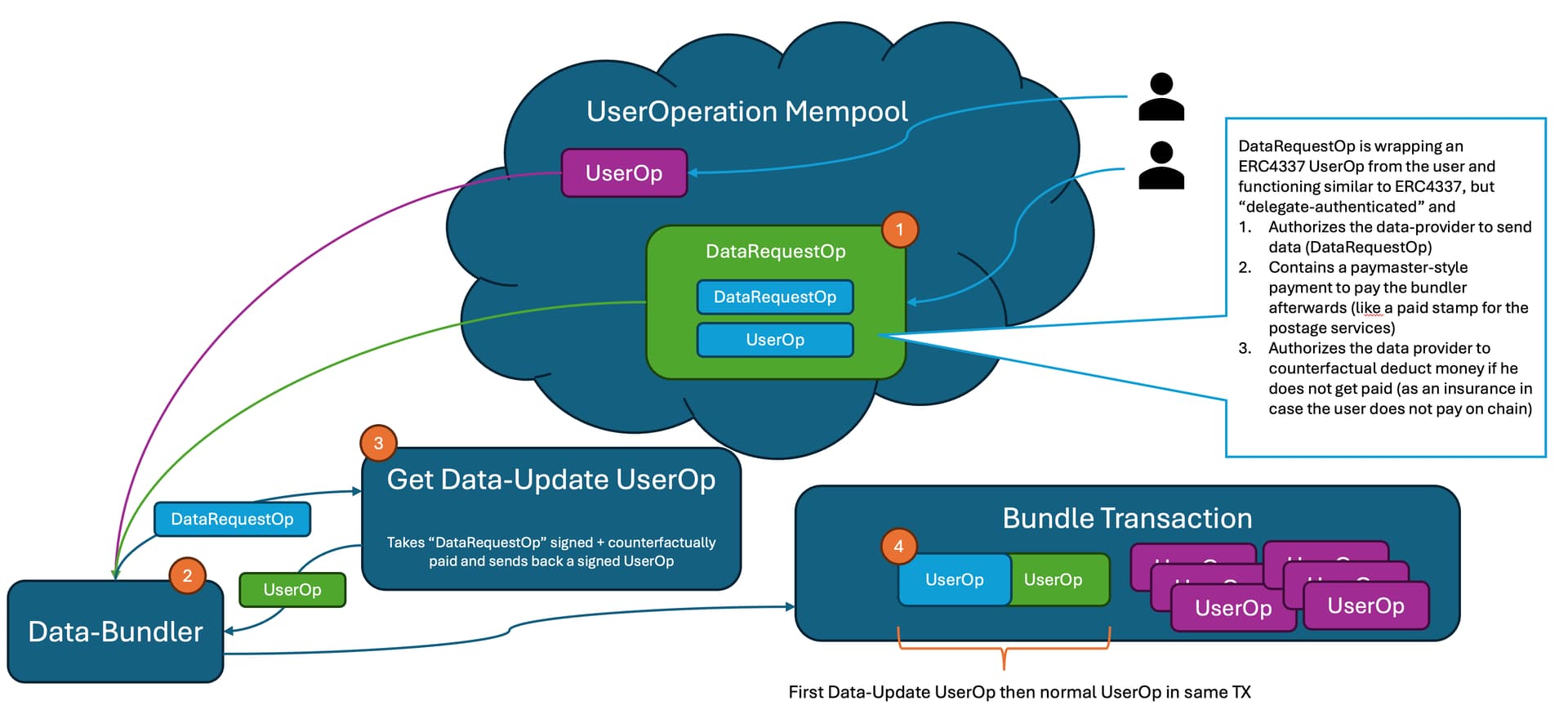
Regarding 1. 2.) We’re actually wrapping the UserOp into another type of operation, a DataRequestOp. So, the bundler prototype we created [1] is actually an extension to the current bundler. It takes in a DataRequestOp, runs through the wrapped UserOp to ensure the bundler gets paid for the Data provision (and of course also for the normal bundler operation), then injects another UserOp towards the Entrypoint and sends out both within the same transaction. The UserOp itself should error out if the timestamp in the oracle contract - when reading the data - is anything but the block.timestamp. It’s up to the user to allow a certain wiggle room here, but since both UserOps (one for updating the oracle data and another that actually calls then whatever needs to be called from the UserOp) is in the same TX, the block timestamp should be the same, so it would make sense to restrict it to that. So, in short, its up to the user.
Regarding 4. and 5.) Before answering that question, I want to take a step back here. The problem with a lot of data, but especially financial data, is licensing and data rights. We’re battling quite a bit for our own data feeds to have display rights for our charts and our users (at Morpher, the company I work for). Standard display right licenses don’t even usually include redistribution rights. Getting something like a UDP or a consolidated SIP feed with display and redistribution rights does not come cheap. And the negotiation and setup to get access to this data isn’t straight forward neither, so the barrier of entry is quite high. Another problem with current Push oracles is the delay, I know before the oracle will update - for a great enough certainty - the price of the update and when the update will be. Pull Oracles usually have a lower delay (however, I did get a measurable delay in seconds, long enough that something like high leverage perp markets with the feeds is unfeasible), but then its usually just the attestation service you pay for, not for the data, so you get the data before you actually paid anything at all, it becomes a hard sell to data vendors. E.g. You can hook into Pyth network today and get the price for any feed, if you want the attestation it will cost you something (AFAIK 1 wei currently, subject to change in a future governance if I am not mistaken). One thing that our architecture solves is that someone in possession of data can be certain that a payment happened before the data is distributed. Looking at large exchanges or large data vendors, it opens up a huge new market opportunity. Looking at 2nd level distributors, its easy to add in another stream of income through providing data if you want. So, that’s kind-of the angle we’re coming from with the solution, mostly a rights/delay fix to get high quality data on-chain, so that something like delay based arbitrage becomes impossible. Piggy backing off another userOp is both possible and impossible, we haven’t decided on an architecture yet. In the current incarnation of the prototype its impossible, because the data is written for a target contract only into the oracle contract, so reading out the data is only possible for the contract that requested the data in the first place. Changing this is trivial, from an architecture point of view. I think its something we decide on once we have data vendors onboard for a trial phase to run a bundler including something I would call somehow authoritative data provider - where users get the data directly from the source ideally.
Which brings me to 3) The trust problem. And that is something we’re currently looking into and something we’re actively researching. There are a few ideas floating around. One is, you have different data providers with different lists of data which have a certain reputation for providing data. That is then either something like a (on-chain, decentralized?) reputation dashboard, or registry of some sort, where you say “I want the current price of Nasdaq:AAPL” and it spits out a list of urls for bundlers who have a stake/proven track record/reputation score/price/… Another idea is to make it an on-chain aggregate of signatures, something like a BLS aggregation signature scheme where a data point is requested with at least X off-chain attestations from Y data providers and it only passes the oracle update if all the signatures are valid. Problem here is the delay, which we would like to keep well under 1 second at all times.
Lots of text, I still hope I could answer a few things. We’re currently working on a demo that will probably make it all a bit more accessible - always better to have something to play around with…
Thomas
[1] GitHub - Morpher-io/dd-voltaire: Modular and lighting-fast Python Bundler for Ethereum EIP-4337 Account Abstraction, modded to support oracle data injection and the new endpoint would be this one: dd-voltaire/voltaire_bundler/rpc/rpc_http_server.py at dc57add61bffaa0e9532aa494dbb5952df474e00 · Morpher-io/dd-voltaire · GitHub