Edit: The “deferred ordering” array does not have to be deferred. Nodes can keep meta-data about length at each trie branch. Thus they always know the ID (0 to N) of any key. But use of key IDs have to be done where the array is not modified anymore, or there will be contention at the length meta data. Contracts who want to use the array in parallel can manage this. This is similar to how a mapping in Go has a “non-deterministic ordering”. The data type I need would be like an Ethereum mapping with a built-in ordering that is deterministic only if the mapping does not change, and where each key can get its “sequence number” attribute, and this requires the mapping/array is its own trie, which benefits from the storage architecture described below.
Edit: The per-storage slot dependency trie described here is not a good idea. Per-transaction, like Polygon uses, much better. Many here probably know how those work, seems to be block producer uses similar to “mutex” at storage slots, any shard involved in holding a mutex or waiting for it track all who is holding/waiting, and if someone tries to take a mutex held by someone who is at same time waiting for them, they discover that deadlock instantly and a winner can be chosen, either the one who discovered the conflict aborts or it is by txID. But the flat storage trie with “storage objects” is still a valid idea since it allows “delayed ordering” array that can be manipulated in parallel. Current Ethereum arrays have a length storage slot that is always sequential (cannot be parallelized). My “video pseudonym event” needs to register 10 billion people in 2 weeks each period… And the fact that sharding has to be “internal” to validator is also valid.
My https://doc.bitpeople.org will need upwards 100k transactions per second with global consensus, so I am interested in the next big step after Ethereum in 2014: scaling global consensus (not “layer 2” or an inter-blockchain bridge system like Polkadot or other things without global consensus, but scaling the “global singleton”, the “world computer”. I have identified the scalability bottleneck being the game theory for validator attestation (it is based on trust, yet many treat it as if it were already trustless, while it may in theory be possible to make it trustless with “encrypted computation that cannot lie” or similar, it is until that trust-based and thus scaling has to be “internal” to validator, but can use social delegation and not be geographically centralized).
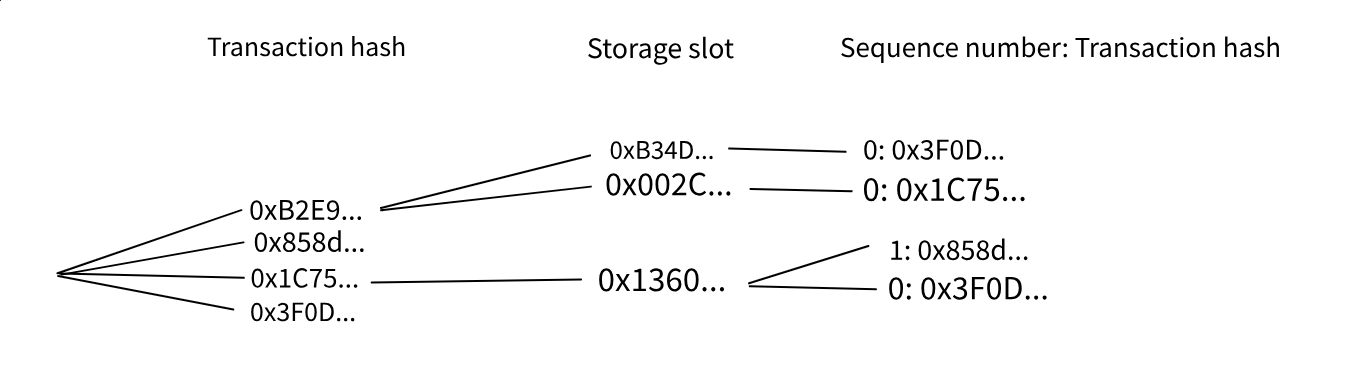
To allow transactions to be done in parallel, first it seems good to use a flat storage trie (that idea is upwards 10 years old from the experts, right?). And, I would do it as each key being a “storage object”, structured data, that each contains a nested trie. A contract is such a “storage object” as well, but a mapping or array or struct would be too (then the key contains the contract address). The leaves of the nested trie can contain pointers (when in same contract) to other “storage objects”, nested mappings or such is thus nesting “storage objects” as pointers. It seems like this can allow any data type, but you can shard by key most significant bits for any “storage object” (and internally, a node shard however it wants, no shards, 16 shards, 1024 shards, etc).
It seems the transaction trie in a block could be replaced with a transaction dependency trie with a storage slot contention granularity. Some projects like Solana has something similar but it is per transaction, but what is sharded is typically the storage trie so the parallelization is at storage slots. This trie manages contention shard-to-shard, not centralized. If shard #5 is processing a transaction (within its tx hash range) that is in contention with shard #23 at a certain storage slot (shard #23 is processing that tx hash range), they manage it in between themselves. Or, more likely, the shard responsible for the storage slot itself serves to coordinate (shard #5 asks it to tell him when the dependency has been run). This then acts as an implicit mutex on storage slot I/O. Contracts are still assumed to use mutexes internally to control the order of I/O, but by default everything is allowed to be parallel. You then run all transactions in parallel, and the “implicit mutexing” solves the order (as default, and can do optimization on top depending on need).
What about ETH transfers? I have assumed maybe it is enough to just use “implicit mutex” there too, such that if a transfer is requested that is not payable yet, the processing pauses while other transactions continue, until the order of things should find the same way the block producer found. But I am not certain this will always work (if anyone sees it would or would not, feel free to point that out). But there is ways to solve ETH transfers regardless. The “this.balance” is problematic since balance is not a storage slot, it can maybe be removed and contracts are assumed to track balances manually if they want too (or treat balance ass storage slot for anything, but I dislike that).