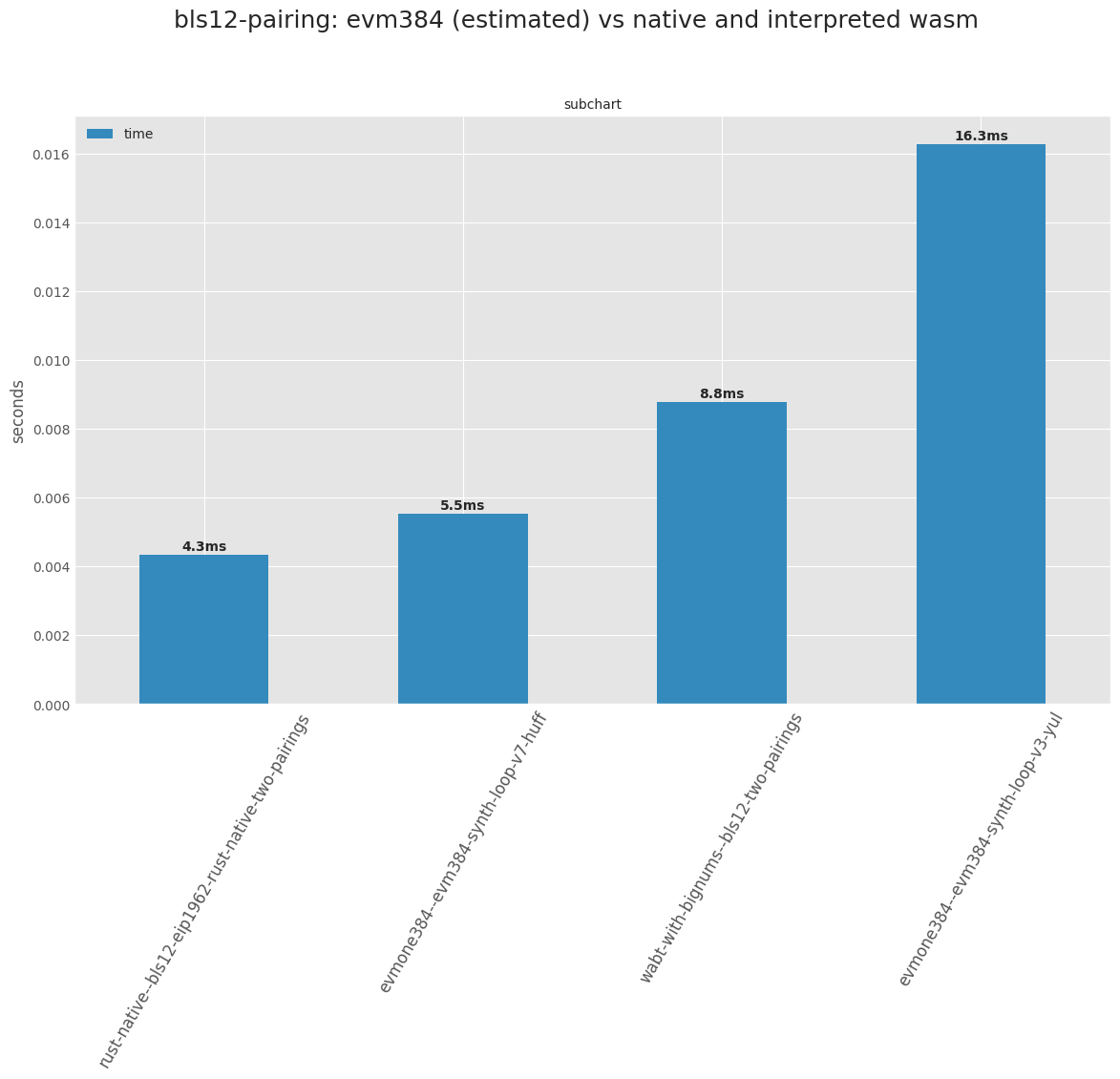
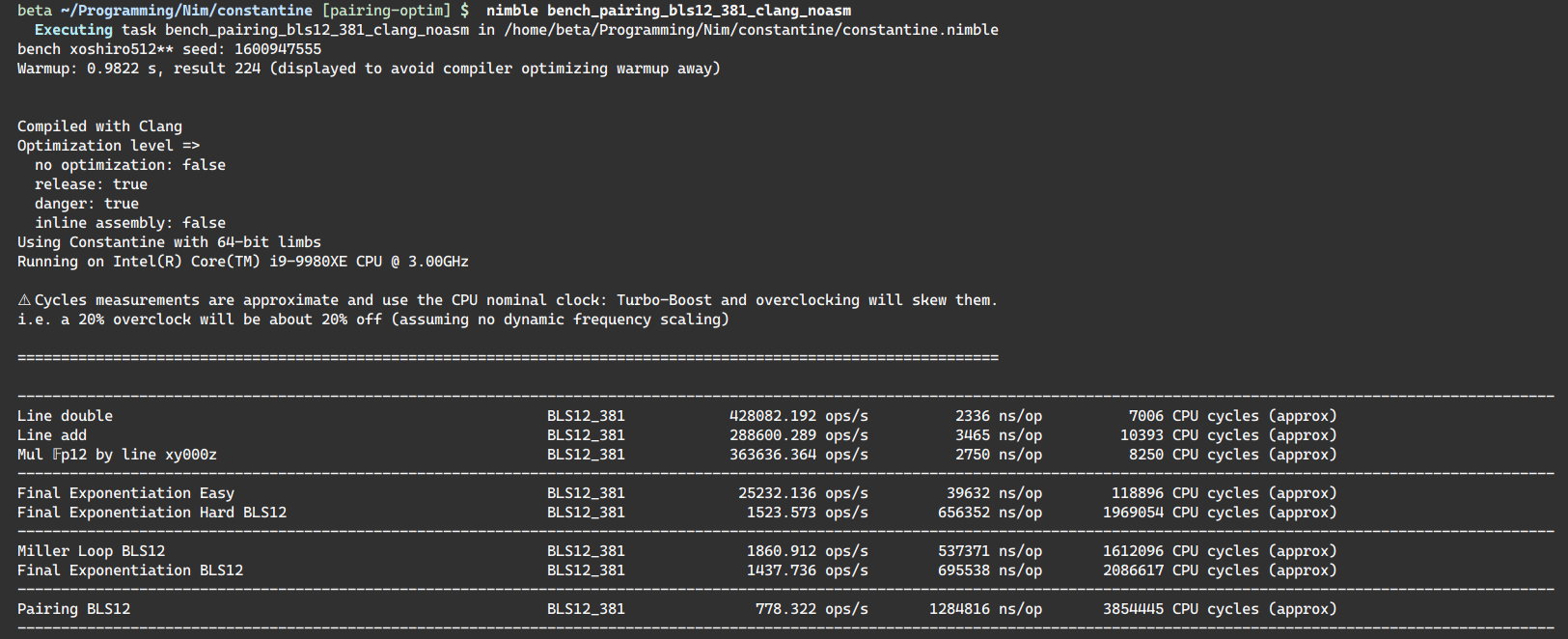
My current benchmarks are:
Clang + Assembly
Clang without Assembly (30% slowdown)
GCC without Assembly (100% slowdown)
CPU has a 3.0GHz nominal clock but is overclocked at 4.1GHz all core turbo and I have a warmup to ensure I’m running at 4.1GHz before bench. You need to scale the time/clock/throughput by 4.1/3 for comparison.
The discrepancy between Clang and GCC in no assembly is because GCC is just bad at bigints.
Note that my numbers are for a single pairing, multi-pairing is not implemented yet. N-way pairing would be N * Miller-loop + 1 final exponentiation.
So using Clang without assembly would take about 1.8ms as it stands with/without the following optimizations:
- no extra bits, use full word bitwidth (which lead to carries which GCC doesn’t properly deal with without assembly)
- no assembly
- CIOS or FIPS multiplication (those are generics to all fields like the separate mul and reduce, called SOS)
- no addition chain in Miller loop
- addition chain in final exponentiation by x
- addition chain for inversion
- Towering is Fp → Fp2 → Fp4 → Fp12 (mostly because I had trouble debugging line functions with Fp6 towering)
- Sparse Fp12 x line multiplication
- no lazy reduction (didn’t work for me, will revisit)
- projective coordinates with constant-time formulae
- no fused line evaluation and elliptic addition/doubling
- mixed addition in Miller loop
BLST on my machine is Benchmarks · Issue #1 · status-im/nim-blst · GitHub
Pairing (Miller loop + Final Exponentiation) 1315.289 ops/s 760289 ns/op 2280892 cycles
Pairing (Miller loop + Final Exponentiation) MULX/ADOX/ADCX 1639.054 ops/s 610108 ns/op 1830347 cycles
MCL has a recent PR that fixed inversion and takes a similar amount of time 1.9 Mcycles so about 630 ns/op.
Note: scaling factor between my overclock and the nominal clock.
I expect my biggest contributor to my 20% diff with BLST and MCL is that they are using the Fp6 line evaluation formulas that fused line evaluation and point doubling/addition. They don’t exist in straight line code for Fp4 so I didn’t get to implement them yet (though I’ll likely switch back to Fp6).
So in conclusion from @shamatar’s post and mine I think 2ms double-pairing for native code is a reasonable baseline to compare the EVM against. Also many of those optimizations are generic and portable to the EVM except addition chains which like @shamatar mentions doesn’t save that much for BLS12-381 (a couple thousand cycles out of 2 millions)
Additionally the code for Zexe supports all required curves and has underwent significant optimizations, including assembly code generation and can be use for benchmarks or also as an extra implementation to test against: Results from benchmarking pairing libraries · Issue #80 · arkworks-rs/algebra · GitHub