Events Should Be Free
Introduction
Permissionless access to data is one crucial aspect of social consensus. The motto of blockchains, “Verify, don’t trust!” tells you exactly that. DeFi apps today are not based on faith; they prevail because anyone can validate them. At any point in time, you can evaluate their trust assumptions, see how much liquidity, collateral, and debt they have, and make them accountable.
“Ethereum is the world’s settlement layer not because it has the largest economic security, but because it’s the largest verifiable blockchain”
https://twitter.com/gluk64/status/1770910189572501954.
Events, or Logs, are the primary data source of Ethereum (and other EVM chains). Most analytics websites, Dune dashboards, and crypto reports are created using events as the most basic data primitive. Events are then transformed, combined, and grouped to create a metric in a chart or a table. Events are the building block of crypto data but are at risk of being undermined. To explain why this is happening, we need a good understanding of events’ inner workings.
How do events work?
Skip this part if you have a good understanding of how events work.
Events or Logs in EVMs are similar to code logs in any language. It’s one line in the code that, when the execution stumbles at it, will write the desired execution information in a ledger. A log record is used to surface information about a smart contract execution, like a token transfer or a change of ownership, so that it can be easily retrieved.
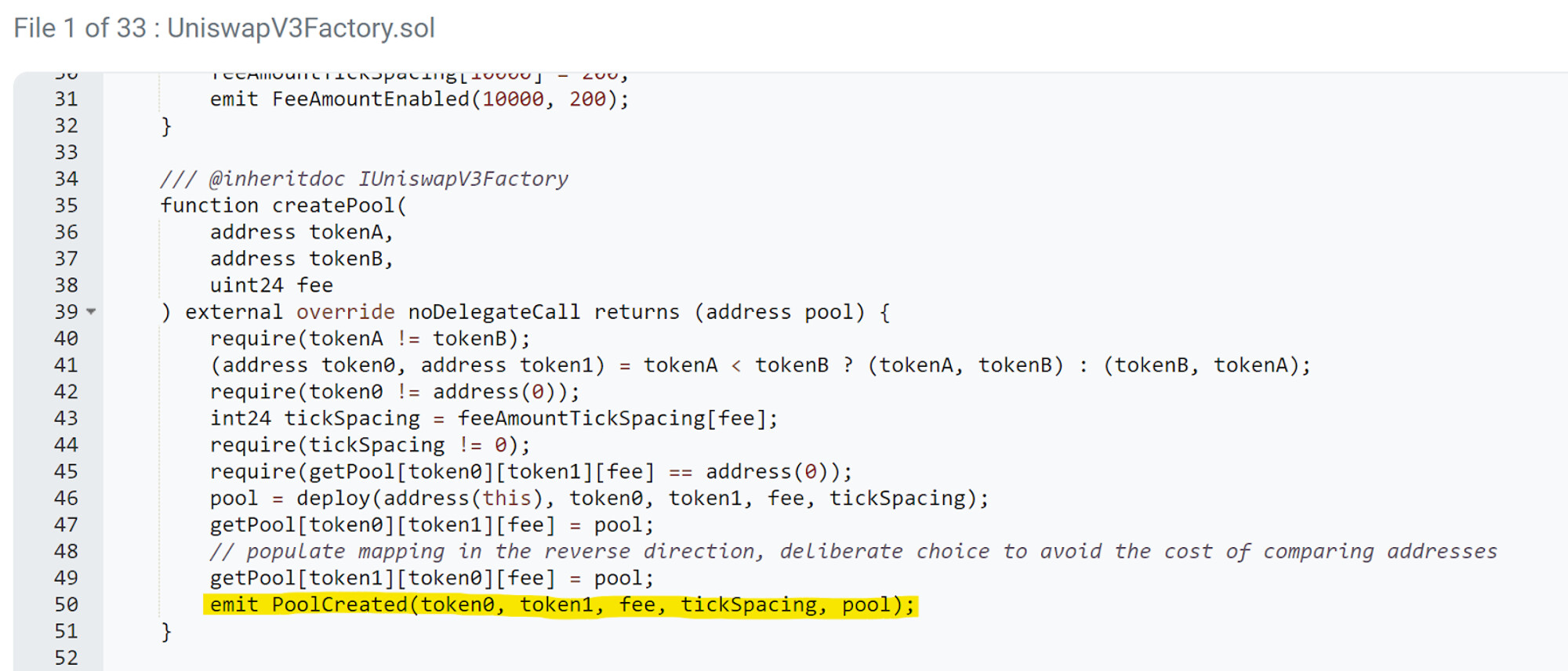
Example of the UniswapV3Factory contract code, which will emit the PoolCreated Event every time a pool is created. You can calculate how many pools Uniswap has by counting how many PoolCreated Events were emitted. Source: Uniswap V3: Factory | Address: 0x1f98431c...6ea31f984 | Etherscan
In Ethereum, event outputs are written in the transaction receipts, together with some other information about the transaction outcome. Every node in the blockchain stores transaction receipts in the blocks. The back-end of analytics websites and data providers can then request the transaction receipts from any node and use this information to create the desired metrics.
The solidity code is not what is stored in the blockchain. The function emit is compiled to a LOG opcode, and the node implementation dictates the contract execution flow when the LOG opcode is called. A block also includes some extra metadata to improve efficiency while querying receipts.
In conclusion, retrieving data from events is much simpler than sourcing it from the state trie (Ethereum memory) while also allowing the retrieval of historical data, a much more complex task when using other sources since the state trie is constantly updated; you usually only have access to its latest state.
This blog post from MyCrypto provides an excellent, in-depth explanation of events:
https://medium.com/mycrypto/understanding-event-logs-on-the-ethereum-blockchain-f4ae7ba50378
The issue
Events come at a cost. Each event incurs a minimum of 375 gas, with an additional 375 for each topic (32 bytes of indexed data) and eight gas for each byte in data (unindexed data). For instance, a Transfer event adds 1756 gas to the operation, while the entire transfer operation costs between 40,000 and 60,000 gas. The event emission cost is paid by the user when making a transaction.
Because Ethereum is now expensive, this cost factor has led to discussions about making L1 transactions more affordable. Even though events represent a small fraction of a transaction cost, developers are already considering their removal, so their users don’t bear this cost. This creates a massive issue for data providers, leading them to centralized alternatives.
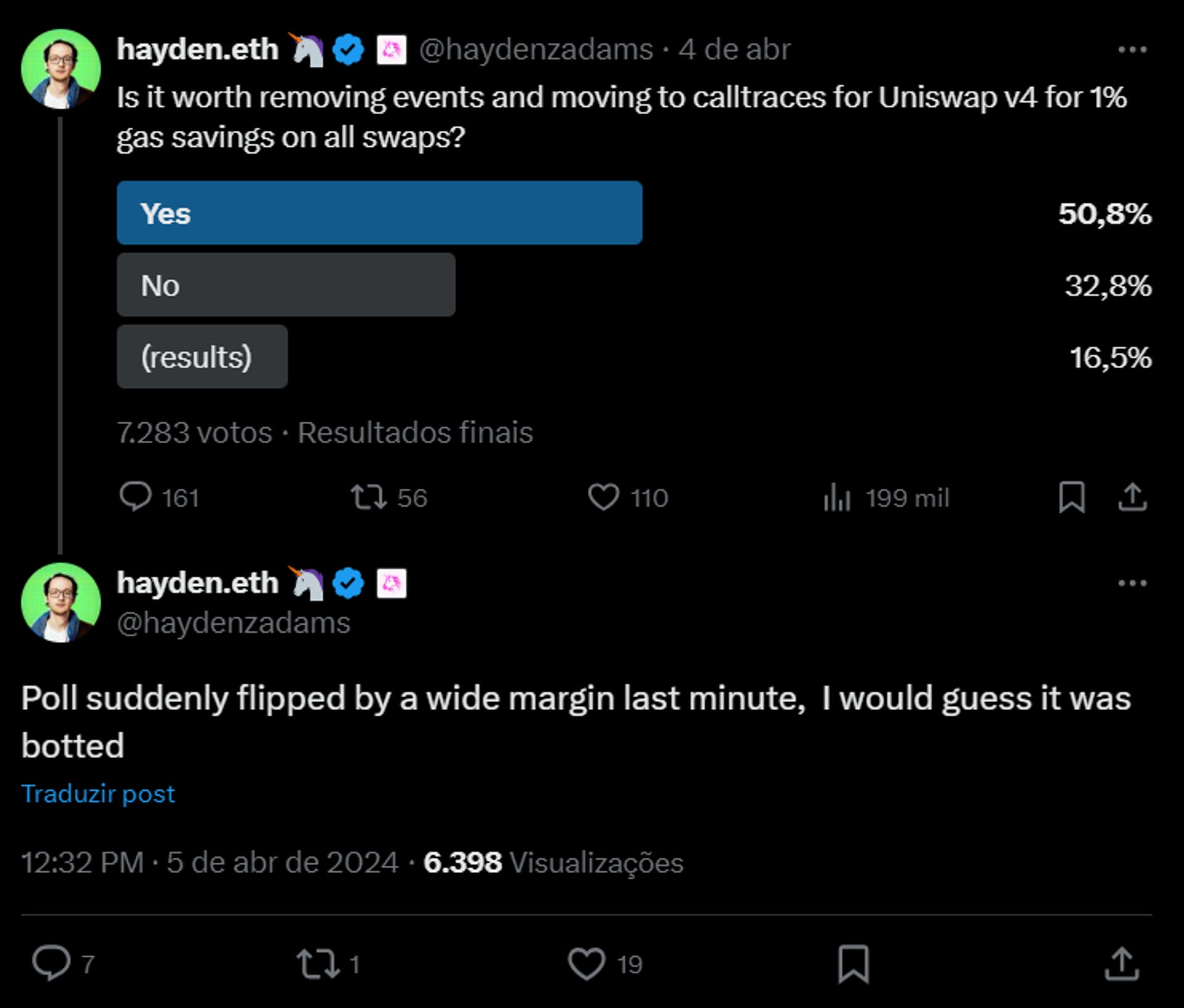
Heyden Adams, CEO of Uniswap, is polling about event removal in the next version of Uniswap. Even though the X poll is not a trustworthy source of truth, the fact that they consider it is troublesome. Uniswap V4 without events could tip the bucket to centralized solutions. Source: https://twitter.com/haydenzadams/status/1775907308372922464
Events solve two different problems. The first is obvious: easy access to execution data. Events store extra information in the receipts, making this data much more accessible. However, a second, often neglected, issue events solve is data curation. Knowing what to store is a challenging task. The blockchain generates an abundance of data, which can become overwhelming and hinder the ability to extract meaningful insights. Data curation is more suitable for those developing the protocol and deeply understanding its inner workings. When devs remove the events, they push this task to everyone further down in the data manipulation process. This is critical.
Most alternatives to events are burdensome or rely on centralized data providers. Call traces, another outcome from transactions that are also decentralized, provide very limited access to execution data, and the actual state needs to be reconstructed from input parameters. This path is impractical, as any crypto data analyst who has ever tried it can attest, and it won’t be pursued given available centralized alternatives. Events can also be emulated by proprietary customized nodes that modify the deployed contracts and add fictitious events to the code. This approach requires centralized infrastructure to rewrite code, re-execute the blockchain, and deliver indexed events to consumers.
Potential Solutions
Events should be free. Even though end-users consume dashboards and charts, they shouldn’t bear the cost directly at each transaction. Events cost gas because every node needs to handle and store them in the receipts. Nodes would get bloated with useless events if they were free or much cheaper. We need to make log manipulation and storage optional. With free events, developers don’t need to remove them from their code, still maintaining the curation by protocol engineers and permanently written in the contract. Events are kept decentralized, although optional to anyone who wants to make use of them later.
How can we do it? It’s time for an open-source node implementation dedicated to data applications. The initial “data node” MVP can be a fork of current execution nodes with some extra functionalities to handle data. In its most straightforward configuration, it will be responsible for treating the current events that exist today. This solution not only addresses the issue of event costs but also provides a platform for developers to freely manage and store crypto data in a format more suitable to their needs.
The rationale is that if you’re a home-staker, you probably don’t care about storing events since you won’t do much with them and can run the existing node. Conversely, if you run a node to power some UI, you could care only about the events emitted by the protocol’s contracts in the UI. Lastly, if you’re a data provider, you care about most contracts and would store all; ultimately, this is part of your business anyway.
We would also need to modify the current execution nodes. One alternative is implementing new opcodes for fictional/free events (Mnemonic FLOG) and keeping the current LOG opcode. FLOG would be ignored entirely by regular nodes. Still, on a “data node”, it would act similarly to the regular LOG opcodes, adding their output to some data structure (maybe in the same receipts) and indexing the relevant fields. Solidity compilers must also introduce functions and syntax that would be compiled to the new opcode. This proposal does not affect already deployed contracts, which would still spend gas on transactions. Only new contracts using the new opcode would benefit. Furthermore, it allows the ability to code payable events when necessary (a swap can have a free event, but a set_new_fee function can pay for it, storing it at every node). Alternatively, we can repurpose the current LOG opcodes to be free and ignored by regular nodes and make new opcodes for payable events that would follow the current log implementation.
Other considerations must be made. Free events could be a potential vector for spammers’ contracts and others to abuse. Data consumers will require extra functionalities, like the ability only to track events from some contracts, some type of contracts ignore lists, or even some additional indexing. The “data node” team would be responsible for making design considerations providing the new customers of this node, data providers.
One last alternative is to have special comments in solidity for fictional events. It doesn’t require any node change and keeps the curation by protocol developers, but it has the drawback that comments are not compiled to opcodes and, thus, are not deployed at the blockchain. The “data node” would only be able to act on it if it has access to this contract solidity source code, also needing re-execution of the new compiled version of the contract with the free log. Also, there is no guarantee that events are the same, as there is no way to verify comments onchain.

Conclusion
Simply removing events from the code is a terrible decision. It pushes UI development and analytics to proprietary products and platforms, centralizing the data-provider supply chain. Existing alternatives to events, like traces, are limited, burdensome, and onerous. However, protocol developers are also correct in trying to remove costs from their users. The only way to fight this tragedy of the commons situation is for the community to step forward and advocate for open-source, decentralized solutions. The existing data providers could also step forward and sponsor this idea, as their business relies entirely on that.