Data Anchoring Tokens (DAT): Usage-Metered Revenue Distribution for AI Assets
The Data Anchoring Token (DAT) standard represents a paradigm shift in tokenizing AI assets by unifying three essential properties into a single token structure: ownership certificates, usage rights, and value share. Unlike general-purpose NFTs or fungible tokens, DAT is purpose-built for the dynamic, evolving world of decentralized AI through its class-based architecture, value-based metering system, and on-chain verifiability.
Token Architecture
Semi-Fungible Token Structure

Each DAT is a comprehensive primitive carrying multiple integrated components:
Core Identity
- id (uint256) - Unique token identifier for each specific AI asset
- name (string) - Human-readable token name
- description (string) - Detailed token description
- class (uint256) - Asset category classification (Dataset: 0x01, Model: 0x02, Agent: 0x03, etc.)
Asset Provenance
- url (string) - Privacy data location on decentralized storage
- hash (string) - SHA256 hash of raw content for integrity verification
- owner (address) - Token owner’s wallet address
- timestamp (uint256) - Creation timestamp on blockchain
Economic Properties
- value (uint256) - Dual-purpose metric representing both data quality and service credit
- quota (uint256) - Optional usage limit; data becomes inaccessible when exhausted
- shareRatio (uint256) - Revenue entitlement in basis points (e.g., 500 = 5%)
expireAt (uint256) - Optional expiration timestamp for time-bound licenses
Access Control & Verification
- permissions (Permission struct) - Wallet address and public key mapping for data access control, typically requiring staking to prevent fraud
- proof (Proof struct) - Authenticity verification containing token ID, quality score, file URL, and proof URL from TEE/ZK/OP verification
- verified (boolean) - Verification status flag
Usage Tracking
- metrics (mapping) - Records AI process interactions with account addresses and usage type/count for inference, training, or RAG queries Usage Tracking
VALUE Semantics: Dual-Function Economic Model
1. Service Usage Credits
The value field represents service credit. Each DAT has an initial value, which is usually evaluated by the validator node of the corresponding iDAO based on the quality, uniqueness, and relevance of the data. This creates a quality gate: users cannot upload data that is completely irrelevant to the iDAO or is of low quality, which would result in a very small initial value of DAT.
Value Consumption Model:
- Charged per AI process invocation (training/inference)
- Deducted for dataset/model usage
- Can be recharged through AI processes
- Recorded on-chain for complete traceability
Example: A DAT with CLASS = 0x03 (Agent) and value = 1000 enables 1000 model invocations or equivalent compute resources.
2. Fractional Ownership & Revenue Distribution
For dataset and model DATs, value also represents fractional ownership stakes, enabling automatic revenue distribution:
- Model usage by other agents triggers proportional income splits
- Dataset contributors earn shares when data is used for training
- Rewards settle automatically to token holders without manual claims
Revenue Calculation Example:
Model DAT #1234 total supply: 10,000 shares
Your DAT holding: value = 500
Monthly model earnings: 10,000 DAT
Your revenue share: (500 / 10,000) × 10,000 = 500 DAT
System Architecture & Lifecycle
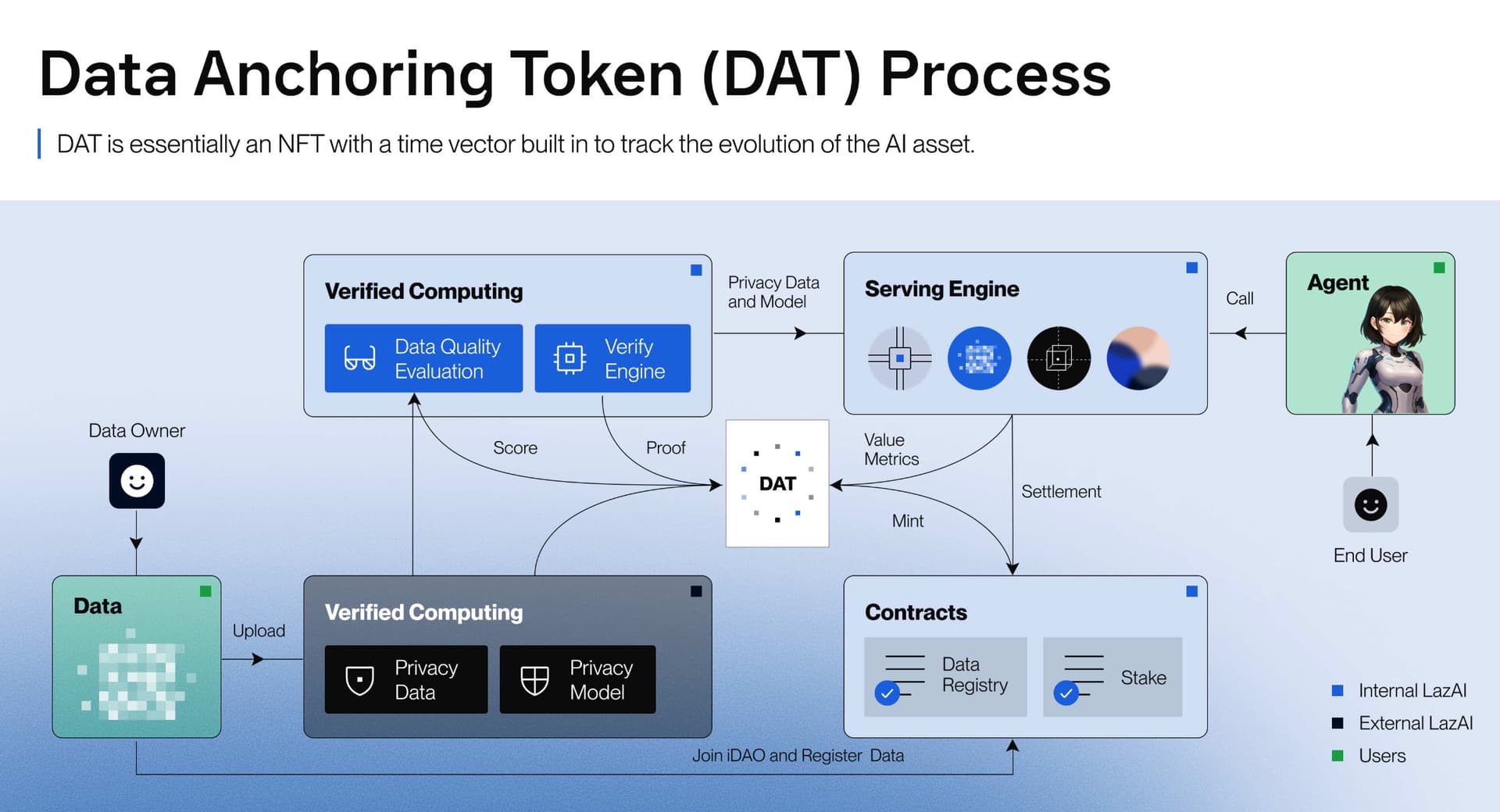
Phase 1: Asset Class Creation
createClass(
1, // classId
“Medical Dataset”, // name
“Open-source disease classification dataset”, // description
“ipfs://metadata/med-dataset-class” // URI
)
Phase 2: DAT Minting & Asset Binding
mintDAT(
user1, // recipient
1, // classId: Medical Dataset
1000 * 1e6, // value: 1000 (6 decimals)
0, // expireAt: never expires
500 // shareRatio: 5% (in basis points)
)
Multi-User Ownership: Mint multiple DATs within the same class to distribute fractional ownership across contributors.
Phase 3: Usage-Based Value Transfer
transferValue(
user1TokenId,
agentTreasuryTokenId,
100 * 1e6 // 100 units of value
)
Enables pay-as-you-use models where agent invocations deduct value from user DATs to treasury contracts.
Phase 4: Automated Revenue Settlement
When AI agents generate revenue from serving requests:
agent.payToDATHolders(classId, 10 USDC);
The contract calculates each DAT holder’s shareRatio and distributes revenue proportionally without requiring individual claims.
Phase 5: Expiration Enforcement (Optional)
require(block.timestamp < dats[tokenId].expireAt, “Token expired”);
Supports subscription-based AI services and time-bound licensing models.
Advanced Technical Features
Programmable Authorization (UsagePolicy)
- Define temporal usage windows
- Whitelist specific agent contracts
- Control transferability restrictions
Multi-Version Proof Tracking
- Support iterative model training cycles
- Attach updated proofs for each training round
- Maintain complete provenance chain
Chain Resource Awareness
- Track storage footprint by asset type
- Monitor compute resource allocation
- Enable resource-based pricing models
Class-Level Approvals
function approveForClass(uint256 classId, address operator, bool approved) external;
function isApprovedForClass(uint256 classId, address operator) public view returns (bool);
Purpose: Delegate control to platforms, automation contracts, or managed execution systems without requiring individual token approvals.
Production Use Cases
1. Decentralized inference markets: Usage-based pricing for LLM/vision model APIs with automatic revenue splits to model trainers, data contributors, and compute providers
2. Federated learning coordination: Revenue distribution across dataset providers proportional to training contribution
3. Agent-to-agent transactions: Autonomous agents purchasing inference quota with programmatic access control
4. Composable AI pipelines: Chain multiple model classes (preprocessing → inference → post-processing) with usage tracking across the full stack
Smart Contract Implementation
The DAT contract provides a comprehensive implementation with the following:
Key Contract Functions
Class Management:
createClass(classId, name, description, dataURI)- Create new asset category (owner only)classURI(classId)- Returns metadata URI for a classcontractURI()- Returns contract-level metadata
Token Operations:
mintDAT(to, classId, value, expireAt, shareRatio)- Create new DAT (owner only, returns tokenId)transferValue(fromTokenId, toTokenId, value)- Move value between same-class tokensapproveForClass(classId, operator, approved)- Delegate class-level controlisApprovedForClass(classId, operator)- Check approval status
Query Functions:
valueOf(tokenId)- Get token’s current valueclassOf(tokenId)- Get token’s classshareOf(tokenId)- Get token’s revenue share ratiotokenSupplyInClass(classId)- Get total tokens minted in a classclassCount()- Approximation of total classes