I’d like to come to a concrete decision on which of these options we should use so we can deploy a final version and start coordinating around one specific instance of it.
You should log the complete contents - option 1. Anything else requires an archive node for an indexer, because it will have to trace every transaction.
You should also consider using something more compact than JSON. CBOR is a good alternative that can be translated to/from JSON, and also has extensions that support eliminating duplicate strings and pre-seeding known identifiers (like dictionary keys).
Finally, you should probably use ENS reverse resolution in any UI to assign usernames to users!
Same as Nick said. Use log events, otherwise indexing is going to be a lot harder.
The idea of doing it in a side-chain or another chain may also not be bad. I did not have the time to read the entire proposal but if it’s a lot of data you would need to choose a much more compact format than json and even if you do, mainnet may end up being too expensive for you to commit often.
This is pretty much what Ceramic is doing. The most important thing we want when posting onchain is to get a timestamp for votes, if we publish votes after a proposal ended we wont have proof about timestamp for the votes. With this approach we would need to post batch of votes when or just before a proposal ended. Which is going to be too many of them and end-up expensive. I also think having free votes for certain users then paid vote for late users would give a poor experience and add lot of complexity.
Maybe we should clarify if we’re building a social media smart contract, or a voting application. As both would probably be better served with a solution a little bit more custom tailored to the use case.
Also, I think we need to expand on the JSON format if we’re going to go with that.
Cost wise- if we know the format of the message, we might be better off just accepting the arguments of the message as arguments to the function. We could still leave a generalized ‘poster’ function to allow for other kinds of messages, but if posting will happen often, we will gain a lot of performance tuning the interface for the use case.
The whole point here is that the contract should be general purpose enough that it can serve both.
The only difference would be the kind of data that is emitted in post() calls.
Data formatted one way might be interpreted as a tweet, while data formatted another way might be interpreted as a vote, and others may use it for entirely different use-cases (like the token you built).
I’d be interested to see a comparison of the gas costs between the options of separate fields, CBOR encoding, and JSON encoding.
I’d guess there would be very little cost savings between separate fields and CBOR.
Assuming you’re posting an IPFS hash, then there is a fixed cost to post any number of votes.
Yeah, I agree that this is a sub-optimal UX. That said, it should really only affect users posting their votes in the last few minutes. Do you have any insight into what percentage of users post within say the last 10 minutes of a proposal? I’d guess it is a fraction of a percent.
Ok, since the prevailing opinion seems to be event NewPost(address account, string content), I’ve gone ahead and deployed a new version that implements that. It also does a bunch of optimizer runs and I’ve found a salt that gives it 10 leading zeros.
Have updated the OP with details.
I’d like to freeze the contract at this point so we can all coordinate around using that address.
This should be bytes not string if you’re using (possibly-compressed) CBOR. You should probably be really clear about what the exact encoding will be before you publish anything, or there’s nearly no chance that all messages will be intelligible by all consumers!
My only concern with CBOR is that it makes posts less human readable.
One nice benefit of JSON is that humans can read and create posts on existing interfaces that let you interact with the contract’s ABI, like Etherscan.
I wonder if the gas efficiency is worth the decrease in human readability?
You could just be posting hashes of content to EVM, and then storing content trustlessly on decentralized cloud storage which is able to tie into the EVM. With a bit of coding effort, Ethereum and Storj could be connected, allowing affordable trustless data storage. I picked Storj over Filecoin because its twice as efficient with data usage, and picked it over IPFS because IPFS doesnt have guaranteed uptime.
Here is what the developers at Storj say it takes to connect it to ethereum smart contracts:
You could just let the post function take both bytes content and string content (and any other relevant types, if there are any), any/all of which can be blank. Let the subgraphs figure out whether they prefer JSON, CBOR, etc.?
What about these for initial use cases:
Simple twitter clone (subgraph that looks for posts, follow, unfollows)
That’s an interesting idea. Having both a bytes field and a string field would allow users to choose. That said, it does feel less elegant than picking one or the other.
I think my preference is still to stick with string, just so that users have the option to post in a human readable format. The downside is that it effectively doubles the cost of posting in CBOR, which probably negates its cost savings.
That said, I’d predict this being used primarily on L2, so I think this is probably an acceptable trade-off.
There is already a group working on a twitter-like app, so if you want to have a crack at a forum, that would be awesome!
Alright, started laying some stuff out for the forum. It looks like The Graph has a JSON / AS API: Assemblyscript API | Graph Docs
But it parses from Bytes, not from a string. So maybe we need to rethink whether the contract should be taking a string for content again, unless someone wants to write a new library for parsing JSON from strings in assembly script?
Hi there! Jose here, currently working in the first app/ui for Poster, which can be seen here (the source code was already shared by @auryn).
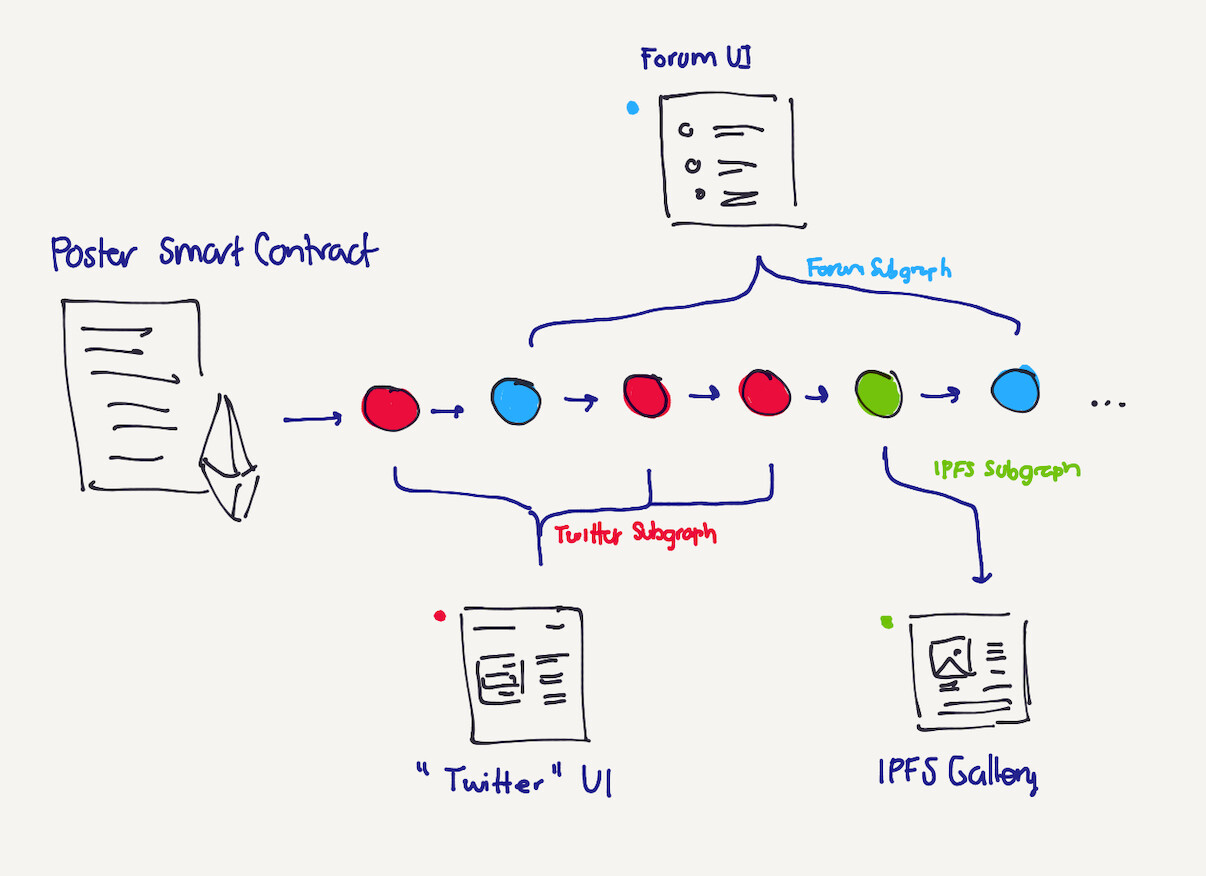
I personally believe that the beauty of Poster is its simplicity, so I’m happy we are leaving it as it currently stands in v6. Anyone can build on top of it via a Subgraph relying on their indexers as a sort of “L2” that processes the content logic in the best way possible, based on the use case. For instance, for our “Twitter”-like demo, I’m parsing the events and limiting the content by 300, but this L2 is defined in the subgraph, not in Poster itself.
Anyone can build on top of the content on top of Poster, using the smart contract as an append-only datastore (L1) that can then be parsed as needed via a given subgraph (L2). Any other event that does not fit the need of their particular use case can be skipped
My suggestion is to document these ideas as PIPs (Poster Improvement Proposals) that define the sort of schema that people would like to organize around. For instance, the “Twitter”-like app was already defined by Auryin very early, so that’s the one I’m starting with, but anyone could do pretty much everything with IPFS, Storj, CBOR, etc, I just don’t think that has to be done in the L1, but on the L2 of the application. Heck, you could design a chess game by sending all the moves via state channels to each user and only commit the match to Poster after it’s completed.
I’ll continue on the current Twitter implementation and do all actions on-chain (although I wouldn’t mind using something like Ceramic Network for the metadata -likes, retweets, et al- interaction), and perhaps toy later with OpenGSN to see if I can upfront people’s submissions cost at the beginning via another token or something. Having to pay every time you do anything on a social network ain’t that much fun.