First Step towards Hot-Cold State Separation
Update (2026-06-11): This EIP previously contained the specs for both recording block number and the pricing for state tiering. The state tiering part was moved to a separate proposal (EIP-8295).
For every account and storage slot, EIP-8188 records the block number at which it was last written. There is no gas change, no removal of state, no tree migration, no resurrection mechanism and no out-of-protocol dependency. It proposes single consensus-visible field last_written_block that names the write-age of each piece of state.
The pricing that uses this signal lives in companion proposals, EIP-8295and EIP-8295.
What EIP-8188 does
The full spec is in the EIP. TLDR:
-
The account RLP gains a fifth field,
last_written_block. Storage slot encoding wraps the value in a list to add the same field. -
The field is set to the current block number when the item is mutated. Reads never touch it.
-
No gas costs change. Read pricing, write pricing and EIP-2929’s warm/cold distinction are all untouched.
The architectural unlock for EL clients
last_written_block gives every client the same write-age signal at consensus level. Today each client picks its own heuristic for which state is “fresh enough to keep hot”. The heuristics work, but they are not agreed across clients and they are invisible to the protocol. EIP-8188 names the boundary once, in consensus. Once named, every client can tier its storage along it without inventing its own definition, and the protocol can later price against the exact same boundary.
The benefit of tiering this way is to decouple the cost of state access and state-root computation from total state growth. If a client keeps only recently-written state on the hot path, the commit-critical work stops scaling with the entire state and starts scaling with the recently-mutated set. Long-term total storage is still a separate problem. This is about the mutable working set, not the size of the archive.
Geth, Nethermind, Besu, Ethrex (LSM clients)
These clients persist trie nodes into a single LSM-tree database (PebbleDB for Geth, RocksDB for Nethermind/Besu/Ethrex). Every trie node is a separate KV entry, and updates to inactive trie nodes pull reads from higher SSTable levels, which means more disk I/O.
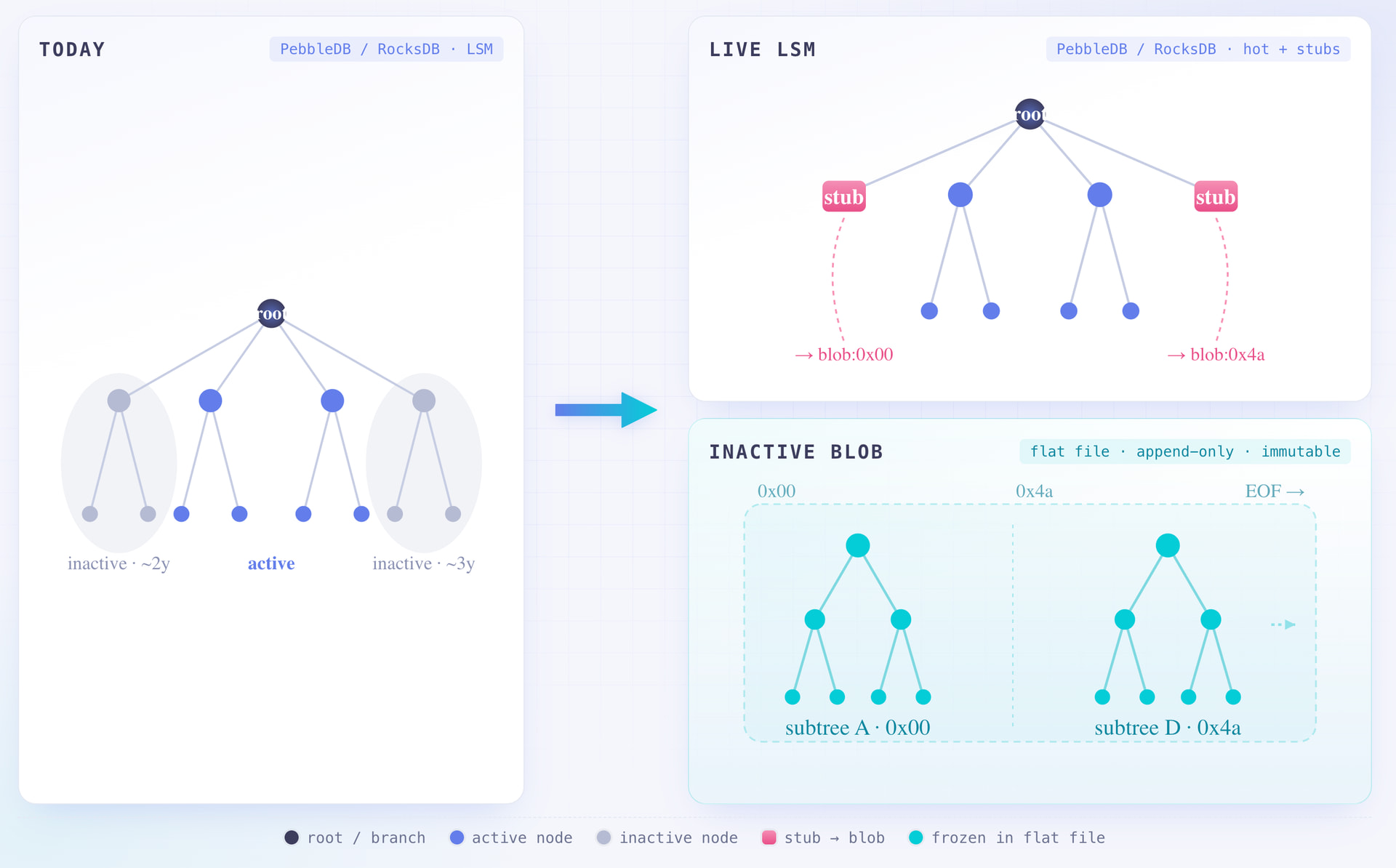
The natural use of last_written_block is to separate cold subtrees out of the live LSM into an immutable, append-only flat file, leaving small stubs in the LSM that point at the cold blob. The live LSM stops carrying state that has not been touched in years, compaction sees fewer files, and the active set gets smaller.
We prototyped this on geth (see Hot-cold storage separation in practice). Replaying mainnet from block 19,999,256 on write-age-tagged state, moving cold subtrees into a compressed archive:
-
The total on-disk footprint comes down, by roughly 22% with compression (a net saving on the order of 54 GB at the recommended cap setting), even though nothing is deleted from consensus.
-
The hot trie shrinks by around 60%, so compaction and the commit path run over a much smaller set.
-
The write-age metadata itself costs under 0.5% of the snapshot.
-
Rebuilding a moved-out subtree on access stays cheap (worst case a few dozen leaves).
These are storage-footprint numbers. Performance under real workloads is still to be benchmarked, and the implementation is unoptimized. The point is that the separation is real and the cold set genuinely stays cold.
Erigon
Erigon 3 already runs as a temporal database. State sits in an MDBX buffer plus four Domains (Accounts, Storage, Code, Commitment) whose recent writes are periodically frozen into compressed segment files. The architecture is close to what EIP-8188 enables, except that Erigon’s hot-cold boundary is its own freeze schedule, not write-age.
The Commitment Domain benefits most, since every state-root computation touches the trie up to the root, including paths that cross subtrees frozen years ago. With the metadata, branches in deeply cold territory can stay in deep snapshot files without being reinserted into the MDBX buffer, and a consensus-agreed boundary replaces the local freeze heuristic.
Reth
Reth uses MDBX and Nippy Jar. MDBX holds frequently-rewritten data such as plain state, hashed state, the trie tables, changesets and history indices. Nippy Jar holds append-only artefacts: headers, transactions, receipts, and eventually frozen plain-state segments. The substrate is already shaped for what EIP-8188 enables.
With a write-age boundary, Reth can split each of its three state representations along it:
-
Plain state. Active accounts and slots stay in
PlainAccountState/PlainStorageState, while cold ones move into per-segment Nippy Jar files. -
Hashed state. Same split, mirrored. The MerkleStage that recomputes hashed state every block runs over the active subset, and cold hashed state is read-only and stable.
-
Trie state.
AccountsTrieandStoragesTrieare MDBX tables today. They can be similarly split, with cold subtrees mirrored to Nippy Jar and the in-MDBX trie keeping references.
FAQ
Why Hegotá and not later?
First, simplicity. The EIP is small: two RLP encoding changes with a clean way to distinguish legacy from post-fork entries, no tree migration, no resurrection mechanism and no networking changes.
Second, and more important, the signal only becomes useful once it has accumulated. last_written_block is only meaningful for state that has been written under the new rules. The earlier the field starts recording, the sooner the cold set is well-defined and the sooner clients and any future pricing can rely on it. Shipping the metadata in Hegotá and deciding the pricing afterward allows for cleaner separation and gives time to finalize on the state tiering pricing.
Isn’t the signal alone pointless without pricing?
The signal alone gives clients a shared storage hint, which is already worth something. But it does not, by itself, make writing cold state more expensive, so it leaves the attack surface open: pulling deeply cold state back onto the hot path stays as cheap as any other write. That is the gap EIP-8295 closes. 8188 is the prerequisite, not the whole mechanism.
Why not state expiry?
State expiry is the bigger long-term lever, and it has been on the table for years. The blocker is resurrection: expired state has to come back when a user needs it, and that requires decentralized, censorship-resistant infrastructure to serve old state on demand. Without it, resurrection data can only come from centralized providers, which is a censorship vector.
EIP-8188 has no resurrection prerequisite. State never disappears. It just gets a label. Whatever decentralized state-serving infrastructure eventually ships will unblock real expiry. Until then, 8188 plus 8295 lets us attack the hot-path cost of state growth without waiting for that infrastructure.
Doesn’t the metadata bloat the state?
The field is small and most state never pays for it. A block number is around 4 bytes on an account and around 5 bytes on a storage slot (the slot also gains a one-byte list prefix). Worst case, if every item were rewritten after the fork:
-
360M accounts × 5 bytes ≈ 1.8 GB
-
1.5B storage slots × 6 bytes ≈ 9.0 GB
-
roughly 10.8 GB total
That is a worst case. Pre-fork state that is never re-touched keeps its legacy encoding and pays nothing. In the hot-cold prototype the realized metadata overhead was under 0.5% of the snapshot, and it is dwarfed by the multi-GB the separation saves on the hot path.
Is it compatible with future tree migration?
Yes. last_written_block is tracked per account and per slot. When the trie moves to a page-based layout (such as EIP-7864), the field aggregates to the page: page.last_written_block = max(item.last_written_block for item in page). The page stays active for as long as any item inside it is written, which matches how clients load and store a page as a unit anyway.
Closing
EIP-8188 is the small, self-contained first step. It makes the recently-mutated set explicit at consensus level and gives every client the same boundary to tier storage along, without changing a single cost. On its own it is a storage hint with measured benefits. Paired with EIP-8295/EIP-8296 it becomes a pricing signal that stops treating writes to inactive state as if they were free.