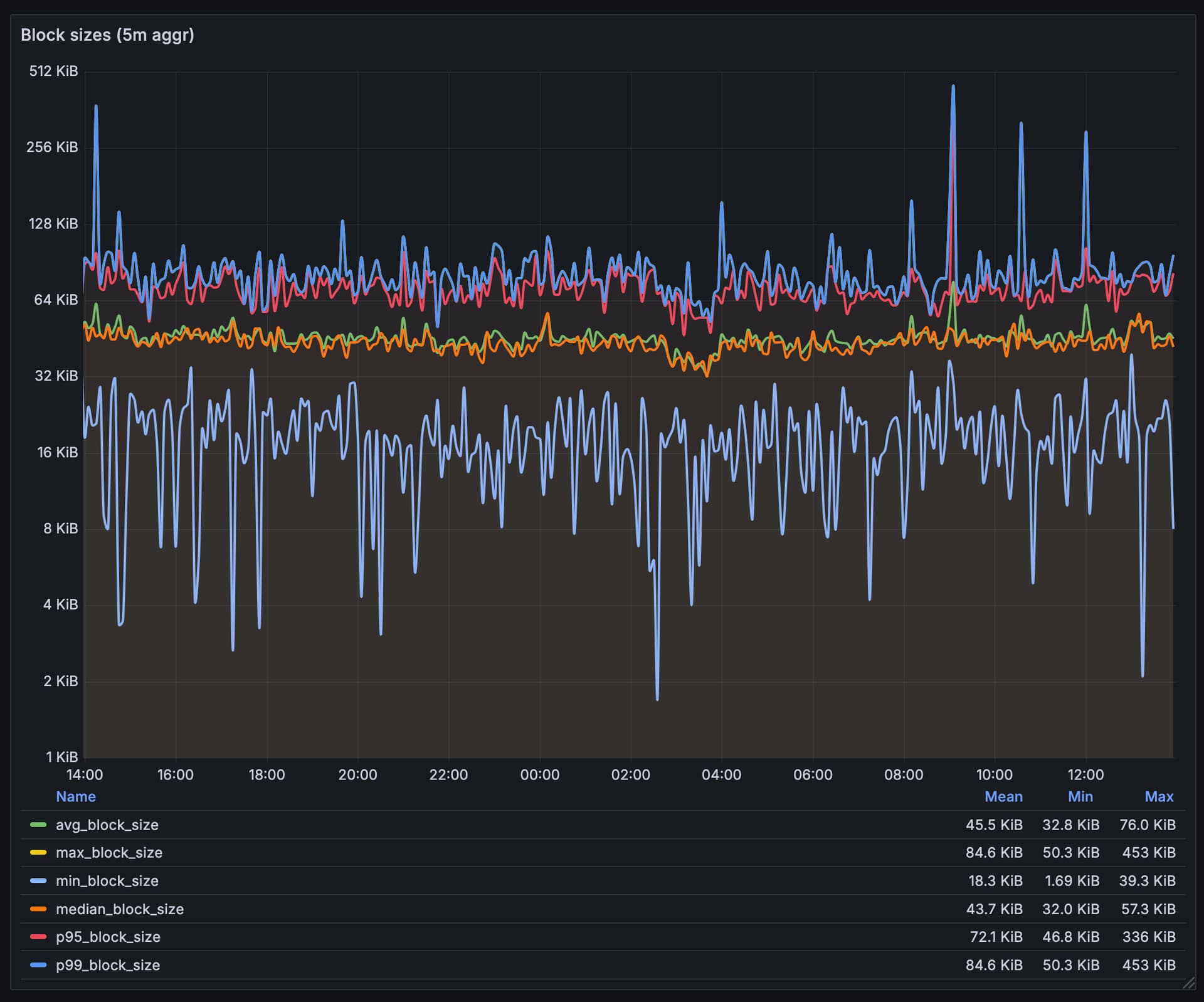
I’m concerned about the size and verbosity of the BAL. At 40KiB, this represents a non-negligible overhead that causes block sizes to increase by 2x, and p95 grows by 1.55x (below is a chart showing mainnet stats over the last). This creates an opportunity cost, as the additional bandwidth could alternatively be used to increase gas limits.
Proposed exploration: Deterministic execution plans
I propose exploring whether we can replace the diff traces in blocks (the BAL itself as defined today) with a deterministic, canonical, parallelizable tx execution plan calculated by the proposer based on traces generated during sequential execution.
Instead of embedding complete differential traces in blocks, we would include a double-nested list containing positional references to txs: [[txidx1, txidx2, …], [txid3], […], …]. This structure can be accompanied by a version identifier to enable logic updates over time.
This approach can be regarded as extremely efficient compression, by enshrining a version of the parallelism heuristics within the protocol (which also reduces the risk of state mismatches between clients due to disparate logic, if this was left up to implementations).
Under this model, we could offload the full BAL from the block, while maintaining a commitment to it for verifiability. The BAL paylaod could propagate through a separate, less critical network path, while light clients could still request it when needed to update their local state, preserving the related EIP’s benefits.
Validators would execute transactions following the specified execution plan while detecting data races or conflicts (this detection mechanism requires further research, but a priori it appears feasible). If a conflict is detected, the validator would immediately reject the block. If validators additionally generate differential traces, they could sequentialize them and verify against the commitment.