For on-going discussion and feedback for EIP712.
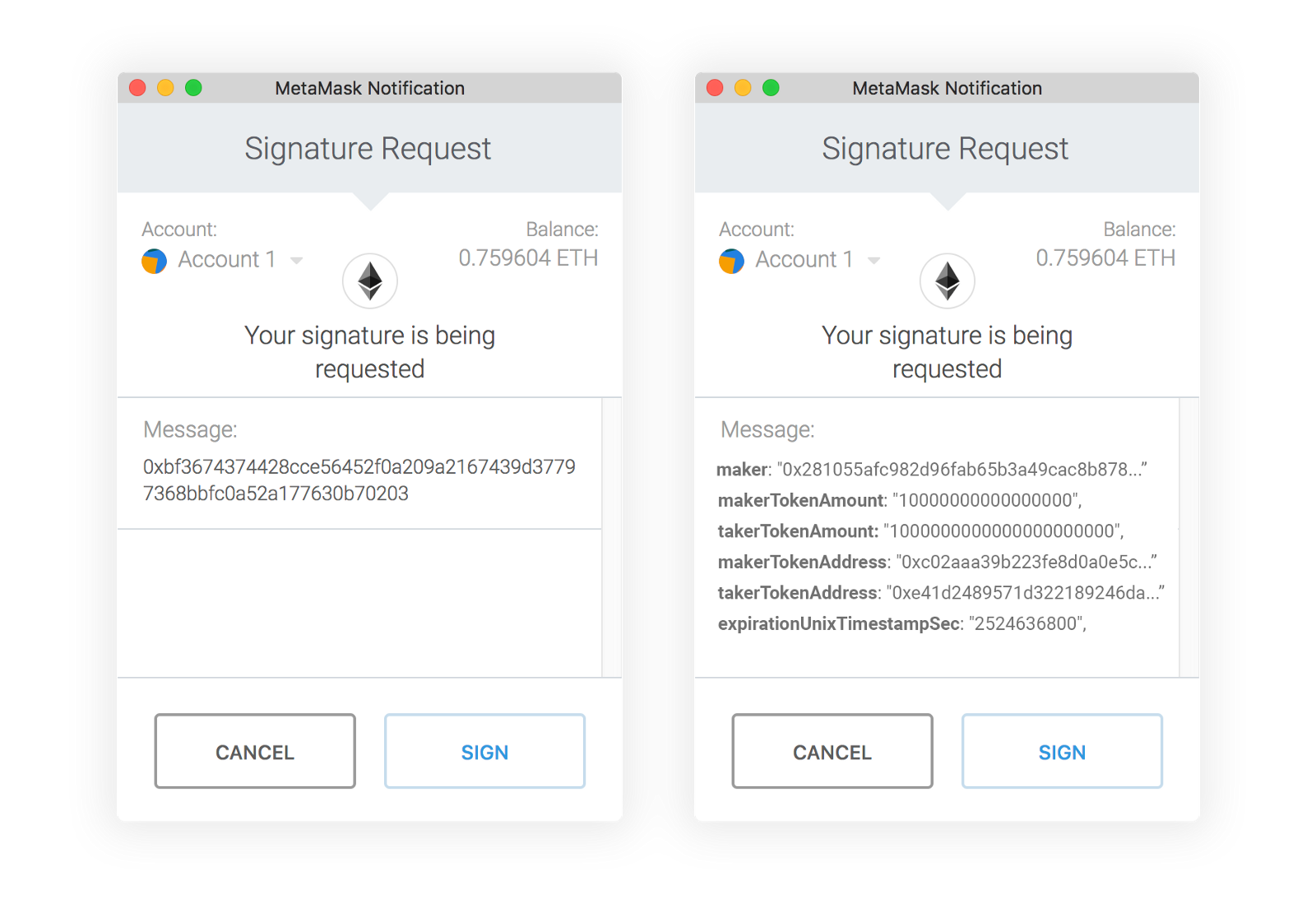
Left old, new right
Just a minor point that should probably be cleaned up.
In the draft spec…
Returns
DATA: Signature. As in eth_sign it is a hex encoded 129 byte array starting with 0x. It encodes the r, s and v parameters from appendix F of the yellow paper in big-endian format. Bytes 0…64 contain the r parameter, bytes 64…128 the s parameter and the last byte the v parameter. Note that the v parameter includes the chain id as specified in EIP-155.
But EIP-155 Chain IDs can be larger than a byte (elsewhere in the spec it is encoded as uint256).
Clients probably should not rely on a fixed length response of 129 bytes. Perhaps “a hex encoded byte array of at least 129 bytes…”
This is copied almost verbatim from the official Ethereum JSON RPC. Personally, I think packing the three values into a hex string is a bad idea and I would rather have a structure with v, r, s attributes.
Given the elsewhere mentioned confusion about v,r,s vs. r,s,v order and the above mentioned assumptions on the size of v I’m inclined to go for the object approach instead of packed binary.
What do you think?
I agree that it’d probably be clearer to return a JSON object. Labeled fields eliminate a lot of ambiguity.
If you don’t do this, you’ll have to keep it in r,s,v order given the variable length of v. (And that’s a bit weird, since transactions are signed in v,r,s order.)
What is the purpose of the domain separator?
The domain separator prevents collision of otherwise identical structures. It is possible that two DApps come up with an identical structure like Transfer(address from,address to,uint256 amount) that should not be compatible. By introducing a domain separator the DApp developers are guaranteed that there can be no signature collision.
What I mean is, should it be verified “against” anything?
Great work by the way, @Recmo!
Hello, I don’t exactly know where to ask questions about EIP’s, so I’m trying my luck here …
At the end of EIP-712’s draft, there is a link toward example files (.sol for the smart contract and .js for the tester). In the smart contract, hashes are computed using keccak256(abi.encode(...)). I am used to doing keccak256(abi.encodePacked(...)), which is slightly different when dealing with addresses and correspond to web3.utils.soliditySha3.
using encodePacked and soliditySha3 I managed to have both part of my application compute hashes the same way, but in order to benefit from the EIP full potential I have to make sure other entities (like metamask) will be able to reproduce my hashes.
The thing is, encodePacked can be nested, which is a feature I need due to my struct having to much members → too much local variable to do a single abi.encode.
I saw in the EIP that this is discussed as “alternatives” … and that the encoding should be feaseable in place … but not being fluent in assembly, I’m not very confident in my ability to do the hashStruct myself …
Hi,
I have just heard that this EIP is getting finalized. I would like to propose an important change:
It has been discussed briefly before and was the reason domain separator came into being in the first place but I would like to bring back the possibility again to add the “origin” back into the data being signed.
see https://github.com/ethereum/EIPs/pull/712#issuecomment-330501545
and https://github.com/ethereum/EIPs/pull/712#issuecomment-364495160
This would allow smart contract to ensure the user has signed the data in a set of allowed origin.
The web3 signer would be in charge to add the origin data. This is not a data that can be set independently so that the user can’t be cheated in thinking the data is for another purpose.
Note that this extra data can only increase the security of the proposal.
Hi
Has anyone managed to verify typed data with an array? Most of examples I found still don’t define arrays, not even the reference example: https://github.com/ethereum/EIPs/blob/master/assets/eip-712/Example.js#L102
How would one verify a signature with data structured like for example:
struct Action {
uint8 kind;
}
struct Order {
address sender;
Action[] actions;
}
I discussed that with @remco at EthCC, and he confirmed that the process for hashing array (fixed or arbitrary size) isn’t formally described yet. This is one of the last points that need addressing before ERC712 can be finalized.
What can I do to help finalize it? I’m not sure how to tackle this.
For example how to define typehash for the struct with arbitrary size array?
iExec is using ERC712 for active production on mainnet since V3 was deployed in on may 15th. I’m sure we are not the only one.
It’s high time this ERC moves toward finalization. I believe one of the last obstacle is the formalisation of dynamic array hashing (which is something iExec will need for V4, so I’m trice motivated to get that sorted out). Only then will we have Ledger (and other wallet) support.
@Recmo , as far as I understand, you are the ERC712 leader (at least you are to me) … do you have any opinion on that ? I’d love to contribute to move this ERC forward but I don’t feel like I have the weight needed to lead it.
There are at least three issues to resolve / take decision on for EIP-712 in my opinion:
I’m not sure where the pair came from, but chainId should be sufficient by itself as it should not change very often. Even if a rotating chainId process is add to hard fork upgrades, it would still change less than 1-2 times per year, and that is something easily tracked and submitted separately by the application, depending on the methodology used.
As stated in EIP-1344’s discussion, some applications may not require historical chainId at all, or may desire an application-specific way of updating it for increased safety of the application. We’re still unsure which methodology will be chosen in Istanbul, so I would caution against premature optimization here.
I agree that if chainId was the only thing to change, we would be fine. That is why I mention the (chainID, blockNumber) pair.
The need for blockNumber was discussed as part of our conversations.
It is explained here : EIP-1959 Valid ChainID opcode - #5 by wighawag and in the rationale of EIP-1965
It is to allow fork led by minority to not suffer from replay issues from the majority inaction (since the current chainId from the majority chain would be a past chainId on the minority chain). The blockNumber at which the message was signed can ensure replay protection by making smart contract disregard message signed at a blockcNumber where a chainID is a past one.
with EIP-1965 it simply expressed this way :
require(validChainId(message.chainId, message.blockNumber), "invalid message on that chain");
And by letting wallet setting the blockNumber as part of EIP-712, they protect users from replay issues.
A protection that EIP-1344 can’t handle properly since the required caching mechanism would leave a gap.
While it is technically true that they do not require it to function, they require it to function as expected. Indeed, smart contract that disregard past chainID will render their user dependent on the message submission timing. For example, a user could not rely anymore on being able to delay a message, since as soon as a hardfork happen, the user would have to sign the message again. This is less than ideal and why I think we should consider all application as benefiting from respecting past chainIDs.
But we should probably discuss that in EIP-1344 discussion thread if my comments there were not clear enough.
It’s a requirement if 1959 or 1965 is adopted. It is not if 1344 is adopted instead. I think the decision to update this specification relies on the outcome of what is adopted in that case.
For certain use cases, this is acceptable. For some, it is actually more ideal.
An example of the former is the meta-transaction use case, where chainId is used as a domain separator for offline signing. These transactions are meant to be resolved in under a day, so if an older value of chainId is used, it is acceptable to ask the user to re-submit with the new value.
An example of the later is Plasma Transactions. In that use case, it is required that the value of chainId chosen aligns with the value that the operator uses in their block submission summary transaction, therefore it is important that the operator has control over what value is accepted by the contract (can be updated trustlessly, during the block submission transaction). chainId might be updated in between submissions, therefore it is important that the operator only accept submissions with the correct value of chainId that they will upload, and reject others. Having it be either/or would be more dangerous.
We can continue this conversation in the EIP-1344 thread, as it relates to prior discussion we’ve had on this exact topic. My point was not to prematurely optimize for an EIP that is not yet confirmed to be in the next hard fork, as we are still figuring out which path will be chosen.
An example of the former is the meta-transaction … it is acceptable to ask the user to re-submit with the new value.
Acceptable but not desirable
An example of the later is Plasma Transactions. …the operator has control over what value is accepted by the contract (can be updated trustlessly, during the block submission transaction).
As already mentioned in our previous conversation, such chainId information can be provided by other means. It does not need to be coupled with EIP-712 where the role of chainId is replay protection
I agree, the reason I posted my 3 points here is that I realized not everywhere is aware of the current dicussion about chainID. EIP-712 was designed before that.
I think the decision to update this specification relies on the outcome of what is adopted in that case.
My goal was not to update the spec, it was just to bring awareness to the current discussion. Did not want EIP-712 to get finalised without that info first.
Can’t we simply re-use the EIP-712 hashStruct for byte arrays? So long as one of the contract down the line can interpret this embeded hashStruct, the original contract called doesn’t need to know what this hashStruct is. It will simply take the hash of that byte array before doing an EIP-712 hash, like specified in the spec and can then pass that bytes array to another contract, which understands what the structure of that bytes array is.
We could also use the functions structure in some instances, where the first 4 bytes are a “function signature” (e.g. bytes4(keccak256(buyTickets(unit256 _amount)) and the rest of the bytes array would be the encoded arguments for that “function signature”. Of course, the bytes4 don’t need to be functions per say either.
Reusing the logic of byte arrays for uint[], bytes32[] or any other array of “native types <= 1 word” is ok, but it goes against the whole proposal for arrays of struct (such as a Recipient[] where Recipient would be a struct with multiple entries).
I believe the logic would be to hash each entry, turning the Recipient[] into a bytes32[] and then hashing the bytes32[]. The drawback is that this cannot be done in place.
In the end, it’s pointless what I believe the logic should or should not be, as long as we have ONE way to do it that is part of the standard
Here’s maybe a way to do general array hashing: signTypedData for arrays by cag · Pull Request #54 · MetaMask/eth-sig-util · GitHub
Arrays of atomic types have been encoded as a hash of its contents, where its contents are word-aligned according to the type.
Arrays of dynamic types have been encoded as a hash of each element’s hash.
Arrays of structs retain their encoding as a hash of its contents’ concatenated hashStructs.
Arrays of arrays are encoded recursively, as a hash of the contained arrays’ hash encodings concatenated.
Additionally, how should clients handle missing values in an eth_signTypedData structure? eth-sig-util currently skips over fields which are missing, but it uses the same type hash, meaning a struct like Foo(uint256 bar,bytes32 baz) may only have hashStruct(typeHash(Foo) . baz) if bar is undefined on the message. In the PR, because it was simpler to do so in the rewrite, I’ve made every field specified in the typeHash required, but Dan wanted to know if there was a preference for the optional behavior.
Note that this is different from requiring fields like string name to be specified in the EIP712Domain struct. I’m asking about the behavior once the type has been specified whether or not those fields specified should be considered optional.
Personally, I think this should be an error, since using the Foo example, how do you know whether second part of the hashStruct payload refers to bar or baz?
I have a feeling that maybe asking to limit the scope of EIP-712 and introducing this in an EIP extension may be the way to go, as I may have heard of some hardware vendors claiming EIP-712 support, where for them it might actually mean something along the lines of “flat structures containing primitive types” support (I think somebody might have mentioned that being a EIP finalization target). If so, it would be good to get the opinion of relevant stakeholders in this discussion, as I would guess it wouldn’t be feasible to upgrade existing hardware that’s out there claiming EIP 712 support, but I haven’t read through the original discussion thread on Github yet, as it’s pretty long…
It could be that it’s just the crypto primitives being implemented in hardware though, and that software support for this may be added after the fact, in which making this a patch to the EIP could make sense instead.
I’ve done some looking into whether or not this extension can be added to hardware, and it seems that for the majority of the cases, hardware support is for building blocks, and support just has to be added on the Ethereum app level in the case of Ledger or at the firmware level in the case of Trezor. Since this is the case, and because the recent discussion seems to imply dynamic and nested types will be part of the final spec for this EIP, I’ll write an update to this EIP accordingly.
I’ve written a PR to ERC-712 here.
In addition to the changes quoted above, I’ve made all specified struct members mandatory except for structs. The reason why structs are not mandatory is because I’ve realized that the standard intended for recursive types to be possible. As an example, consider:
struct Node {
bytes data;
Node next;
}
This was a valid type in the standard, but it wasn’t clear how to encode instances of this type. With mandatory struct members, this type would not be possible to express. I’ve taken the liberty to state that given the example, the next field may either be encoded recursively as its structHash, or as bytes32(0) when expressing its absence from an instance.
