DeFi protocols currently do not have a convenient way to identify tokens that derive value from underlying assets unambiguously. Examples of such tokens in the context of this EIP are derivative tokens (tokenized LP positions, token bundles) or, more generally, tokens that could change their state without changing their token identifier.
For example, imagine a token bundle with ten rare tokens and the same bundle after withdrawing nine of them. The bundle will most likely not change its token identifier. However, it is evident that the intrinsic value of the bundle has changed (bundlers could be implemented differently, but you get the gist). To prevent bundle owner from receiving an offer, withdrawing most of the intrinsic value out, and then accepting the offer, DeFi protocols can currently do one of two things:
- Wrap derivative token
- Know derivative token implementation details
Wrap derivative token
A protocol can prevent a token owner from modifying the token state by forcing the user to wrap its derivative token first. However, that creates additional inconveniences. First is the inability to use tokens utility that does not change the state (e.g., voting, token gated access, potential airdrops). Second, unnecessary wrapping and unwrapping transactions cost gas.
Know derivative token implementation details
DeFi protocol can have the knowledge of bundle state properties and include them in a proposed offer. That unambiguously identifies the bundle and its state and prevents the owner from accepting an offer after modifying the bundle.
However, protocols need to add support for every new derivative token, which leads to an obvious bottleneck.
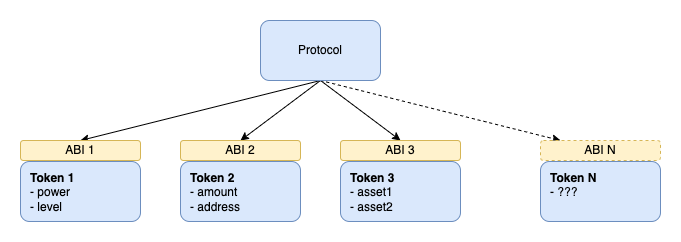
Solution: Token State Fingerprints
By defining a simple getter function for a token state fingerprint, DeFi protocols can use it and support derivative tokens without knowing the implementation details. It removes the bottleneck issue with new derivative tokens.
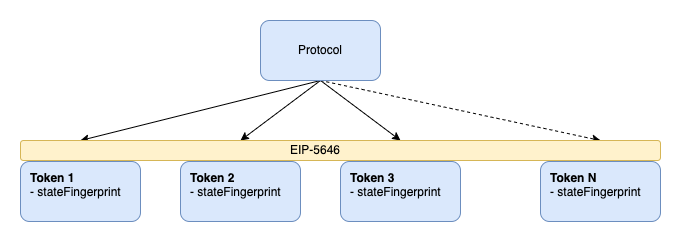
This standard does not define how should be the getStateFingerprint function implemented. For example, a simple hash of an abi encoded state parameters could be enough as a state fingerprint. However, some tokens could implement a more gas-efficient way for their specific state. For example, some implementations could compute the fingerprint on the fly, whereas others can store it and update its value with every state-mutating call.
It is unnecessary to prevent state fingerprint collision between two different token contracts as state fingerprints should be compared only in the context of one token contract. Because of that, an implementation does not have to include any domain separators.
This standard can be implemented by EIP-721, EIP-1155, or any other token contract that identifies tokens via uint256 value.
Contrary to EIP-1948, this standard does not define a function for directly updating state fingerprints. Instead, the intention is to update state fingerprints only via state-mutating calls.
Compared to Non-Fungible Token State Verification, this standard leaves token state fingerprint composition to developers. As a result, it should lead to easier adoption of the standard as protocols do not have to compose the state fingerprint themselves.
Two possible workarounds exist for already deployed tokens that cannot implement this EIP directly.
- Token developers can deploy an auxiliary contract, implementing EIP-5646 and promoting it as an official extension.
- Protocol developers can deploy their auxiliary contract implementing EIP-5646 for every supported token.
In both these cases, the protocol has to support tokens specifically.
It works well with other standards. Take EIP-4400 as an example. State fingerprints can include consumer addresses and will be updated every time the consumer address changes.
Open questions
- Should EIP-5646 define a
StateFingerprintUpdateevent that is emitted on state fingerprint change? The event cannot cover 100% of updates (e.g., when the state depends on a block.timestamp, or oracle value).