I implemented the merkleization logic in a fork of geth and measured the overhead. The goal is to determine how much contract creation gas costs need to be bumped.
The following chart shows the merkleization overhead in terms of gas in relation to the contract size, for all contracts on the Goerli testnet. Gas was computed by measuring the runtime and comparing it against the runtime of the ECRECOVER precompile on the same machine.
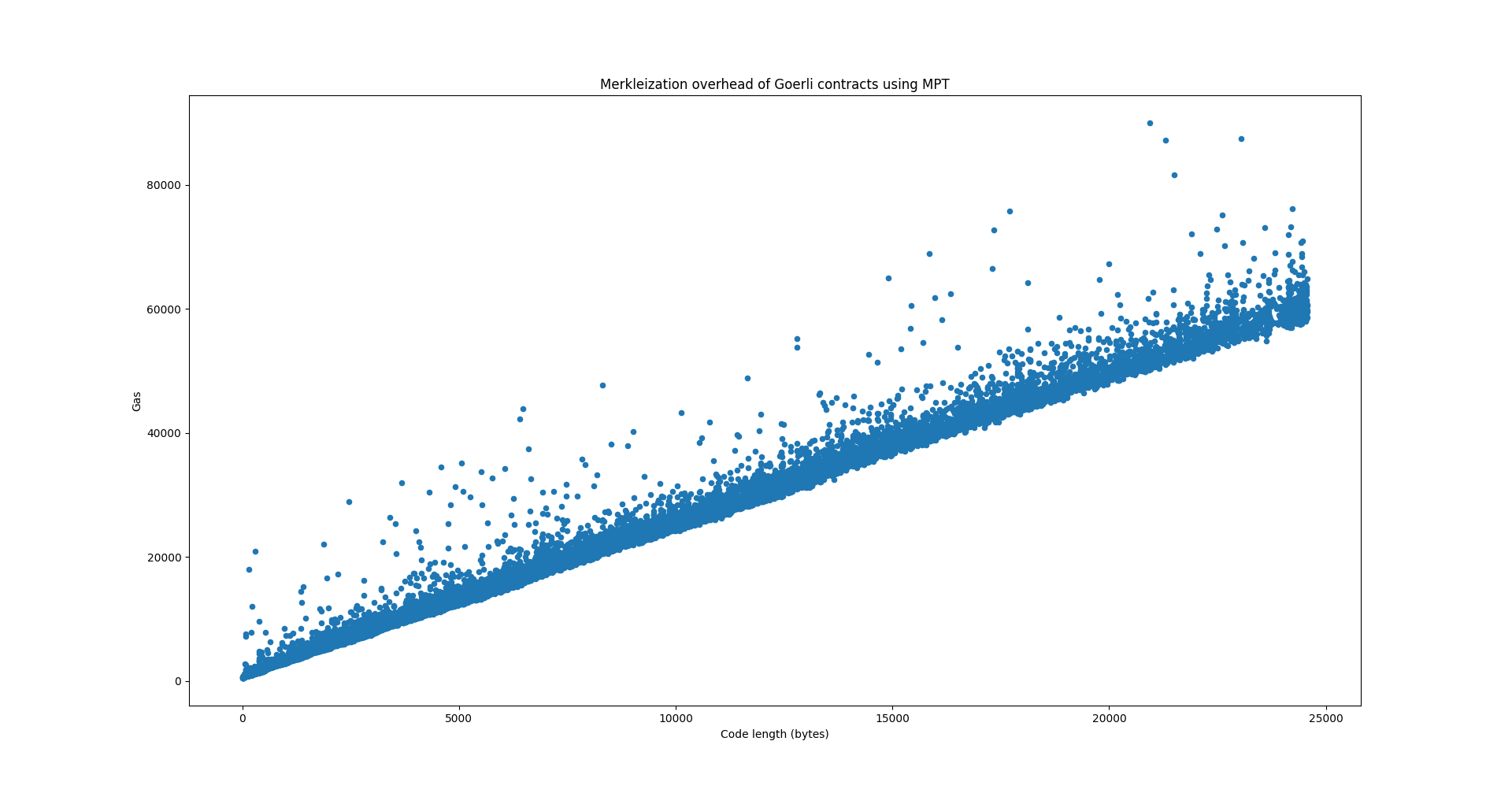
Here we used the hexary MPT for the code tree as specified currently in the EIP. As expected the runtime rises linearly with code size. Currently contract creation costs 200 gas per byte of code. By increasing that number to 203 we can cover this overhead. Or because the overhead is not that significant not bump the gas cost at all.
But we don’t plan to use the hexary MPT for code. There are 3 options: SSZ, a simple merkle tree, the binary trie. Here I also experimented with the fastssz implementation and measured the overhead in a similar way as above.

Fastssz uses an accelerated sha256 implementation by default for hashing the tree. The column ssz_sha shows fastssz’s performance overhead when using the default hasher. ssz_keccak replaces the default hash function with geth’s keccak256 implementation. Interestingly both perform better than the MPT, even though binary trees incur more hashing. I think this might be because SSZ’s tree structure is more-or-less known at compile-time as opposed to the MPT.
The same measurement is pending for the binary trie and I’ll update the post once I have numbers on that.