Code merkleization, along with binarification of the trie and gas cost bump of state accessing opcodes, are considered as the main levers for decreasing block witness sizes in stateless or partial-stateless Eth1x roadmaps. Here we specify a fixed-sized chunk approach to code merkleization, outline how the transition of existing contracts to this model would look like, and pose some questions to be considered.
I think it would be worth explicitely forbidding 0xffffffffas a key for a chunk. This fits into the practically we won’t ever have this problem, but in theory, long enough code would overwrite the metadata entry.
Cool to see the EIP, just gave it a read-through. At the risk of bike shedding I’d like to float the idea of removing the RLP from the spec. It looks like the only places that RLP is used are:
RLP([METADATA_VERSION, codeHash, codeLength])
RLP([firstInstructionOffset, C.code])
LEB128 looks suitable for METADATA_VERSION, codeLength, and firstInstructionOffset. codeHash can just be fixed length bytes. C.code can also just be the raw bytes, allowing us to just serialize these using concatenation:
If there is negative sentiment towards LEB128, codeLength could be a fixed size (?4 bytes?) big endian, and METADATA_VERSION & firstInstructionOffset could just be encoded as single bytes.
This eliminates any need for the spec to specify how each of these individual things are serialized, as well as leaning on the existing SSZ merklization rules.
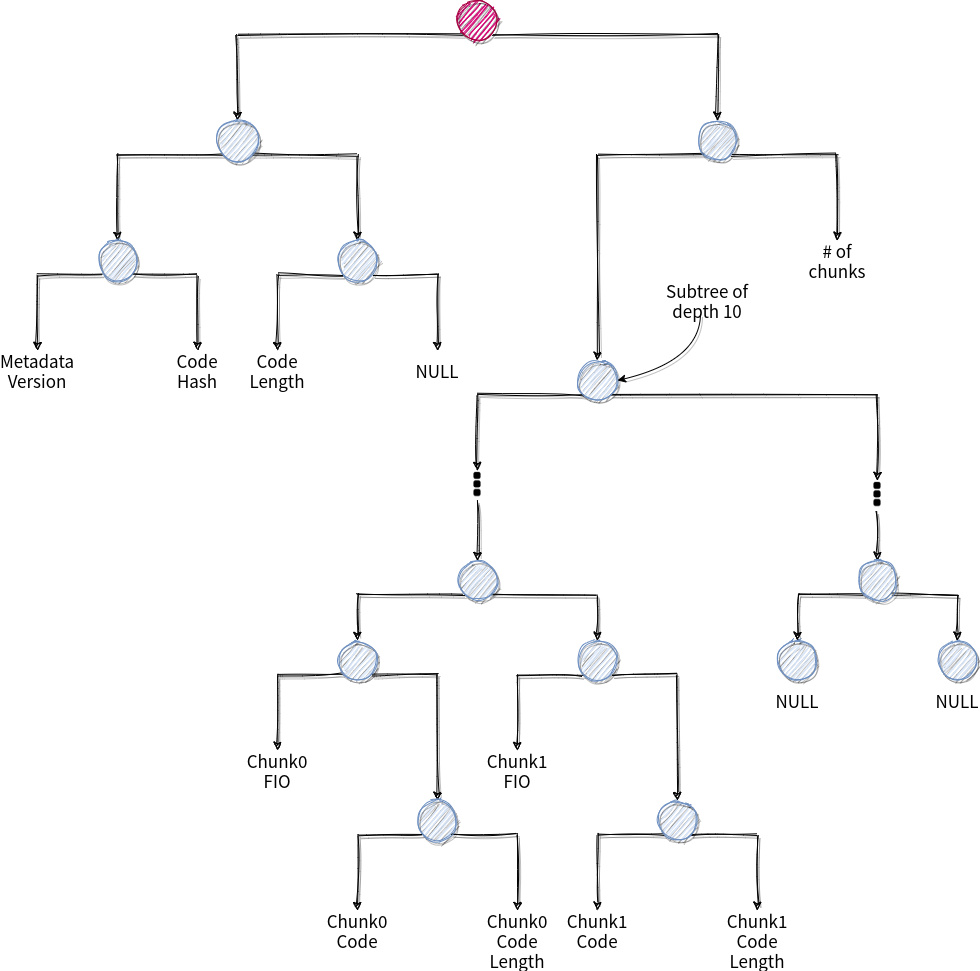
This was my first interaction with SSZ, so sharing my takeaways here:
Leaves are (padded to) 32 bytes
The List type needs a limit parameter. This means if we assume a contract could have at most 1024 chunks (768 rounded to the next power of 2), regardless of the actual number of chunks the corresponding subtree will have 1024 leaves. This can affect proof size if empty subtrees are not compressed
I used a List of bytes with a limit of 32 for the chunk code (to accommodate the last chunk which can have a length < 32), this basically doubles the number of leaves. We should probably use fixed 32 byte vectors and encode the last chunk’s length somewhere (maybe metadata)
Also by default SSZ uses sha256. But this should be easily replaceable with keccak256
Given that code necessarily has to start from address 0 and fill up addresses from there, and that PC=0 is the necessary entry point, every proof will have to send the first (leftmost) chunk. Further chunks will be progressively rarer; the rightmost side of the trie will usually be rather empty, since few contracts fill the available code space.
So I’d imagine that putting metadata in the last chunk (addresses 0xfff…) causes the merklization to send the rightmost branch with full cost of the proof for that chunk, since the hashes for that proof won’t be usually amortized by the neighboring chunks.
Therefore, wouldn’t it be better to do something like putting the metadata in an extra chunk at the leftmost side of the trie, before the code block at address 0? This way, the metadata and first block of code (both always needed) can be sent together and amortize their proofs.
Of course this means that every code block would have to be “shifted left”, but that is an exceedingly simple fix. Also, this prevents the collision risk that @pipermerriam mentioned.
Regarding the use of Merkle Patricia Tries: why not use instead a simpler Merkle Tree? Given that chunk sizes are known and are filled from address 0, the (key, value) capability of the MPT is probably not useful, since the key can be easily calculated from the tree’s (or proof’s) structure. I imagine this would simplify things / save space?
Regarding the use of Merkle Patricia Tries: why not use instead a simpler Merkle Tree?
SSZ already uses simple Merkle trees, not MPTs.
I was experimenting with @pipermerriam 's suggested schema and was mainly curious how the backing tree would look like.
Why have length for each chunk? Isn’t length already covered by the code length (and again by the chunk count)? I saw the comment “Last chunk could be shorter than 32 bytes” in the github, but I don’t think there’s any actual need to be strict about this; code ending is identical to code being followed by zeroes (for all purposes except CODESIZE, which uses length anyway).
The options right now are either SSZ as Vitalik mentioned or the binary trie. I’m slightly leaning towards the binary trie just for consistensy’s sake (specially in the proofs) and to unnecessarily introducing a new tree structure. But I’m open for either options.
Why have length for each chunk? Isn’t length already covered by the code length (and again by the chunk count)?
Yes I missed that. Having codeLength it’s easy to infer the length of the last chunk. Thanks!
I have just posted some results of applying fixed-size chunking to >500K Mainnet blocks. The optimal size seems to be 1 byte: 3% size overhead vs 30% for 32-byte chunks.
This happens because:
The median length for basic blocks is 16 bytes, with a statistical distribution very skewed towards smaller sizes.
Smaller contiguous chunks need fewer proof hashes than bigger isolated chunks.
The tools I used have been published and the results should be repeatable in a matter of hours by anyone interested. So I hope I am not missing anything!
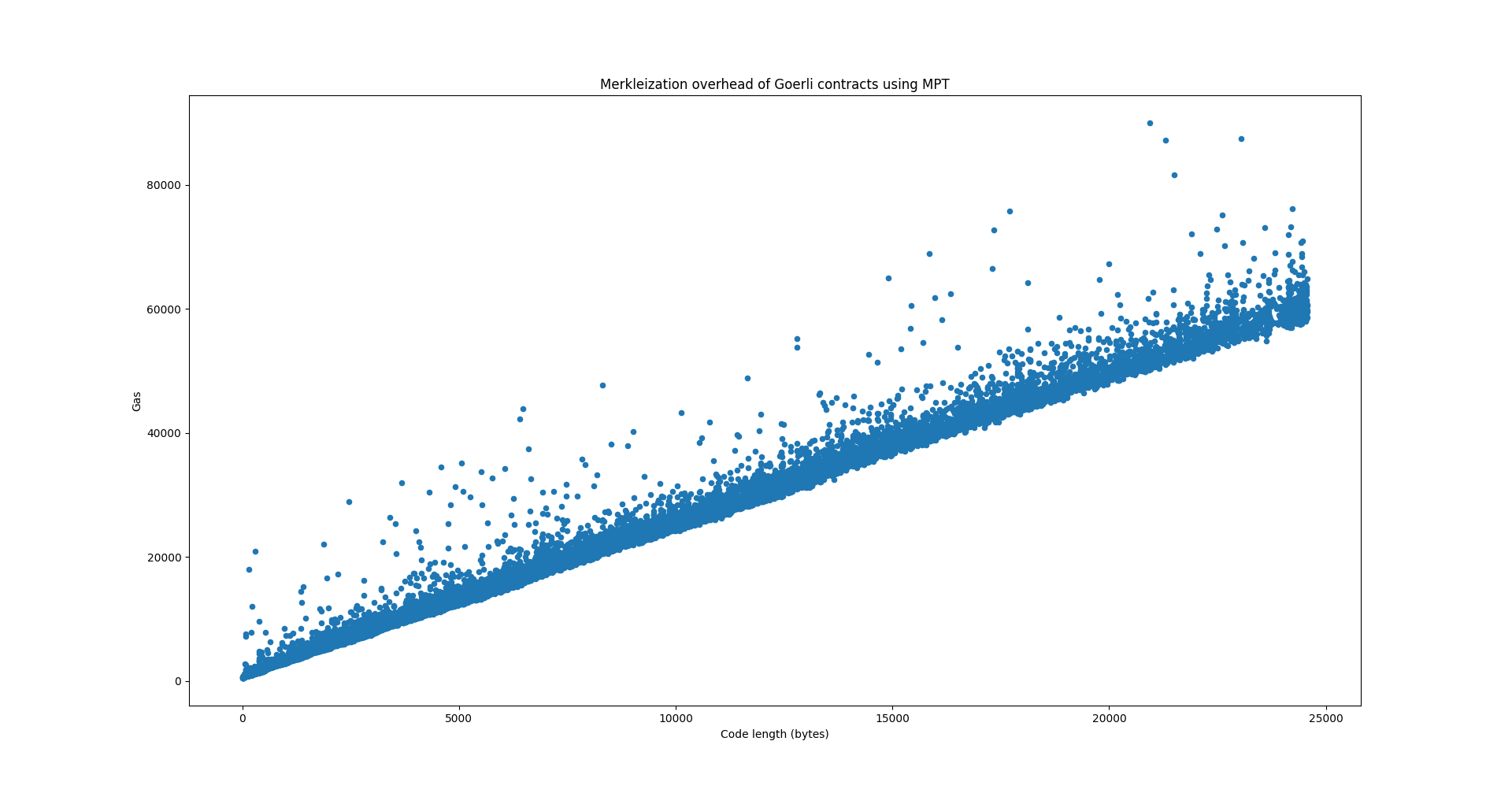
I implemented the merkleization logic in a fork of geth and measured the overhead. The goal is to determine how much contract creation gas costs need to be bumped.
The following chart shows the merkleization overhead in terms of gas in relation to the contract size, for all contracts on the Goerli testnet. Gas was computed by measuring the runtime and comparing it against the runtime of the ECRECOVER precompile on the same machine.
Here we used the hexary MPT for the code tree as specified currently in the EIP. As expected the runtime rises linearly with code size. Currently contract creation costs 200 gas per byte of code. By increasing that number to 203 we can cover this overhead. Or because the overhead is not that significant not bump the gas cost at all.
But we don’t plan to use the hexary MPT for code. There are 3 options: SSZ, a simple merkle tree, the binary trie. Here I also experimented with the fastssz implementation and measured the overhead in a similar way as above.
Fastssz uses an accelerated sha256 implementation by default for hashing the tree. The column ssz_sha shows fastssz’s performance overhead when using the default hasher. ssz_keccak replaces the default hash function with geth’s keccak256 implementation. Interestingly both perform better than the MPT, even though binary trees incur more hashing. I think this might be because SSZ’s tree structure is more-or-less known at compile-time as opposed to the MPT.
The same measurement is pending for the binary trie and I’ll update the post once I have numbers on that.
There is a related proposal by @vbuterin to first introduce charging chunk costs. I took the liberty to share it here, given there’s an implementation in geth which links to it, and also an implementation in evmone.
Would this be an opportunity to start allowing smart contracts to refer to existing bytecode? That way, they could simply re-use already existing code and one could potentially a lot of storage as identical smart contracts could be deduplicated.
Coming to this thread after today’s ACDE call, I’m curious about the code localization aspect of this EIP. Isn’t there a strong negative impact to performance because each chunk needs a lookup from the kv db which equates to several random reads from disk? It may be that this has already been considered but it’s not clear to me from the EIP as written – paging @gballet. Like if each chunk needs a kv lookup, that should be reflected as a state read (i.e. 2100 gas or whatever the cost of SLOAD is) every 32 bytes.
Isn’t there a strong negative impact to performance because each chunk needs a lookup from the kv db which equates to several random reads from disk?
This has been answered during ACD: there is no assumption how the code is stored, it can still be loaded in one swoop if client performance can be maintained. Or in chunks ok 24kb. Or anything in-between. This is an implementation detail.
Like if each chunk needs a kv lookup, that should be reflected as a state read (i.e. 2100 gas or whatever the cost of SLOAD is) every 32 bytes.
Each chunk doesn’t need a kv lookup, but paying 2100 gas on each chunk is the whole point of the EIP.
 I’d like to float the idea of removing the RLP from the spec. It looks like the only places that RLP is used are:
I’d like to float the idea of removing the RLP from the spec. It looks like the only places that RLP is used are: