TLDR: The above post painted a rosier picture of the situation than I think is warranted. It concludes that “[we do not] see any deleterious effects from increasing individual blocksize by a factor of 65x” However, larger blocks are more likely to become uncles and this shows up in the data.
Larger blocks are more likely to become uncles
First off, thanks for doing the experiment, this is great data to have! Also, I love the idea of trying to create snappy-incompressible transactions with many zeroes, to eke out every additional byte you can.
I have an additional dataset to add to the above. I went back and tried to collect all the uncles which were created during the second experiment. During the ~22 hours for which the experiment ran[1], 5900 blocks were added to the canonical chain and 303 [2] uncles were created, for an uncle rate of ~0.0514 (For easier comparison with the table below: 5% of the blocks became uncles). Unfortunately, I wasn’t able to find sizes for all those uncles, but by checking blockscout (example) I was able to collect uncompressed sizes for 225 of them.
| Block Size [3] | Canonical Blocks | Uncled Blocks | Uncle Probability |
|---|---|---|---|
| 0-128KB | 5393 | 200 | 4% |
| 128-256KB | 91 | 2 | 2% |
| 256-512KB | 241 | 11 | 4% |
| 512KB - 1MB | 115 | 7 | 6% |
| >1MB | 60 | 5 | 8% |
I should ask you not to take the right-most column very seriously. For one, there are 78 uncles for which I was not able to find a size, so these uncle probabilities are underestimates. Also, this is a tiny amount of data! If, by chance, 3 blocks over 1MB instead of 5 had been uncled the rate would appear to be 5%. If 7 had been uncled the rate would appear to be 11%. Without more data it’s hard to say what true uncle rate for blocks this big is, though I’d be surprised if it was outside 5-11%.
However, even though the rightmost column isn’t very precise I think its trend contradicts the conclusion that we can continue to reduce gas costs without concern, this experiment didn’t rule out the possibility that increasing block sizes to 1MB could double the uncle rate.
Why didn’t this effect show up in etherchain.org/correlations chart?
The etherchain chart averages an entire days worth of data and a lot happens each day, more than enough to overwhelm whatever signal was in this experiment. Below is the block size distribution on Jan 11 (when the experiment was not running) and on Jan 12 (when the experiment was running). Both charts show the same dataset but the top chart is zoomed in, it doesn’t show blocks above 100KB in size:
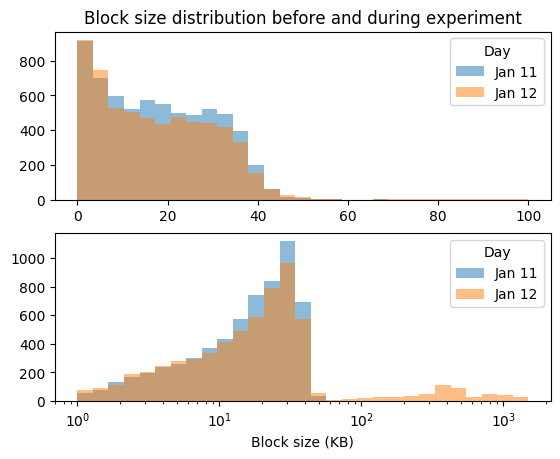
The distributions on Jan 11 and 12 are incredibly similar! The day of experiment had a few large blocks but not enough to meaningfully change the block size distribution.
Another way to see this is by looking at the medians. The median block size on Jan 11 was 17358.5 bytes. Jan 12 had a median block size of 18493 bytes, just 1134.5 bytes higher.
If every block over 1MB had been uncled the uncle rate for Jan 12 would have been 0.01 higher and would still look completely normal on the etherchain correlations chart.
Why didn’t this effect didn’t show up in the brother chart? (the last chart in the above post)
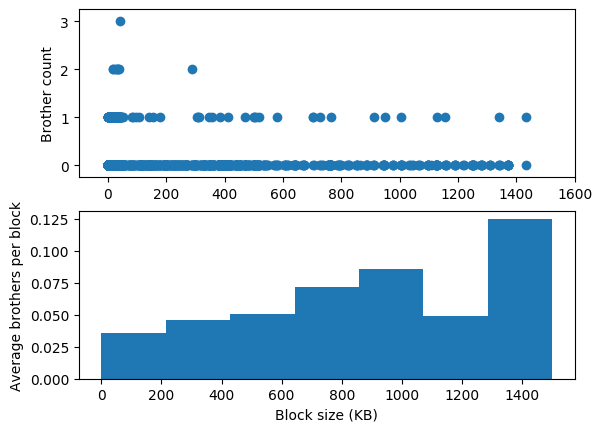
The following image has two charts. In the first chart I’ve reproduced the brother chart. There does not appear to be any relationship between block size and brother count, but there’s big confounder here, which is that there are many more blocks in the left part of this chart than in the right part. Understanding whether larger blocks are more likely to have brothers requires correcting for that difference in density, a task the eye does not excel at.
In the second chart, I’ve made the relationship between block size and brother count easier to see by grouping the block sizes into bins and reporting the average brother count across all blocks in each bin. This chart is also impacted by the difference in densities! There are fewer blocks in the buckets representing larger sizes, so their data is noisier and the trend isn’t consistent, but there does appear to be a trend.
Footnotes:
[1] The post says that the experiment started at block 9265746 and ended at block 9271645. There are a few more blocks above 1MB in size, the final one is block 9273973. I’ve used the original interval for everything in this post, including everything up to the last 1MB block doesn’t significantly change the results.
[2] Above I said there were 303 uncles during the experiment. If you look at the uncle hashes for all the blocks in this range you’ll find 315 hashes. The discrepancy is because I looked at all uncle blocks which had block numbers in the block range of the experiment.
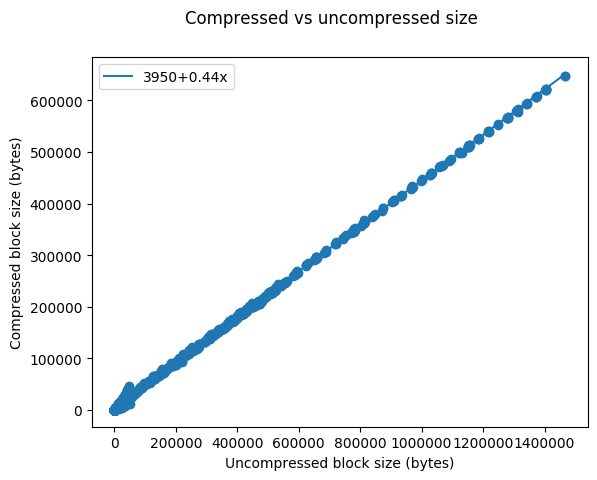
[3] For this entire post I’ll be using uncompressed sizes. This is roughly double the compressed size: