We published a Geth reference implementation for EIP2028: https://github.com/liorgold2/go-ethereum/pull/1.
Note that currently, in Geth, there is an artificial (i.e., non-consensus based) limitation of 32KB on the size of each transaction, and this bound needs to be increased to be consistent with this EIP. A pull request for such an increase already exists in https://github.com/ethereum/go-ethereum/pull/19618 and our new reference implementation for EIP 2028 relies on it (using a limitation that is appropriate to the new gas cost of call data). We are now working on the Parity implementation.
Notice that the gas cost currently stated in the reference implementation (16 gas per byte) may change once we finish analysing the simulation results which are still being collected.
Here’s the parity version of EIP 2028, for testing purposes. Notice that the transmission gas cost there (16 gas/byte) may be updated once we finish analyzing our test data (which we’ll publish next week).
Transmission Gas Cost Reduction – What Ethereum’s Mainnet Has to Say
TL/DR
Analysis of block size vs. uncle rate on Ethereum, including our high-load test conducted on Mainnet on Monday July 15 2019, supports EIP 2028 and the new gas cost of 16 gas per byte. In fact, this data suggests that gas cost can be further reduced in the future.
Introduction and the Parity update of March 2019
As we explained in the EIP 2028 description, reducing the gas cost of transmission will allow larger blocks and this might affect network security, as measured by uncle rate. To start the discussion, lets review on Etherchain the correlation between average daily block size and uncle rate.
The Parity update
In March 2019 Parity modified its block propagation method. Prior to the change, a Parity node would process a block before sending it on the network. After the change, Parity nodes joined other nodes (Geth, pantheon, Nethermind) in transmitting blocks before processing them, once the following three conditions were met: (1) Block body matches the block header (txHash, uncleHash), (2) Proof Of Work in the header is valid, and (3) the block is on the longest PoW chain. The actual processing happens concurrently to this but does not prevent block propagation. This change caused a dramatic 3x reduction in uncle rate, and unlinked the linear correlation between block size and uncle rate that was evident before the change. More details are available in Vitalik’s tweet.
The plot below shows this dramatic effect. The pre-March 2019 points are colored blue and the post-March 2019 ones are colored red (the big red dot at the bottom right corner will be discussed later).
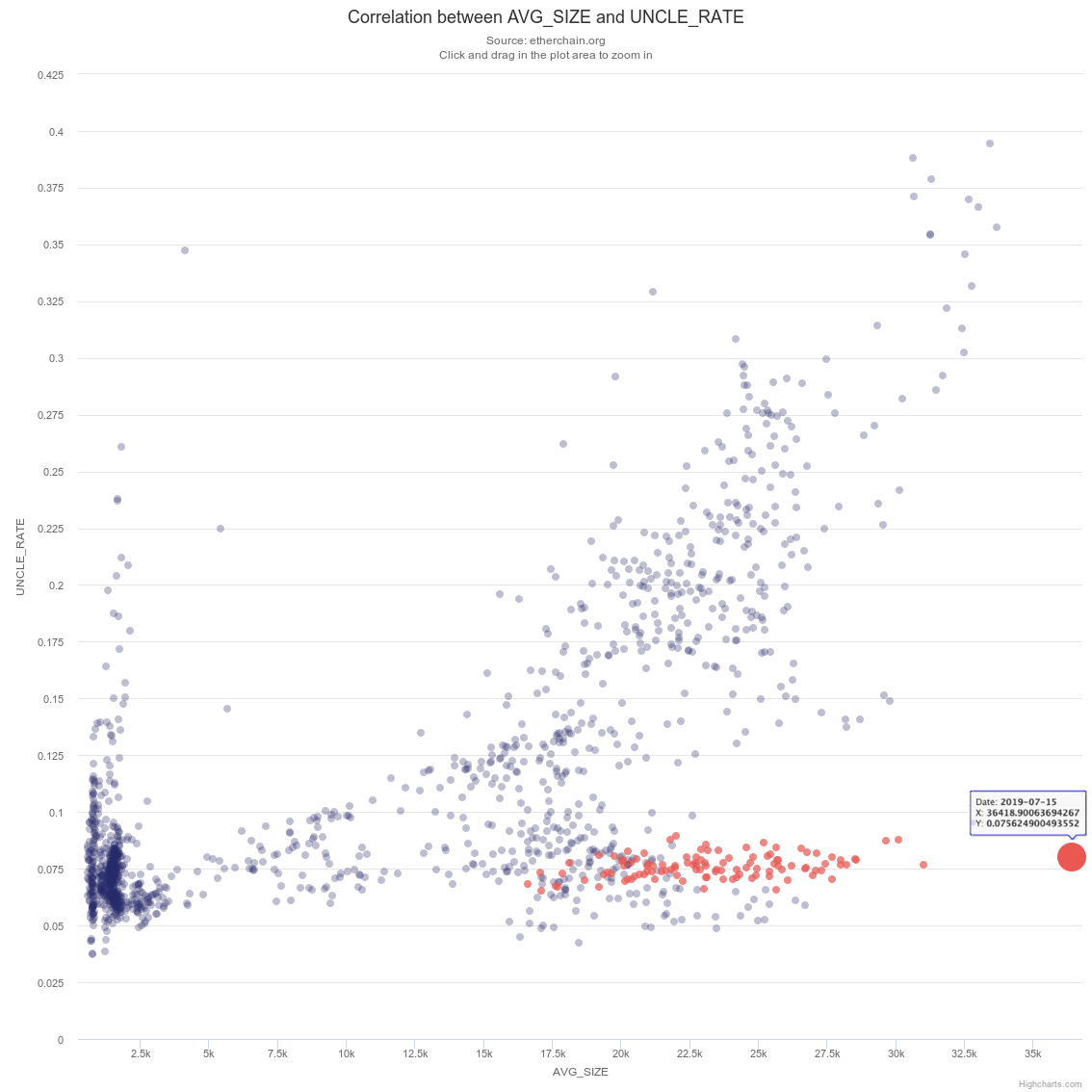
This plot originated from https://etherchain.org/correlations.
The Big Red Dot
StarkWare is responsible for the Big Red Dot, the increased average block size on Monday July 15 2019. (All our transactions originated from this address). That day also holds the Guiness World Record for largest average block size in Ethereum’s history, as seen clearly on the next plot taken from Etherchain. We explain the experiment that caused it, and what we learned from it, next.

The Experiment - A Bunch of Zeros
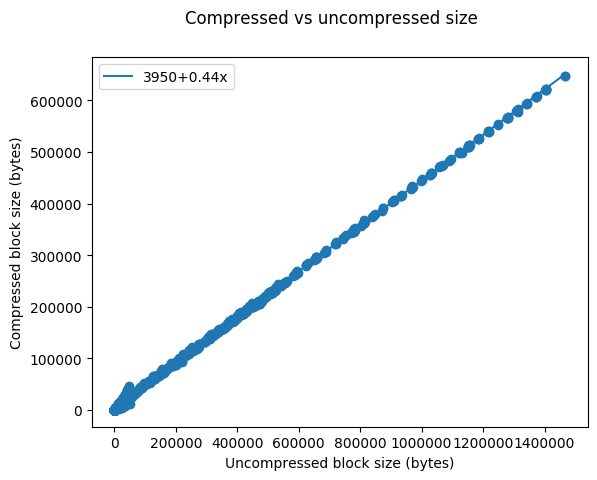
Not all bytes are equal on Ethereum. In particular, a zero byte costs only 4 gas (compared with 68 gas for all non-zero bytes). This allowed us to generate bigger blocks that have a low gas cost. Ethereum uses snappy compression so we had to be a bit careful to create blocks that have many zeros (and low gas cost) but cannot be compressed significantly (no more than roughly a factor 2x compression), though their gas cost was 5x lower than that of typical (or random) data.
On Monday July 15 2019, we generated a large number of such transactions and submitted them to Ethereum’s mainnet, to measure the effect of larger blocks on uncle rate. We created roughly 2,000 blocks that varied in uncompressed size between 45-534 KB. Here’s the first block in our experiment, here’s the last one and this is the largest one. But, as the the big red dot in the plot above shows, this long period of large blocks had little noticeable effect on the daily uncle rate.
Taking 20% daily uncle rate as an upper bound on acceptable uncle rate, we believe that gas cost can be reduced even below 16 gas per byte. This is the take-away message of the Big Red Dot. But now lets take a look at the experiment in greater granularity and see what we learn from it.
Big Red Dot in finer granularity
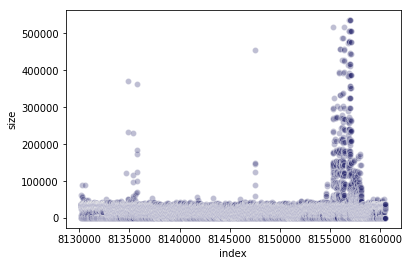
Here is a plot of the block size from recent days. The big peak towards the right comes from the blocks of our experiment (and prior peaks are our trials a few days earlier).
To parse this data at finer granularity, we took a small time window of 10,000 blocks and broke it into buckets of 50 blocks (roughly 11 minutes). The next plot shows uncle rate as a function of uncompressed block size. Bear in mind that the average uncompressed blocksize is 23KB, compressed to an average of 15KB. We maintained a similar compression ratio (of roughly 2x) for the blocks in our test, even though we managed to generate blocks that are 22x larger than the average (max-ing at 535 KB uncompressed). The buckets of 50 consecutive blocks during our experiment were up to 7.5x bigger than average. As can be seen, there is little to no effect on uncle rate per bucket.
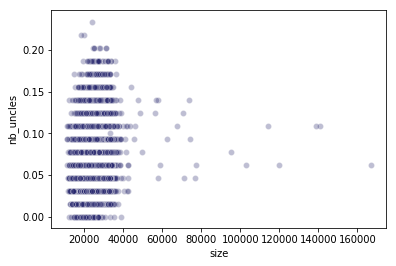
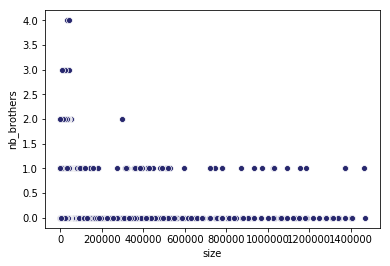
A block brother is a block that is not part of the main chain, but sits as the same height as another block (i.e., brothers are uncles, but attributed to individual mainnet blocks). The next plot shows brother count as a function of individual block size. Inspecting this plot, we still see no adverse effect of increased block size, even when average block size is larger than the average block size (of 25 KB) by a whopping factor of 22x.

Summary
To conclude, we see no adverse effect of increasing today the average block size by a factor of 7.5x, nor of increasing the individual blocksize by a factor of 22x. Based on this, the conservative choice of reducing transmission gas cost by a factor of roughly 4x, to 16 gas per byte, is well-founded. Our code modifications for Parity and Geth have been posted earlier.
Great work!
To make L2 scaling (i.e. stateless or state-minimized contracts with data stored off-chain and only a 32-byte stateroot stored in the contract) competitive with storing data on-chain using SSTORE, the cost originally suggested by @Recmo was “100 gas per word” or 3.125 gas per byte (see summary post here and proposal here).
The number is based on the size of a merkle proof assuming a depth 32 binary trie and 32-byte hashes (total bytes = trie_depth * hash_size = 1024 bytes). At 16 gas per byte the data cost of a proof would be 1024 * 16 = 16384 (brought down from 1024*68 = 69632), but 16384 is still not competitive with 5000 gas for an SSTORE.
Proofs can be batched/de-duplicated with a varying amount of reduction (depending on where the accounts are in the trie), so in some circumstances 16 gas per byte might be cheap enough to be competitive if proofs are batched.
To bring the last part of the discussion about the EIP, here are our history and sync analysis after the hardfork.
The effect of reduced transmission gas cost on blockchain history accumulation and full nodes
EIP 2028 reduces gas cost of data 4x (to 16 gas/ byte) and we believe this is safe in terms of its effect on network security (as argued here). A different concern might be the effect on blockchain history accumulated by full nodes and archival nodes that maintain this data. On this matter, we believe our conservative 4x gas reduction is safe, for the following reason.
Current accumulation rate
Let’s start by examining the average growth in history per block on full nodes and on archival ones. If you take the total growth seen in the month starting on May 17 2019 and ending on June 17 2019 (on Etherscan) and divide it by the number of blocks, you get that each block adds roughly 100 KB to a full node and 1 MB to an archival node. Over the same time period, the average (and median) block size was roughly 23 KB, so we see that transmission accounts for no more than 25% of history accumulated on a full node and no more than 2.5% of the history accumulated on an archival one. (Calldata requires the same storage volume on both full nodes and archival ones.)
The impact of EIP 2028 on accumulation rate
EIP 2028 reduces transmission gas cost roughly 4x, so it will likely increase block size by roughly 4x. Assuming all other storage components remain the same, according to this calculations an average block size will add roughly 175 KB to a full node, less than doubling the history accumulation rate. For archival nodes the history accumulation rate will increase by roughly 10% to roughly 1.1 MB.
The impact of EIP 2028 on sync
To best of our knowledge, the main bottleneck in syncing is due to state updates (see here for background on syncing). Therefore, even in the worst case scenario of a 2x increase in the accumulation rate of full nodes due to larger block size, we do not anticipate significant increase in sync time. In fact, since EIP 2028 will likely move stuff from storage to transmission, we conjecture that our EIP will improve (decrease) sync time.
Conclusion
Since Ethereum’s mainnet was launched in July 2015 (4 years ago), storage capacities per dollar have more than doubled. Therefore we believe that a worst case 2x increase in the storage needs of full nodes, and a 10% increase for archival nodes, is reasonable.
Thanks!
As we explained, we remain conservative in our approach. Since the timeline before Istanbul is quite short, we want this first modification to go through and if necessary, push further the reduction in the next one.
16 gas is already a large reduction and our data shows that it does not impact the security.
Ideally, we would not apply all of this gas reduction to the current transaction type, given that we need to incentivize the switch to the EIP-1559 transaction type.
As I understand it, this is already being discussed with
EIP implemented in aleth https://github.com/ethereum/aleth/pull/5691
Can we get the EIP updated with the agreed upon number?
I’m not quite sure I fully understand the change (sorry for my ignorance), but doesn’t this require to also reduce the available gas of the fallback function (currently being 2300)?
This change is only about the transmission cost, aka the cost of sending data to the chain. Today, the max block size is around 120kb (for a normal string of random bytes). This change will make possible to upload up to 480kb. Keep in mind that blocks on Eth are not defined by their max size but by the gas limit.
I don’t see how the fallback function needs a change.
EIP implemented in trinity https://github.com/ethereum/py-evm/pull/1832
I have reviewed this EIP. Everything looks great. And this is a good and clear model for future repricing arguments, thank you.
A typo. Quick fix --> https://github.com/ethereum/EIPs/pull/2422
EIP2028 - Post Istanbul/Muir Glacier Hardfork-- What Ethereum’s Mainnet Has to Say
TL/DR
Post Hardfork analysis of block size vs. uncle rate on Ethereum, including our high-load test conducted on Mainnet on Sunday January 20 2020, confirms our EIP-2028 Pre Hardfork analysis and suggests the network can even tolerate further reductions in transmission gas cost.
Introduction and the Hardforks timeline
On December 8th 2019 and January 2nd 2020, Ethereum upgraded respectively to Istanbul and Muir Glacier. EIP-2028 got included in Istanbul and Muir Glacier brought back the network to normal block time. On January 12th 2020, StarkWare proceeded with a post-upgrade analysis.
As argued in EIP 2028, reducing the gas cost of transmission would allow larger blocks and could affect network security, as measured by uncle rate. As previously, we use Etherchain as an independent source to analyse the correlation between average daily block size and uncle rate.
The plot below shows this correlation. The pre-March 2019 points are colored blue, the data between March 2019 and November 2019 is orange, and the latest data points are in red.
We will remind the readers that the drop in Uncle Rate compared to prior to March 2019 is mainly due to Parity propagation change as expressed previously. (Update: Vitalik’s link is broken and the bug was fixed in January 2019. Thanks to @evan_van_ness for the edit. Here is the link to the Parity github issue).
An additional observation can be made about the relative drop in November and December which is believed to be due to the Difficulty Bomb that was delayed with Muir Glacier.
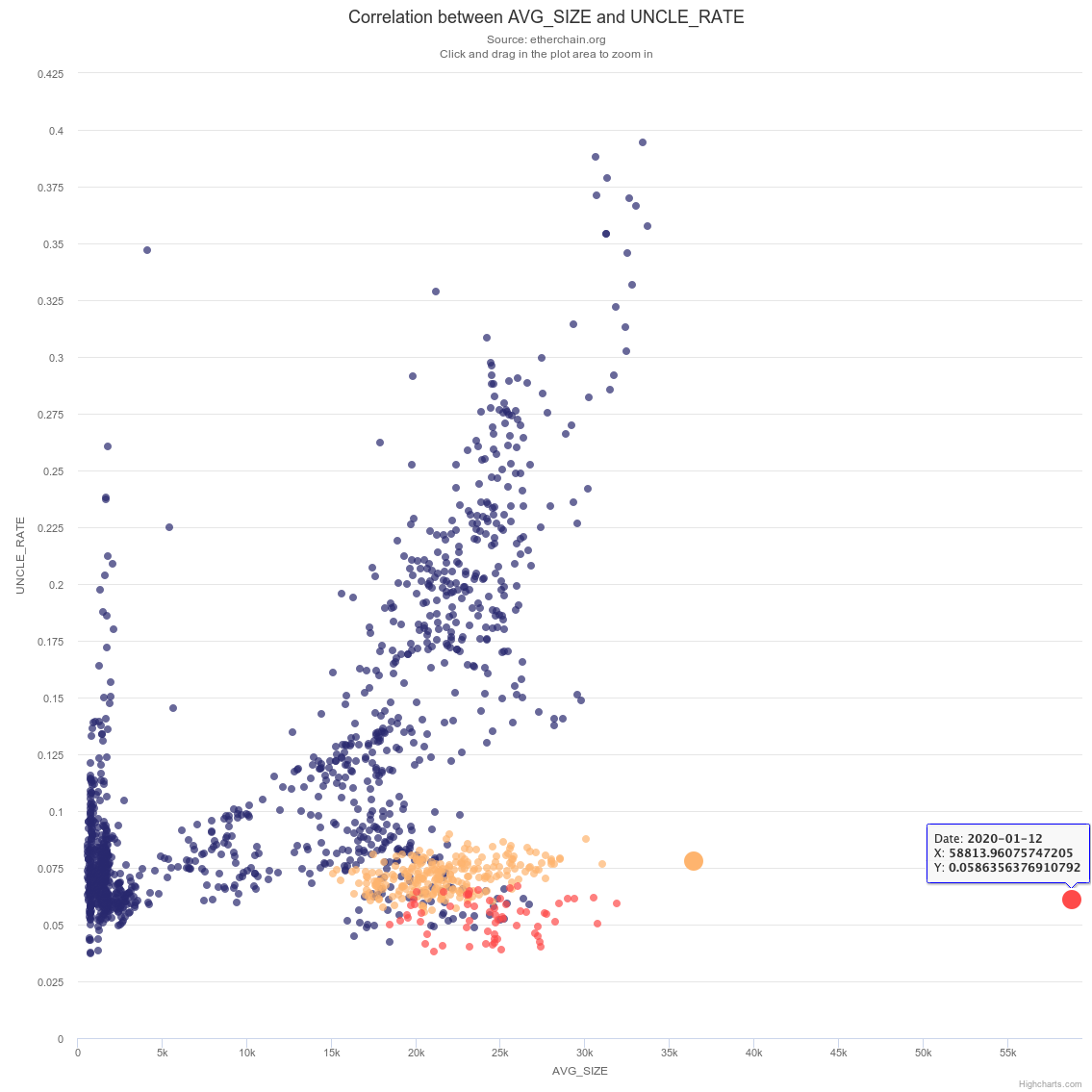
This plot originated from https://etherchain.org/correlations.
The Big Dots
In our previous analysis, we created (and analyzed) what was then the day with the largest average blocksize in Ethereum’s history and observed the very limited impact of increased blocksize on Uncle Rate. On January 12 2020 (after Istanbul and Muir Glacier), we repeated the experiment. Thus, StarkWare is also responsible for the new Big Red Dot.
As seen above, the average blocksize on January 12th was roughly twice as large as the previous world record, which resulted from our previous experiment in July 2019. Here’s another view of this, from Etherchain.
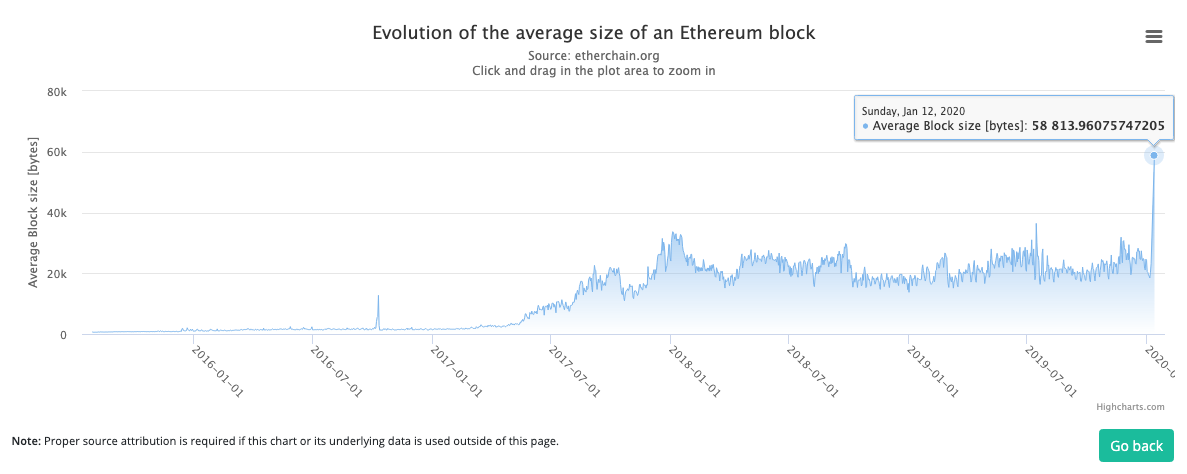
In more detail, on Sunday January 12th 2020, we generated a large number of such transactions and submitted them to Ethereum’s mainnet, to measure the effect of larger blocks on uncle rate. These transactions were included within roughly 6,000 blocks, that varied in uncompressed size between 45KB-1.46MB. Here’s the first block in our experiment (114,513 Bytes uncompressed), here’s the last one (436,908 Bytes uncompressed) and this is the largest one (1,467,727 Bytes uncompressed). But, once again, despite an increased average size of roughly 2x, the big red dot in the plot above shows that this long period of large blocks had little noticeable effect on the daily uncle rate.
As a consequence, StarkWare believes that this analysis empirically proved the soundness of EIP-2028.
Big Red Dot in finer granularity
Here is a plot of the block size from the time of the previous experimentation (July 2019) to January 13th 2020. The two main peaks come from the blocks of our Pre and Post Istanbul experiments (the peak right before block 9000000 was an experiment we started and then terminated due to the acknowledgement of the Difficulty Bomb influence on the resulting numbers).

To parse this data at finer granularity, we took a small time window of 10,000 blocks and broke it into buckets of 50 blocks (roughly 11 minutes each). The next plot shows the uncle rate as a function of uncompressed block size. Bear in mind that the average uncompressed blocksize is 23KB, compressed to an average of 15KB. We maintained a similar compression ratio (of roughly 2x) for the blocks in our test, even though we managed to generate blocks that are 65x larger than the average (max-ing at 1.46MB uncompressed). The buckets of 50 consecutive blocks during our experiment were up to 21x larger than average, improving on our previous largest bucket (from our pre-Istanbul experiment) by almost 3x. As can be seen, there is little to no effect on uncle rate per bucket.
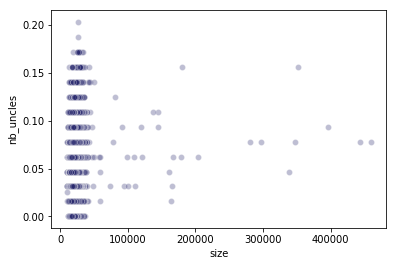
A block brother is a block that is not part of the main chain, but sits at the same height as another block (i.e., brothers are uncles, but attributed to individual mainnet blocks). The next plot shows brother count as a function of individual block size. Inspecting this plot, we still see no adverse effect of increased block size, confirming the same prediction from our previous analysis.
Summary
To conclude, increasing the average block size by a factor of 20x shows no adverse effect on the security of Ethereum’s Mainnet (Post-Istanbul§ and Post-Muir-Glacier), nor do we see any deleterious effects from increasing individual blocksize by a factor of 65x. Based on this, we believe that the new gas cost of data transmission adopted with EIP-2028 was well-founded, and even further gas reductions seem warranted (to be discussed by the community later).
TLDR: The above post painted a rosier picture of the situation than I think is warranted. It concludes that “[we do not] see any deleterious effects from increasing individual blocksize by a factor of 65x” However, larger blocks are more likely to become uncles and this shows up in the data.
Larger blocks are more likely to become uncles
First off, thanks for doing the experiment, this is great data to have! Also, I love the idea of trying to create snappy-incompressible transactions with many zeroes, to eke out every additional byte you can.
I have an additional dataset to add to the above. I went back and tried to collect all the uncles which were created during the second experiment. During the ~22 hours for which the experiment ran[1], 5900 blocks were added to the canonical chain and 303 [2] uncles were created, for an uncle rate of ~0.0514 (For easier comparison with the table below: 5% of the blocks became uncles). Unfortunately, I wasn’t able to find sizes for all those uncles, but by checking blockscout (example) I was able to collect uncompressed sizes for 225 of them.
| Block Size [3] | Canonical Blocks | Uncled Blocks | Uncle Probability |
|---|---|---|---|
| 0-128KB | 5393 | 200 | 4% |
| 128-256KB | 91 | 2 | 2% |
| 256-512KB | 241 | 11 | 4% |
| 512KB - 1MB | 115 | 7 | 6% |
| >1MB | 60 | 5 | 8% |
I should ask you not to take the right-most column very seriously. For one, there are 78 uncles for which I was not able to find a size, so these uncle probabilities are underestimates. Also, this is a tiny amount of data! If, by chance, 3 blocks over 1MB instead of 5 had been uncled the rate would appear to be 5%. If 7 had been uncled the rate would appear to be 11%. Without more data it’s hard to say what true uncle rate for blocks this big is, though I’d be surprised if it was outside 5-11%.
However, even though the rightmost column isn’t very precise I think its trend contradicts the conclusion that we can continue to reduce gas costs without concern, this experiment didn’t rule out the possibility that increasing block sizes to 1MB could double the uncle rate.
Why didn’t this effect show up in etherchain.org/correlations chart?
The etherchain chart averages an entire days worth of data and a lot happens each day, more than enough to overwhelm whatever signal was in this experiment. Below is the block size distribution on Jan 11 (when the experiment was not running) and on Jan 12 (when the experiment was running). Both charts show the same dataset but the top chart is zoomed in, it doesn’t show blocks above 100KB in size:
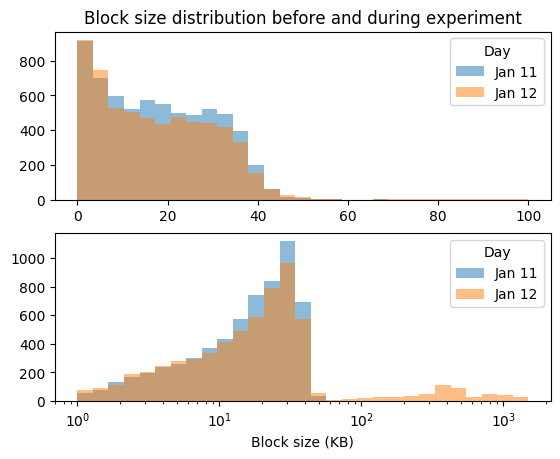
The distributions on Jan 11 and 12 are incredibly similar! The day of experiment had a few large blocks but not enough to meaningfully change the block size distribution.
Another way to see this is by looking at the medians. The median block size on Jan 11 was 17358.5 bytes. Jan 12 had a median block size of 18493 bytes, just 1134.5 bytes higher.
If every block over 1MB had been uncled the uncle rate for Jan 12 would have been 0.01 higher and would still look completely normal on the etherchain correlations chart.
Why didn’t this effect didn’t show up in the brother chart? (the last chart in the above post)
The following image has two charts. In the first chart I’ve reproduced the brother chart. There does not appear to be any relationship between block size and brother count, but there’s big confounder here, which is that there are many more blocks in the left part of this chart than in the right part. Understanding whether larger blocks are more likely to have brothers requires correcting for that difference in density, a task the eye does not excel at.
In the second chart, I’ve made the relationship between block size and brother count easier to see by grouping the block sizes into bins and reporting the average brother count across all blocks in each bin. This chart is also impacted by the difference in densities! There are fewer blocks in the buckets representing larger sizes, so their data is noisier and the trend isn’t consistent, but there does appear to be a trend.
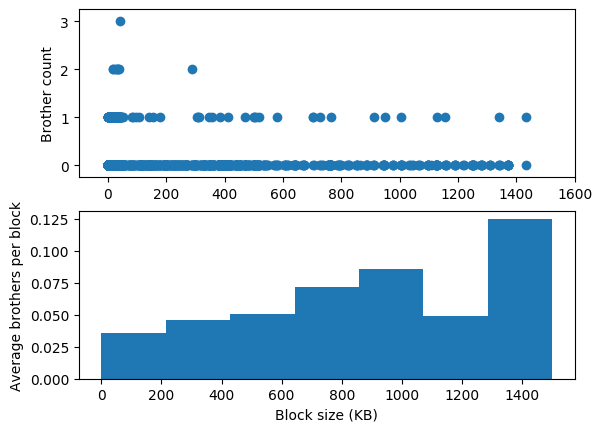
Footnotes:
[1] The post says that the experiment started at block 9265746 and ended at block 9271645. There are a few more blocks above 1MB in size, the final one is block 9273973. I’ve used the original interval for everything in this post, including everything up to the last 1MB block doesn’t significantly change the results.
[2] Above I said there were 303 uncles during the experiment. If you look at the uncle hashes for all the blocks in this range you’ll find 315 hashes. The discrepancy is because I looked at all uncle blocks which had block numbers in the block range of the experiment.
[3] For this entire post I’ll be using uncompressed sizes. This is roughly double the compressed size: