This topic is intended be the discussion for EIP-1380. Any comment or feedback is very much appreciated!
1 Like
Seems like a common sense win to me. @axic is there truly zero cost associated with resetting the state/memory in a call to self?
Vyper has been using calls to self for memory safety, cost has been pushing them to move away from that approach. I’m glad to see there is interest from other projects in this.
1 Like
The proposed use case is cited as a contract calling itself to achieve memory safety while reducing gas cost.
If that is the case, I would like to ask to see an example contract implemented using current best practice of JUMP with the same contract implemented using CALL. This will help find practical contract development issues using this new approach. Also it will help quantify the benefit.
Additionally, the unstated assumption in EIP 1380 is that having a contract CALL itself would serve a useful purpose. Currently I cannot think of useful purposes for this feature.
Specifically, there is ABI function call (OUTER) that wants to do something and it relies on another ABI function call (INNER) to help it. In this case, INNER will not be able to authenticate the beneficial message caller. Will the proposer please offer several contracts that are deployed to mainnet to be analyzed? I will be surprised if any meaningful contracts actually on mainnet would be useful if deployed using CALL to self.
If compensating workarounds are required to make CALL to self work then let’s discuss this in our analysis of these specific contracts. It may be that additional SSTORES are required to do any meaningful tasks. If that is the case then I would consider EIP1380 a case of premature optimization.
I am not sure this is something that we can do, vyper uses CALL (except my work that was done for #901) and solidity uses JUMP. The underlying architecture being a layer lower, we cannot say implement two examples showing one above the other unless we alter the compilers… which I can show you once the 901 is completed and passes all tests - still not sure what this would achieve then?
It would be the job of the separate languages to make the switch the CALL not change anything from the perspective of the contract writer. For vyper the msg.sender being different to solidity, is still an issue I would address (but is outside the scope I would say).
If compensating workarounds are required to make CALL to self work then let’s discuss this in our analysis of these specific contracts. It may be that additional SSTORES are required to do any meaningful tasks. If that is the case then I would consider EIP1380 a case of premature optimization.
Just to clarify no SSTORES will ever be required as we can just pass information to the internal/private functions as parameters. The only issue would be the concept of msg.sender.
INNER function call could easily do any form of authentication using a parameter (but to keep the behaviour of solidity the same msg.sender the same as previous versions it could be passed through as a parameter, with minimal gas cost).
As the proposal motivates, there are significant benefits in having a clean VM state every time you enter a new function, especially because the VM already has the mechanics in place to do actual function calls, having to re-implement call logic on the bytecode level of a contract, because of gas costs, adds just another layer of complexity, and therefore just another layer of issues that could occur.
Also there is the issue of filling up the stack with context variables/memory state.
I will hopefully have the vyper branch done soon, and we can then do some more comparisons if that is useful?
In the case of JUMP the compiler has to ensure that the called function will not change memory (e.g. the entire memory before the operation and after it is equivalent, but the during the function it may change…).
Doing this currently is not implemented in Solidity as it requires a more comprehensive static analyzer or as a simple solution it can disallow anything which uses mstore. That in practice however severely restricts the usefulness of such functions.
The EIP may not have been clear enough, but the reduction happens for all CALL* instructions, including DELEGATECALL, etc. where the context remains mostly the same (with the exception of msg.sender).
1 Like
This EIP would enable quite a deep recursion, are we sure this won’t be a DoS vector? 8M gas with this EIP would permit 200K nestings vs. <12K currently.
1 Like
Call depth is limited to 1024.
This was discussed on ACD#46 (in September 2018) where it was suggested that optionally this could be more generalized:
Going as far as saying, gas cost for accessing an account already accessed in same block goes down from 700 to 40, potential to do this in the long term
I did some benchmarking on geth: https://gist.github.com/holiman/0662916aab57fb9a3b5d74703c0620cd .
TLDR; I don’t think 40 is sufficiently conservative
1 Like
Thanks for doing this @holiman!
I’ve mentioned on ACD yesterday that geth seems to not have a quickest path for precompiles and instead goes through some of the state db abstraction. As a result I wasn’t hopeful to keep the numbers proposed in the EIP.
@holiman your gist shows the time post-change (1.18s and 1.24s), but doesn’t for pre-change. What is the time spent currently?
I reran it now, invoking it twice (to warm up some cache pools). The 1380 variant
Time elapsed: 1.141062849s
Time elapsed: 1.050492986s
The current (700 gas) variant:
Time elapsed: 105.225522ms
Time elapsed: 94.752792ms
I also took a cpu profile of the execution for 1380, result is below:
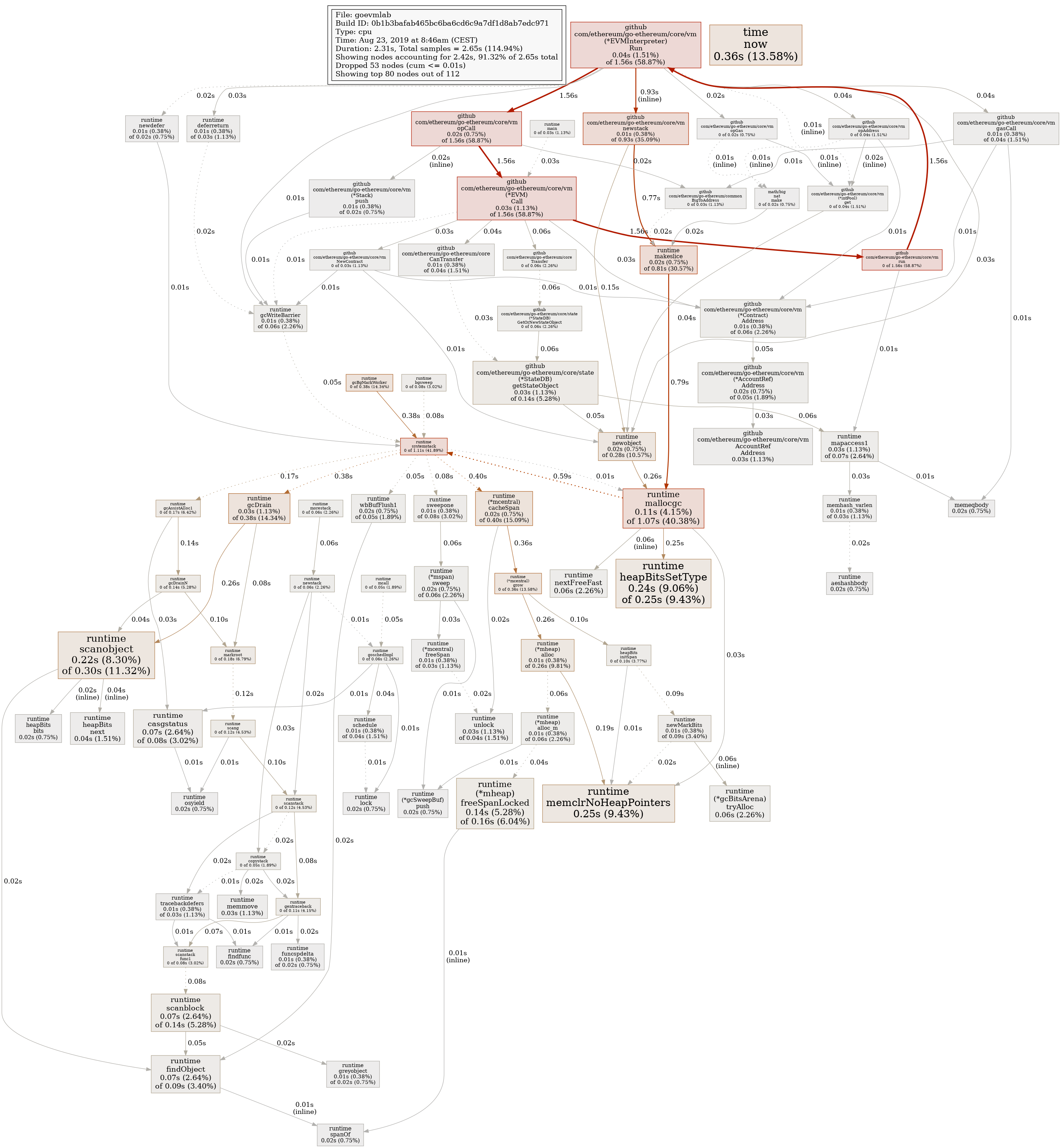
I’m sure we can optimize it, but it’s hard to say how much. It appears a lot of the time is spent on garbage collection
Note: the large time spent on time.Now may be related to runtime/pprof: give more useful profiling output for time.Now (and other vDSO functions) on Linux · Issue #24142 · golang/go · GitHub (my os is qubes, so all machines are virtual)
1 Like
Here’s more info about it, which makes it possible for anyone to play with it: https://github.com/holiman/goevmlab/tree/master/examples/calltree
Damn, I keep confusing EIP numbers – the above stands for EIP-2046: Reduced gas cost for static calls made to precompiles
The funny thing is that you first confused it on ACD gitter, then you did the exact same thing again here ![]()
My mind is on benchmarking 2046 and not 1380 
It would be interesting to see how geth performs in a repeated call to different addresses, for comparison. To get accurate readings for this we would probably need to perform the testing in a setting with a large db though.