Client testing call #27, March 3rd 2025
Holesky Update
- Lodestar:
- No further bugs observed in last 4 days.
- Observed locally that Friday night participation appeared to drop below 10%.
- Nodes crashing appear to be causing the low participation rate
- Ethpandaops:
- Also experiencing crashing nodes
- All runners with lighthouse nodes out of disk space (due to lack of finality).
- Reth:
- 1K validators active but with minimal impact on network recovery.
- Also stopped running lighthouse nodes due to disk space issues.
- Teku:
- Encountered problems this morning, starting hitting overflows in fork choice.
- (Prysm: Perhaps subtracting the slash balance is causing the problem?)
- Grandine:
- Working on the observed memory growth issues.
- Prysm:
- Working on enabling syncing from head instead of justified checkpoint.
- Taking away a lot of learnings from this situation.
- Prysm nodes should come online soon.
- Shared spreadsheet and plots showing how long it’ll take for validators to be removed due to inactivity leak (also shared in #interop).
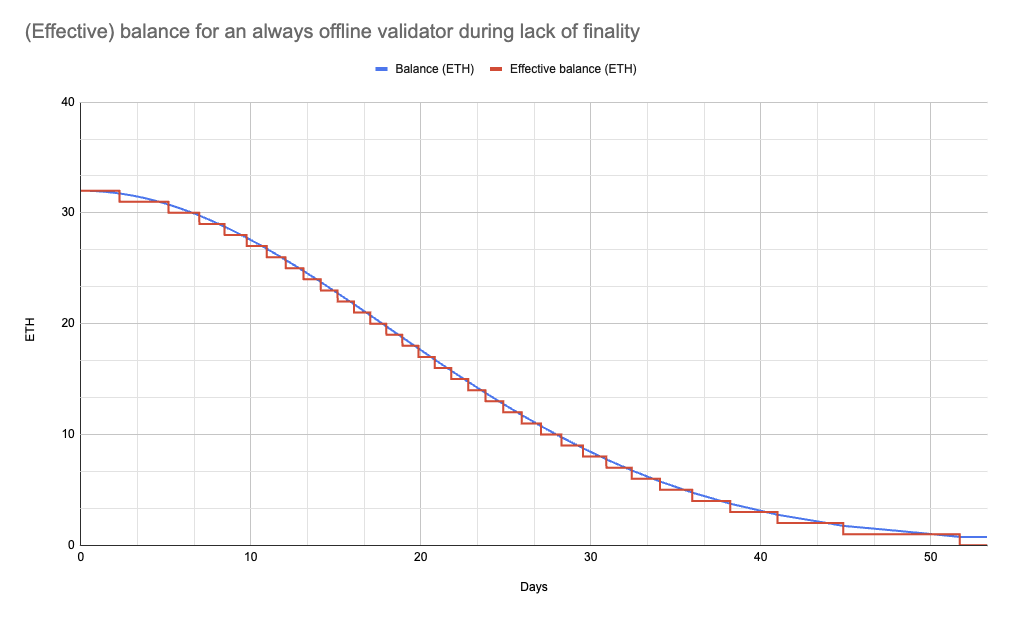
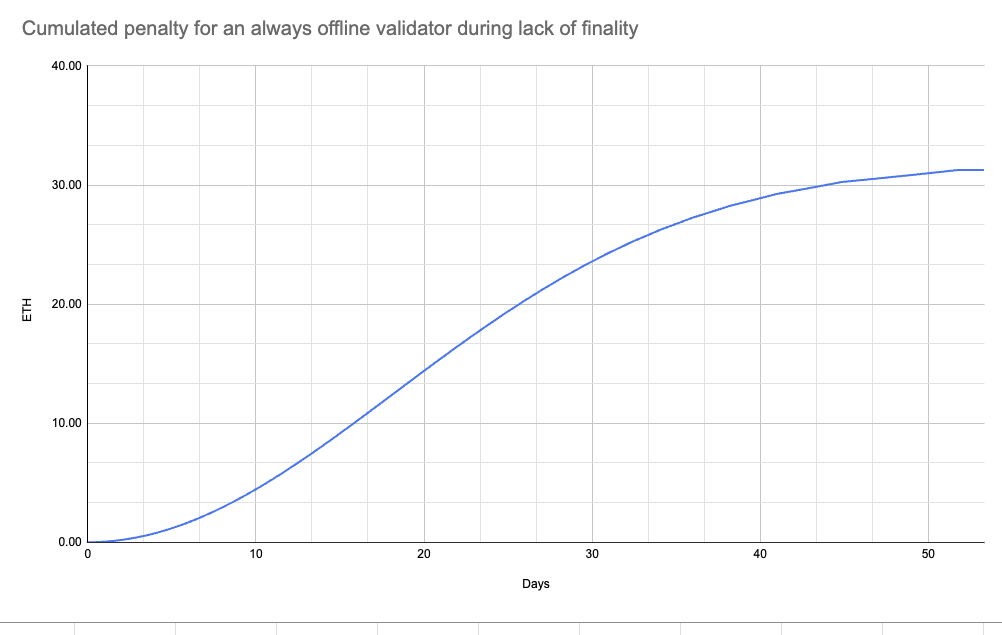
Slashing
- Lodestar:
- Slashings seem to be propagating, but only slashing 1-2 validators per block.
- Slashing more validators seems like a bad idea as the network will lose liveness.
- Prysm:
- New bug: If the incoming block is not a head block, slashing information is getting removed, which is not correct, because blocks then get built without slashing info. If the block is not head, we should not remove the slashing info. Sharing in case other client teams have the same issue.
- Mikhail: Keen to test mass slashing.
- Lodestar:
- We would prefer to not proceed with mass slashing yet, as we have fixes that we would like to test on the network first, in case liveness is lost.
EF Testing: - We can discuss on ACD/later when to do the coordinated slashing.
- Will need some planning and coordination.
- We would prefer to not proceed with mass slashing yet, as we have fixes that we would like to test on the network first, in case liveness is lost.
Holesky Shadow Fork
Geth:
- We plan to make a shadow fork of Holesky ran by ethpandaops.
- This can be used by staking services for testing consolidation requests.
- We should do the shadow fork before the mass slashing event(?)
- All nodes will be ran by ethpandaops initially, keys can be distributed to staking pools and clients later via mnemonic.
Reth: - All parties will lose a lot of testing capabilities: We should start a new testnet.
Pectra
Geth
- Two BLS issues detected:
- evmone issue found via fuzzing (by Martin from geth)
- nethermind issue found via bug bounty.
- 7002 issue/quirk reported (via the bug bounty; notes here, still being investigated - WIP):
- Potentially, the withdrawals queue can be over-filled as a possible DDOS attack vector.
- Potentially a large issue as it scales with the size of the block
- Would require a new contract deployment on mainnet, so a new address would need to mined leading to a potential for confusion.
- Prysm: This should be discussed with the staking pools (as it’s actually a potential attack on them.
EF:
Should we delay Sepolia? TBD in ACD.Edit: See this message in Eth R&D #announcements for more info:Sepolia node operators: the fork will happen as previously scheduled at epoch 222464 (Mar. 5, 7:29 UTC).
- Will reach out to the staking pools to discuss the 7002 issue.
EOF and PeerDAS
No topics discussed today.