(Written by @virgil ) Special Projects wishes greater Ethereum interopability with Zcash, IPFS, and Handshake. Coincidentally, all of these projects use the Blake2 hash function. So, this is our official request to add the Blake2b F precompile to the Istanbul hardfork. The first special project here will probably be creating a wrapped ZEC (WZEC) within Ethereum as well as wrapped Ether within Zcash. After that, some yet-to-be-determined bridge architecture will allow Ethereum to benefit from Zcash’s shielded transactions.
If there’s an issue of funding to get this over the finish line, I will personally cover the expenses.
This is mistaken. The Blake2 precompile is not superseded by EIP 1829. You’re thinking of EIP 665 (another precompile that has come up), which is superseded by EIP 1829. As far as I know, the current proposal is to put Blake2 into Istanbul and EIP1829 to be considered once it’s ready.
Below is an email I sent to Zooko after he showed interest in reviving the EIP. I think it sums up the general current process that a champion would need to go through to make this EIP a reality. It also has relevant links to previous attempts at the EIP:
A champion of an EIP is the someone who writes, creates tests for, and advocates for the EIP. Advocating for the EIP may involve attending an All Core Dev meeting that happens every other Friday. A champion doesn’t neccessarily implement the code entirely into every client, but they do list implementation examples in different languages at minimum.
When you previously tried to revive this in late 2017 Jay Graber contributed to the EIP that Tjaden Hess created in 2016. They made some good progress on the EIP, but there are some pieces missing such as the full spec, Ethereum test cases, and gas calculations. It also isn’t up to standard with the latest EIP formats. We will likely just use that thread (PR #131) to continue iterating on the EIP. Would Jay like to still be involved in this?
I am posting this message to a thread on the Fellowship of Ethereum Magicians, where EIP and other technical discussions take place. Here are some relevant links:
I think that IPFS and Handshake and other projects also require BLAKE2b so I think this would be a cool opportunity to get them involved too so it won’t be entirely on the back of ZCash and a few people to get this done.
In short, head to the Fellow of Ethereum Magicians forum post I linked to with any questions you have and we can get this going Anyone from your team who is going to help with this should coordinate on that forum unless it becomes a big enough group that a Gitter chat room is neccessary (which I can set up if needed).
Note: We have a deadline for EIPs accepted for our next hard fork in August. That deadline is the end of May so you will only have 1 month or so to complete the EIP if you want it in the next hard fork. Otherwise the one after would be 4-6 months from August most likely.
To justify the necessity of a new precompile, example inputs and outputs of desired use cases (for Zcash, IPFS, and Handshake) should be provided. Then an effort should be made to optimize an EVM implementation that processes the example inputs and outputs, and to analyze the computational bottleneck. The analysis should argue that the optimized implementation requires too much gas to compute the desired outputs, and that further optimizations of the EVM implementation are unlikely.
Also note that gas costs of computational EVM opcodes (as opposed to I/O opcodes such as SLOAD and SSTORE) are highly overpriced at present, for two reasons.
The first reason is because the block gas limit (currently at 8 million gas) simultaneously meters the computational workload and the I/O workload of each block. And under the current opcode gas cost table, 8 million gas of I/O workload already results in an uncomfortably fast rate of state growth. But the computational capacity of the average client is under-utilized. If state growth can be curtailed (e.g. by repricing SSTORE), then a strong case could be made arguing that miners should raise the block gas limit. Alternatively, rather than repricing SSTORE higher and raising the block gas limit, the block gas limit could stay the same and computational opcodes could be repriced lower. Either way would effectively lower the cost of computation and use cases that are currently just out of reach (e.g. 2x or 3x beyond the block gas limit) would become practical in EVM contracts, using the average client today.
Second, even after a repricing of computational workloads relative to what average clients could process today, it should be possible to achieve a significant amount of further reductions. An optimized EVM engine (such as evmone or cita-vm) is about 5x or 10x faster than the EVM implementations in the average client (geth and parity) today. If opcodes were repriced according to the speed of an optimized implementation, even more reductions in the gas cost table could be realized.
We would likely pick apart the bouncycastle implementation and figure out where Function F lives, like I did for Keccak f800. Their license is BSD like. They also focus on performance and some of their optimizations are unique to Java’s architecture.
I just wanted to follow up on @cdetrio’s post. I’ve been tinkering around with writing a Blake2b smart contract that can execute 512 compression rounds within the block gas limit.
The contract is written in Huff, and my latest iteration clocks in at ~6,821,545 gas for 512 rounds. I don’t think I’ll be able to get it much lower than that.
As @cdetrio mentioned, an optimized EVM engine can run the contract at a reasonable clip. I benchmarked the blake2b contract in evmone and, for 512 rounds, obtained a run-time of 7.062ms . At 6,821,545 gas, evmone will process the algorithm at a rate of 968,000,000 gas per second.
As a thought experiment, if opcodes were priced relative to an EVM engine like evmone, with a target of 10,000,000 gas per second, the blake2b contract would consume 70,470 gas for 512 rounds, or 138 gas per round.
With each round compressing 128 bytes, that’s ~34 gas per word, which seems pretty reasonable.
I submitted an updated PR. I can be PoC for the EIP until developers are decided and funded. I wanted to make sure it at least has a chance of getting into Istanbul by doing some of the legwork. https://github.com/ethereum/EIPs/pull/2024
If developers can’t be sourced and funded in time then it will have to wait for the next train.
The pull request contains the following Specification section:
Function accepts a variable length input interpreted as:
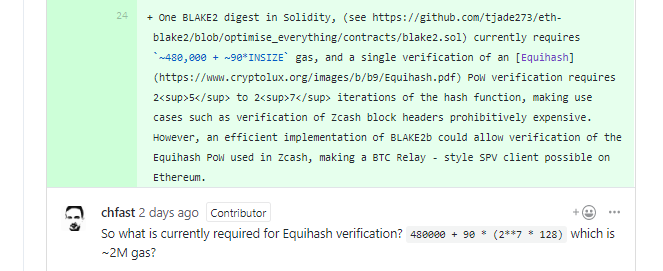
[OUTSIZE, D_1, D_2, ..., D_INSIZE]
where `INSIZE` is the length in bytes of the input. Throws if `OUTSIZE` is greater than 64. Returns the `OUTSIZE`-byte BLAKE2b digest, as defined in [RFC 7693](https://tools.ietf.org/html/rfc7693).
This description seems rather ambiguous. Is that array a byte array? Is OUTSIZE a single byte (uint8)? Does that mean INSIZE is the length of input and the first byte of the input is considered as OUTSIZE while the rest is the actual input to hash?
And the following gas costs:
Gas costs would be equal to `GBLAKEBASE + GBLAKEWORD * floor(INSIZE / 32)`
If INSIZE includes the configuration parameter of output hash size (OUTSIZE) shouldn’t this calculation be Gblakebase + Gblakeword + floor((INSIZE - 1) / 32)?
Additionally, and older version of the blake2b proposal had a more complex interface exposing a wider feature set of Blake2 and allowing for a more flexible precompile. The issue description of BLAKE2b `F` Compression Function Precompile · Issue #152 · ethereum/EIPs · GitHub still has that interface. I’m not sure which option is better, but perhaps we need to weigh which use cases the current precompile proposal can solve compared to the flexible design.
We are in the process of refactoring tjade273 ‘s go-ethereum implementation into a more recent version. That part of the spec will stay a bit ambiguous for now as we:
figure out why he choose those design principles
figure out if those are good reasons
decide if we should change the spec accordingly
benchmark, benchmark, benchmark
I imagine the spec he wrote and the actual code he wrote aren’t in sync either, so there is much to flesh out on this front.
Maybe I should take out the spec portion until we have a better defense for it? Or, at least mark it as WIP.
I’ll gather feedback on where in the spectrum of flexible and optimized we should target. (I don’t know if this is the trade-off we have yet but usually it is something like this). @virgil it would be great to hear from your team as you already have in mind implementaions for it.
After collecting a list of planned uses and possible use cases we can use that to narrow down the intersection of features and requirements.
It’s starting to look unlikely that this will be ready by Istanbul. That’s fine—zooko and I both had trouble acting on this quickly. This remains an ask, but it’s fine if it doesn’t go into Istanbul.
Yes, if I was going to give us an Istanbul inclusion rating it would be rated “low”, but we still have a few weeks before that is really decided.
We are going to do our darn’dest and see how it goes. I’m not going to cry if we don’t get in, but it is still worth the effort. A lot of work has already been done we can piggy back on.