However they can be implemented more efficiently with AVX512 or AVX512IFMA
They can’t
If you have an implementation with AVX512 or AVX512IFMA feel free to send it over, I will benchmark it against my library, or you can run the benchmark yourself:
However they can be implemented more efficiently with AVX512 or AVX512IFMA
They can’t
If you have an implementation with AVX512 or AVX512IFMA feel free to send it over, I will benchmark it against my library, or you can run the benchmark yourself:
And to further clarify myself(apologies for not making it clear earlier):
For the record, while RISC-V does not have the adc instruction directly, there are ways to achieve similar effect:
Solution 1: by chaining add and sltu, one can get similar code chains to add w/ adc: /godbolt.org/z/v165TYKqb
Solution 2: in CKB-VM, we have abused the idea of macro-op fusion (please use archive to look for s://riscv.org/wp-content/uploads/2016/07/Tue1130celio-fusion-finalV2.pdf ) and introduce adc to CKB-VM: /github.com/nervosnetwork/rfcs/blob/master/rfcs/0033-ckb-vm-version-1/0033-ckb-vm-version-1.md#42-mop
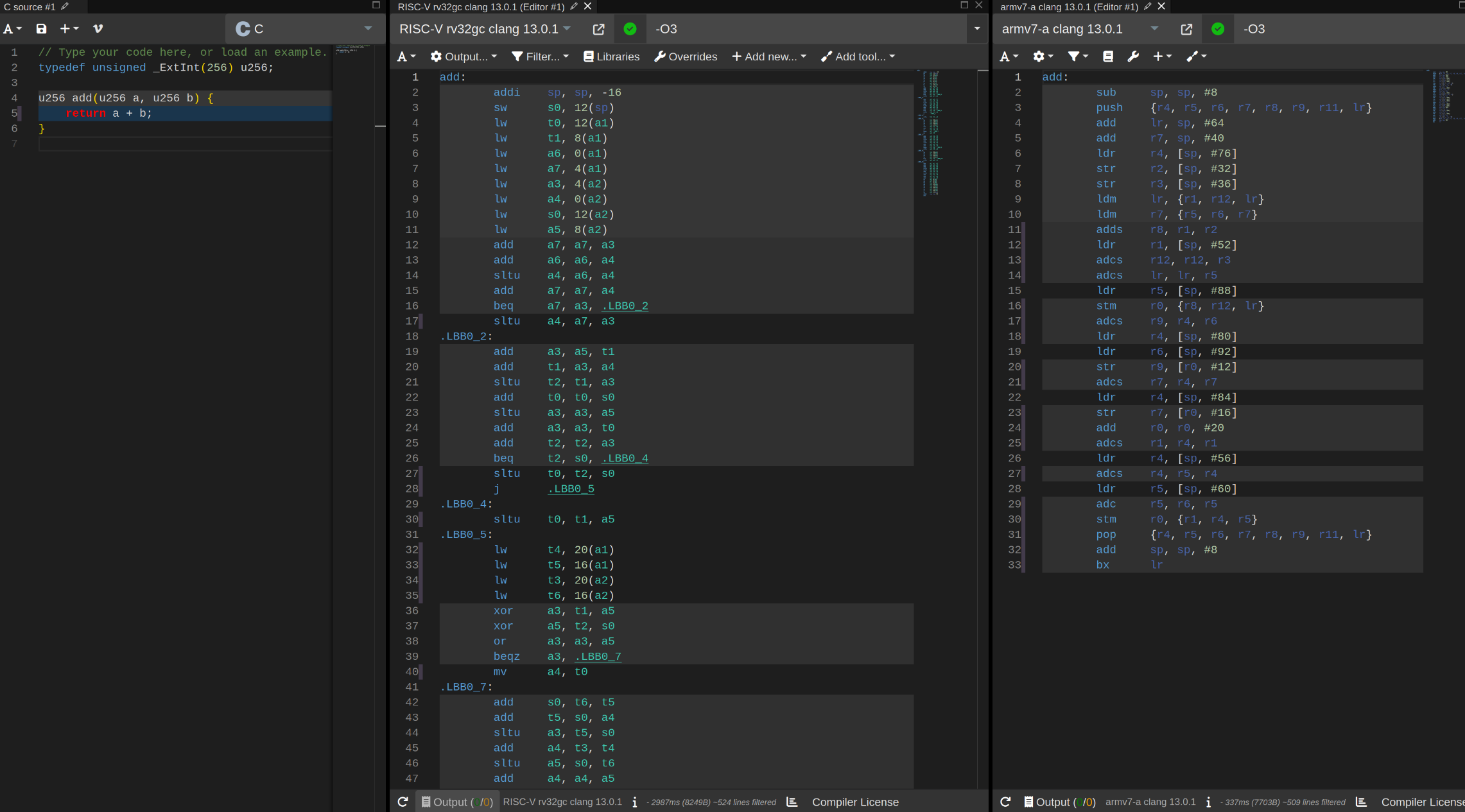
For 256-bit, RISC-V has a 2x longer trace than ARMv7: Compiler Explorer
using Clang 13 because afterwards, Clang stopped generating code for >128-bit integer with the C ExtInt/BitInt extension.
Solution 2: in CKB-VM, we have abused the idea of macro-op fusion
This is something that can indeed be implemented in an interpreter to reduce VM traces, though the precompile approach is already ubiquitous and more performant for most bottlenecks (cryptography, u256, hashes).
Yes. But I disagree that it’s the best we can do. (: The way to do it is to assume the worst case, and then extend the model to lower those costs in cases when we know it’s safe. If you assume the best/average case then you’re just opening yourself up to denial of service attacks. The fact that you haven’t had any problems so far only means that no one bothered to attack your chain yet, not that your gas metering is safe.
And what makes you think that on this hypothetical future RISC-V CPU the performance counters will be deterministic? (:
In fact, I can guarantee you that they will not be deterministic. The non-determinism of the performance counters is not an arbitrary decision that the hardware designers made; it’s a direct consequence of making a high performance, superscalar, pipelined, out-of-order CPU core with multi-level caches.
Yes, you can in theory add such performance counters to a CPU, but that means the CPU will have to be slow to keep the counters deterministic, so what’s the point of running on a slow CPU with deterministic hardware gas metering if we can get faster performance by doing the gas metering in software on a fast CPU?
This comparison is based on the rv32gc ISA. If you switch to rv64gc on the same page, the trace is actually smaller than ARMv7. I’m not certain why most RISC-V based zkVMs prefer rv32 over rv64, but larger registers naturally lead to fewer operations when handling 256-bit values. In the future, I hope to see more zkVMs based on RISC-V with 64-bit registers. RISC-V even has rv128 well defined which would lead to even fewer operations, although I’m not advocating for it given its limited support by the current compilers.
An ISA optimized for ZK would actually optimize for reducing those data movements.
I think this choice represents a fundamental trade-off between performance and tooling maturity.
Optimizing purely for speed would suggest creating a custom ISA tailored to ZK constraints, but this requires significant research, implementation, auditing and tooling development - ultimately creating higher barriers to adoption and taking more time to fully develop it.
Alternatively, using a stable, well-defined ISA like RISC-V leverages years of development and growing adoption. I believe this approach sacrifices some performance but significantly reduces implementation effort through existing tooling.
For a blockchain base layer intended to be open and widely adopted, I believe leveraging RISC-V’s openness and mature tooling ecosystem maximizes adoption. While custom ISAs may have their place in specific projects, for Ethereum specifically, I would prefer the path that offers greater developer freedom and broader adoption - which is the goal of open standard ISAs like RISC-V.
RISC-V is simple, yes — but not optimized for zero-knowledge. Custom ZK-friendly ISAs can outperform it significantly. There’s nothing inherently ZK-native about RISC-V other than being “not as bad as EVM.” Smaller opcode amount compared to WASM … but this also does not really matter as a’la’carte opcode selecting in proving schemes exist.
I wonder how is the problem of
This is exactly the point.
There are billions of dollars invested in all kinds of Solidity—from developer tools to security audits. The security of smart contracts depends on how widely the code is used.
Hundreds of thousands of people have learned Solidity.
Rust is a complex, general-purpose language, which makes security incredibly hard to achieve. There are simply too many moving parts.
Usually, once a community is formed, people stick to the language no matter what. It’s simply network effect.
The chances of success here are extremely low. People like Solidity, and there’s no reason for them to switch. Rust is not a magic bullet for anything.
Just a short message to say we - StarkWare - will provide our thoughts on this very important topic in a few weeks. We have a lot to say because the considerations regarding which VM to pick have been deeply and hotly discussed by our team internally a few years ago before embarking on the Cairo VM, which was where we landed.
FWIW, I was probably the most staunchly opposed to that approach at the start, and was in favor of providing proofs for some off-the-shelf VM, for the exact reasons you’d think: better to focus on proving something already built, than to “boil the ocean” and go with something entirely new.
By now, what was entirely new back then isn’t so anymore, and we’ve gained a lot of insights, which we’ll share. Briefly, we went for an architecture that optimizes for both safety (as a blockchain VM), STARK-proof efficiency and also STARK soundness. This has allowed us to already formally prove the soundness of the Cairo VM and expand on to a few mathematical syscalls.
What does this imply for Ethetreum? I don’t know yet, because I need to pick the brains of all the smarter folks in StarkWare that know way more than me about how to build a VM that’s safe, ergonomic, usable and efficient for blockchain and STARK-proving. But I assure you we have a lot to say. ![]()
It would really help if @vbuterin or someone on leadership of EF specifies what exactly are the desiderata and considerations for picking a next VM for Ethereum. After all, Ethereum has the unique position to determine The Gold Standard for blockchain VMs, i.e., Ethereum can say “here’s what I want” and that may become the standard.
This is a bit similar to an earlier process we led on behalf of the EF, that of recommending STARK-friendly hash functions. Would be great to have a similar effort for STARK-friendly VM.
Yes. But I disagree that it’s the best we can do. (: The way to do it is to assume the worst case, and then extend the model to lower those costs in cases when we know it’s safe. If you assume the best/average case then you’re just opening yourself up to denial of service attacks. The fact that you haven’t had any problems so far only means that no one bothered to attack your chain yet, not that your gas metering is safe.
Please correct me if I’m wrong, but my general feeling is that we are approaching the same solution from 2 sides. One side could be starting from the optimistic side, and gradually incur cycles at places where metering is wrong. And yes it totally possible to start from the other side, where the worst case(assuming every memory load results in a cache miss) is used first, and only lower the cost when it is safe. I don’t think it tampers the main point: modelling VM like a real CPU, enables us to build a much more accurate cycle model.
And I totally agree that CKB might still be in a stage that no one bothers to attack it, we definitely are watching things, and be prepared to revise our cycle metering model when fit.
In fact, I can guarantee you that they will not be deterministic. The non-determinism of the performance counters is not an arbitrary decision that the hardware designers made; it’s a direct consequence of making a high performance, superscalar, pipelined, out-of-order CPU core with multi-level caches.
Yes, you can in theory add such performance counters to a CPU, but that means the CPU will have to be slow to keep the counters deterministic, so what’s the point of running on a slow CPU with deterministic hardware gas metering if we can get faster performance by doing the gas metering in software on a fast CPU?
I totally agree with you, for superscalar, pipelined out-of-order CPU core, performance counters will be indeterministic. However I think there is a middle ground between the following 2:
It’s not one side or the other, there might well exist cases where a suitable solution can be found in between the two.
That being said, a real hardware as a blockchain VM, can be a quite niche case, I can drop this argument if you still think otherwise.
@edubart has helped with the first part(thank you!) so I will skip it.
This is something that can indeed be implemented in an interpreter to reduce VM traces, though the precompile approach is already ubiquitous and more performant for most bottlenecks (cryptography, u256, hashes).
If you know the exact algorithm people will use and only use, yes precompiles are the ideal solution. In fact, people in the RISC-V world do it all the time: all kinds of custom instructions are added to different RISC-V cores, just to solve a particular task.
That being said, all those macro-op fusions, as well as V & P extensions mentioned in earlier post, helps optimize program in a more general way: the optimizations are only introduced to the VM once(or much fewer times than we are adding new precompiles), and a series of cryptographic algorithms compiled down to RISC-V can all embrace those optimizations.
I do believe all the discussions on new precompiles we see here and in the EIP repo, already speak the fact that a more general approach might be yearned for than simply adding new precompiles. I still remember when /ethereum-magicians.org/t/eip-7212-precompiled-for-secp256r1-curve-support/14789 is being discussed…
It does not sacrifice just “some performance” but it starts with a 4x~7x lag from the load-compute-store overhead. If (3) is the most important bottleneck to solve (from Vitalik’s original post), then
I’d argue that Risc-V is not good enough.
There are ISAs that have been developed for a long-time, some that are used in production like Cairo or Valida that can be targeted from C, Rust, Nim and WASM today (and can easily add Zig for example tomorrow and C++ needs some work on the stdlib). See Valida spec here (Technical Design: VM | Lita Docs, disclaimer I’m working on Valida).
On the tooling side, Valida at the very least is using LLVM toolchains, can reuse usual tooling like gdb/lldb for debugging, and even perf for optimization.
It was simpler. 2 years ago, zkVMs were unproven, it was unsure if they were feasible vs zkEVMs with each EVM opcodes being a circuit: zkevm-circuits/zkevm-circuits/src at main · privacy-scaling-explorations/zkevm-circuits · GitHub
ZK-EVM provers today already work by proving over implementations of the EVM compiled down to RISC-V
Is RISC-V really the best architecture for proofs or can we make a better one? RISC-V wasn’t designed for ZK. If there is a better architecture in 2 years, how much of our RISC-V development would transfer to the next architecture?
then the gas schedule will reflect proving times
The gas itself has to be calculated during runtime to solve the halting problem. Gas accounting is a non-negligible part of both execution and proof. Many current operations have variable gas costs. It is possible that computing these variable costs will increase proof complexity, increasing gas complexity, etc. This is a chicken-and-egg problem because we have to know to charge gas in order to know how much gas to charge.
Instead, perhaps the EVM/EOF/EWASM can all be JIT’d into (RISC-V) using separate gas schedules. (RISC-V) would be the base execution layer and everything would transpile into it, injecting gas calculations at each step. Every hard fork would need their own transpilers, but these should never change.
Please, don’t.
I believe the main problem not the ISA per se, but code generation/optimization performed using CPU cost model.
Problematic ISA aspects can be (at least, partially) alleviated via binary recompilation. But re-optimization of code with ZK cost profile will be more complicated, e.g. static analysis of code RISC-V will be more difficult (due to aliasing).
I’d say that EVM+EOF is much better in that respect, since it’s higher level, easier to analyze statically (EOF is designed to be so) and does not include low-level CPU-oriented optimizations.
This is misleading. The RISC-V spec PDF has so many pages because it includes all of the ratified optional extensions up until this point. The baseline RISC-V instruction set is super simple. It’s so simple that I implemented a RISC-V interpreter in a single day, and a recompiler (which recompiles RISC-V into native code and runs it) in two days for my initial PolkaVM prototype. (Try doing that with WASM, especially since for WASM you also need to write a register allocator.) And the great thing about RISC-V is that you can chose which exact extensions you want to use.
WASM definitely doesn’t win against RISC-V when it comes to complexity. 172 instructions in the 1.0 WASM spec and 220 instructions in the 2.0 spec is not simple (up to total of 541 last time I counted if we include all proposed WASM extensions), especially compared to RISC-V’s 47 instructions in the base spec. And, again, with RISC-V you have the choice - you can only use the base spec! With WASM this is not supported, and compilers are already slowly sunsetting support for WASM 1.0 (e.g. the signext extension is now enabled by default; in Polkadot we have to forcibly disable it when building our WASM runtimes, but eventually that will stop being supported and we’ll be screwed). With RISC-V you can use the baseline target with only 47 instructions forever, and decide yourself when/if you want to opt into any extensions; with WASM eventually you’ll be forced to either fork all of the compilers and toolchains, or get on the complexity treadmill and implement all of the instructions that the newest WASM spec implements.
This is an entirely orthogonal issue. There’s nothing in RISC-V that prevents you from making the program code unreadable, or making self-modifying code impossible, or splitting the address space, or being able to check the code before execution. It’s just an issue of how much effort you want to invest. It’s possible to decide what you want to use from vanilla RISC-V and what you want to change; we went all the way with PolkaVM and got rid of almost every downside of RISC-V, but you can pick and choose:
So strictly speaking I agree with you, out of box WASM is better than RISC-V for the reasons you’ve mentioned, but you can fix those problems by just not naively taking RISC-V as-is as it’s used for native hardware and tweak certain aspects of it. It depends on how much of a perfectionist you are, and whether you want to maximize “keep it as close to RISC-V as possible”, or you want to maximize “be as fast as possible and as simple as possible while still being able to use vanilla RISC-V toolchains”, or something in-between.
For Polkadot we were already using WASM, so we wanted to migrate to something that’s strictly superior on all fronts, which is why we went all the way and tried to change/improve on almost every aspect of RISC-V that can be changed to make it better for our use case.
RISC-V is also 100% deterministic, and it’s actually easier to make RISC-V deterministic than WASM. For example, with RISC-V you can just not support floating point (and get the compilers to emit softfloats instead, so programs can still use them); with WASM you don’t have that choice, and you have to deal with issues like NaN canonicalization. Or, as another example, it’s a lot easier to make RISC-V’s stack deterministic, because unlike with WASM on RISC-V the stack is not a special thing and just lives in normal address space.
Note that this is a downside if you want to write a high performance recompiler that achieves near native performance. The ideal you’d want to achieve for performance is “one bytecode instruction == one native instruction”, as this makes writing a recompiler very simple (because you don’t need any complex logic, no register allocation, no op fusion, no interprocedural analysis, etc.) and is the reason why PolkaVM can recompile programs into native code in O(n) time and do it faster than you can calculate a hash and still have the resulting code be near-native speed, while wasmtime’s recompilation is not O(n), needs a recompiler whose complexity is many orders of magnitude higher, and needs hundreds times more resources to generate similarly fast code as PolkaVM.
Thank you for your post! Now I see
I don’t think there has been much consideration of how a transition to RISC-V would look. Here’s my brief take that shows how EOF is a valuable part of that transition:
From the linked article:
The code to reproduce these experiments is available at GitHub - succinctlabs/overhead: Measuring revm and wasmi overhead for SP1 programs..
But this repo doesn’t exist or is private. So I’m guessing it’s only me trying to reproduce these numbers.
I’m assuming the “Fibonacci-100k (u128)” benchmark computes the 100k’th element of the Fibonacci sequence with 128-bit precision. By the way, this number has almost 70k bits.
So I’ve written a simple EVM implementation of fibonacci:
5f195f355f60015b90810183830192600757035f5260205ff3
and EOF variant (just replaced JUMPDEST/JUMPI with RJUMPI):
ef00010100040200010018ff000000008000065f195f355f600190810183830192e1fff6035f5260205ff3
Using evmone and “native” CPU (x86) execution takes 5.0M cycles (legacy EVM) and 3.8M cycles (EOF).
I don’t know how to execute this in SP1 yet, but to get any upper bound estimate I’ve compiled evmone to riscv32 and counted host CPU cycles of the execution in the qemu emulator: 127M cycles (legacy EVM) and 114M (EOF).
This is still one order of magnitude lower than the number in the paper (1002M cycles).
You wrote:
What do you mean? There is no self-modifying code. It seems you mean that initcode can generate contract code on-the-fly. I. e. “generation” should be, not “modification”