This post proposes a radical idea for the future of the Ethereum execution layer, one that is equally as ambitious as the beam chain effort is for the consensus layer. It aims to greatly improve the efficiency of the Ethereum execution layer, resolving one of the primary scaling bottlenecks, and can also greatly improve the execution layer’s simplicity - in fact, it is perhaps the only way to do so.
The idea: replace the EVM with RISC-V as the virtual machine language that smart contracts are written in.
Important clarifications:
- The concepts of accounts, cross-contract calls, storage, etc would stay exactly the same. These abstractions work fine and developers are used to them. Opcodes like
SLOAD,SSTORE,BALANCE,CALL, etc, would become RISC-V syscalls. - In such a world, smart contracts could be written in Rust, but I expect most developers would keep writing smart contracts in Solidity (or Vyper), which would adapt to add RISC-V as a backend. This is because smart contracts written in Rust are actually quite ugly, and Solidity and Vyper are much more readable. Potentially, devex would change very little and developers might barely notice the change at all.
- Old-style EVM contracts will continue to work and will be fully two-way interoperable with new-style RISC-V contracts. There are a couple ways to do this, which I will get into later in this post.
One precedent for this is the Nervos CKB VM, which is basically RISC-V.
Why do this?
In the short term, the main bottlenecks to Ethereum L1 scalability are addressed with upcoming EIPs like block-level access lists, delayed execution and distributed history storage plus EIP-4444. In the medium term, we address further issues with statelessness and ZK-EVMs. In the long term, the primary limiting factors on Ethereum L1 scaling become:
- Stability of data availability sampling and history storage protocols
- Desire to keep block production a competitive market
- ZK-EVM proving capabilities
I will argue that replacing the ZK-EVM with RISC-V solves a key bottleneck in (2) and (3).
This is a table of the number of cycles that the Succinct ZK-EVM uses to prove different parts of the EVM execution layer:
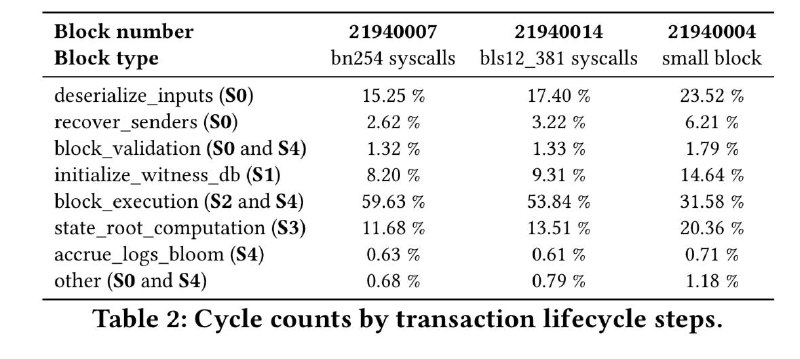
There are four parts that take up a significant amount of time: deserialize_inputs, initialize_witness_db, state_root_computation and block_execution.
initialize_witness_db and state_root_computation both have to do with the state tree, and deserialize_inputs refers to the process of converting block and witness data into an internal representation; hence, realistically over 50% of it is proportional to witness sizes.
These parts can be heavily optimized by replacing the current keccak 16-ary Merkle patricia tree with a binary tree that uses a prover-friendly hash function. If we use Poseidon, we can prove 2 million hashes per second on a laptop (compared to ~15,000 hash/sec for keccak). There are also many options other than Poseidon. All in all, there are opportunities to massively reduce these components. As a bonus, we can get rid of accrue_logs_bloom by, well, getting rid of the bloom.
This leaves block_execution, which makes up roughly half of prover cycles spent today. If we want to 100x total prover efficiency, there’s no getting around the fact that we need to at least 50x EVM prover efficiency. One thing that we could do is to try to create implementations of the EVM that are much more efficient in terms of prover cycles. The other thing that we can do is to notice that ZK-EVM provers today already work by proving over implementations of the EVM compiled down to RISC-V, and give smart contract developers access to that RISC-V VM directly.
Some numbers (see here) suggest that in limited cases, this could give efficiency gains over 100x:
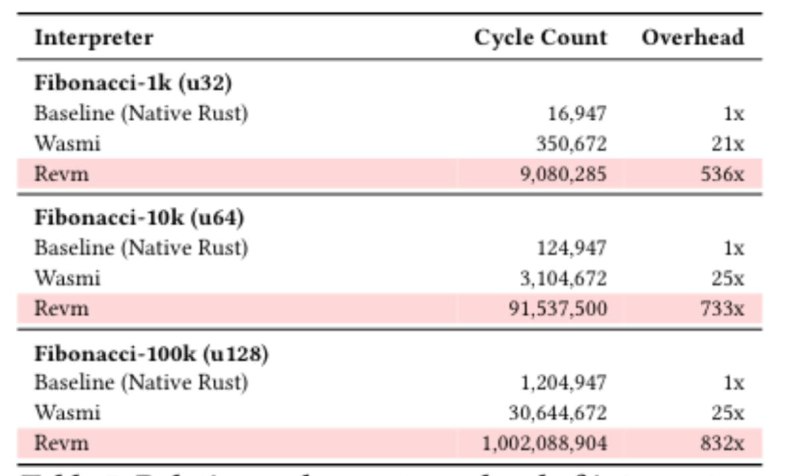
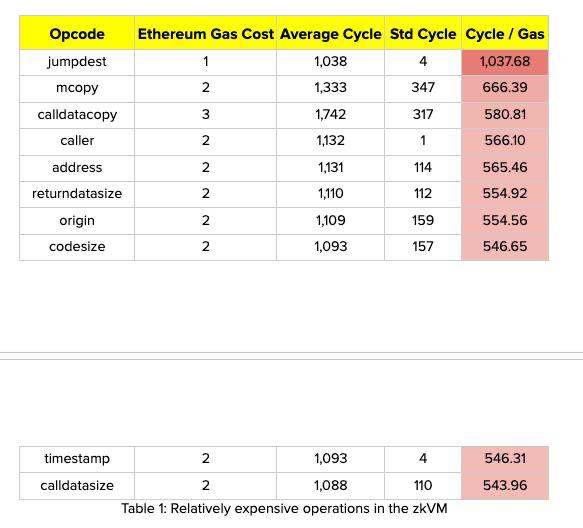
In practice, I expect that the remaining prover time will become dominated by what today are precompiles. If we make RISC-V the primary VM, then the gas schedule will reflect proving times, and so there will be economic pressure to stop using more expensive precompiles; but even still the gains won’t be quite this impressive, but we have good reason to believe they will be very significant.
(Incidentally, the roughly 50/50 split between “EVM” and “other stuff” also appears in regular EVM execution, and we intuitively expect that the gains from removing EVM as “the middleman” should be similarly large)
Implementation details
There are a number of ways to implement this kind of proposal. The least disruptive is to support two VMs, and allow contracts to be written in either one. Both types of contracts would have access to the same types of facilities: persistent storage (SLOAD and SSTORE), the ability to hold ETH balances, the ability to make and receive calls, etc. EVM and RISC-V contracts would be free to call into each other; a the RISC-V perspective calling an EVM contract would appear from its perspective to be doing a syscall with some special parameters; the EVM contract receiving the message would interpret it as being a CALL.
A more radical approach from a protocol perspective is to convert existing EVM contracts into contracts that call an EVM interpreter contract written in RISC-V that runs their existing EVM code. That is, if an EVM contract has code C, and the EVM interpreter lives at address X, then the contract is replaced with top-level logic that, when called from outside with call params D, calls X with (C, D), and then waits for the return value and forwards it. If the EVM interpreter itself calls the contract, asking to run a CALL or SLOAD/SSTORE, then the contract does so.
An intermediate route is to do the second option, but create an explicit protocol feature for it - basically, enshrine the concept of a “virtual machine interpreter”, and require its logic to be written in RISC-V. The EVM would be the first one, but there could be others (eg. Move might be a candidate).
A key benefit of the second and third proposal is that they greatly simplify the execution layer spec - indeed, this type of idea may be the only practical way to do that, given the great difficulty of even incremental simplifications like removing SELFDESTRUCT. Tinygrad has the hard rule of never going above 10000 lines of code; an optimal blockchain base layer should be able to fit well within those margins and go even smaller. The beam chain effort holds great promise for greatly simplifying the consensus layer of Ethereum. But for the execution layer to see similar gains, this kind of radical change may be the only viable path.