Proposal: any new address schema should support encoding multiple shard and L2 rollup chain IDs in a single address
The shard and L2 rollup chain IDs that are encoded in the address would represent the destination chains into which the address owner is happy to receive tokens e.g. If an address includes the IDs for say the Ethereum L1, Optimism L2 and ZKSync L2 chains, this would signal that the owner of the address is happy for tokens sent to this address to be sent on the Ethereum L1, Optimism L2 and ZKSync L2 chains.
In a world with multiple rollups, encoding multiple chain IDs in the address would enable wallets to automatically know which L2 rollup chains are valid destinations (for that address) without requiring any additional user input.
Without this change, when (in a world with multiple rollups) a user wishes to make a token transfer, the user would need to know the name of the destination chain in addition to the destination address. This is much worse than the token transfer user experience on Ethereum today!
Requiring users to enter a destination chain name (in addition to a destination address) introduces the following UX regressions:
-
significantly increases scope for user error (e.g. user sends tokens to the correct address but on the wrong chain)
-
Adds another concept (the fact there are multiple chains with different names) for users to learn, hindering adoption. For mainstream adoption we need to make Ethereum easier to use, not harder.
-
Because in reality most users would only enter/select a single destination chain, in many cases the routing of these cross chain transactions would be suboptimal, increasing the transaction cost the user has to pay, decreasing the transaction speed, and increasing the number of transactions that need to be performed which needlessly places additional load on the network. Many to many chain routing is better than many to one chain routing.
If multiple chain IDs are encoded in Ethereum addresses, all these problems go away and the token transfer user experience in a world with multiple rollups is just as good as the token transfer user experience today.
How it would work:
Let’s say Alice has funds associated with her address on rollups A, B and C. She wants to send funds to Bob who uses his address on rollups B, C and D. Bob sends his address to Alice, and in the address it is encoded that Bob is happy to receive funds to that address on rollups B, C and D.
Alice has 30 ETH associated with her address in total, and this is split equally across rollups A, B and C (10 ETH on each). Alice wants to send Bob 20 ETH. Because Bob’s address has told Alice’s wallet that he is happy to accept funds to rollups B, C and D, Allice’s wallet automatically works out that the quickest and cheapest way to send 20 ETH to Bob is to send 10 ETH from her address to his address on rollup B and another 10 ETH from her address to his address on rollup C. This means that this transfer doesn’t have to cross any rollup boundaries therefore avoiding the latency and cost of moving funds between rollups.
In terms of the routing of payments, the above is one of the simplest possible examples. In reality different L2s will have different bridge costs and delays, and the sender’s funds will frequently be spread across multiple rollups in a way that won’t match up so neatly with the rollups on which a recipient is happy to receive funds. And when L2 to L2 transfers become feasible there will also be different costs when moving funds between different L2’s adding another layer of routing complexity. It’s unreasonable to expect users to understand and manually work out the best answer to these complex routing problems each time they want to make a token transfer.
Encoding multiple chain IDs in ethereum addresses provides wallets with the information they require to compute the quickest and cheapest way of transferring funds (that are assigned to the same address across multiple rollups) to a recipient whose address is also used across multiple rollups.
Assumptions around token UX in a in a world with multiple rollups
-
In the future, wallets will include simultaneous support for multiple rollup chains (in addition to Ethereum L1)
-
When this happens, wallets will display the token balance for a given address across both Ethereum L1 and all the rollup chains that the wallet supports.
-
Token bridges will be built into wallets, so when a user wishes to transfer tokens across chains, they will be able to do this directly in their wallet without needing to navigate to a token bridge DApp.
See this rough visual mockup which illustrates these UX assumptions and shows how a token transfer flow could work in a world of multiple rollups if multiple chain IDs can be encoded in an address.
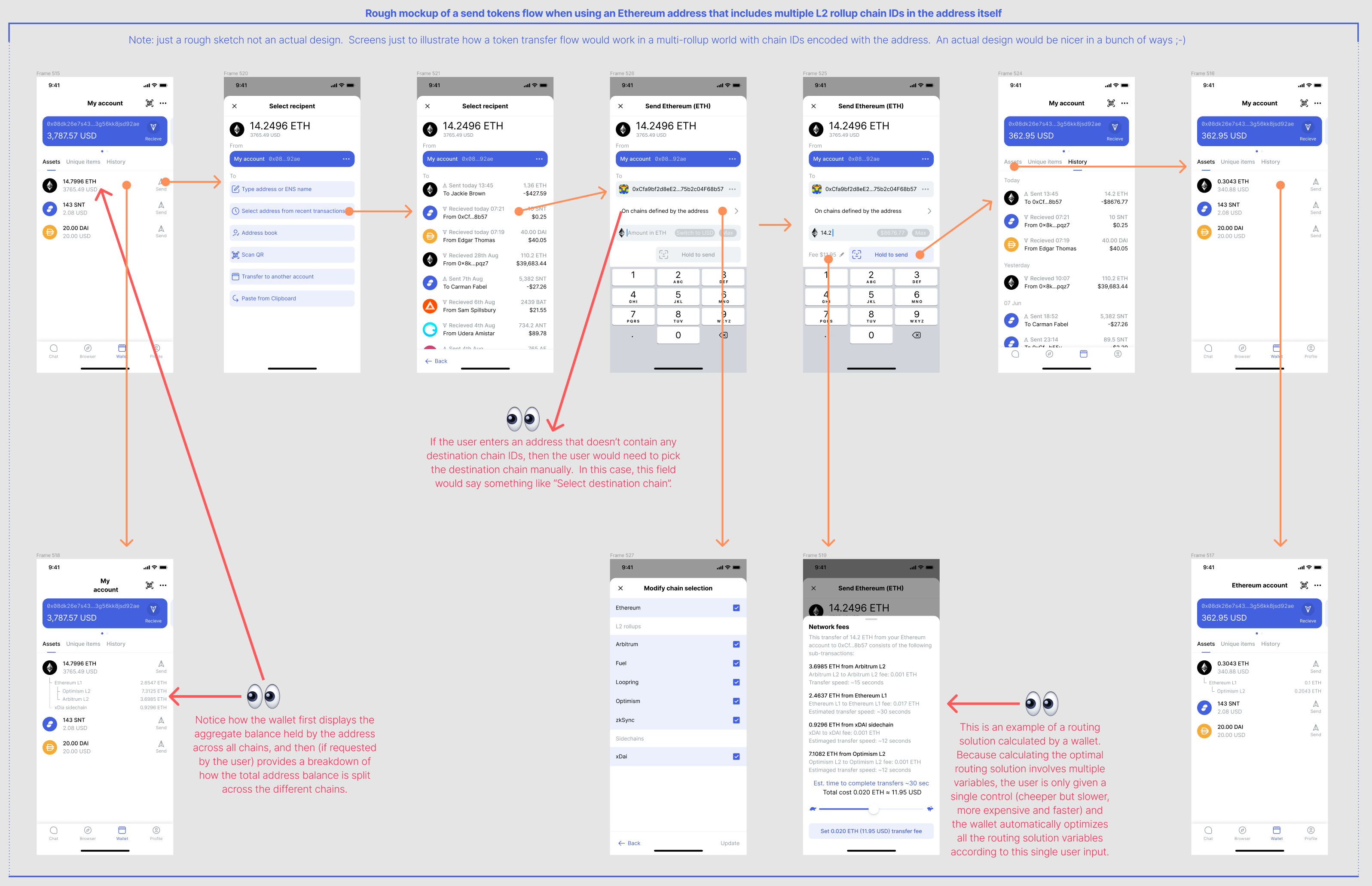
Benefits of being able to encode multiple chain IDs in an address in a world with multiple rollups:
-
The user sending tokens only needs to know the destination address (just like when using Ethereum today). Without this change, in a world with multiple rollups, a simple user to user token transfer requires the user to know both the destination address and the destination chain name.
-
Less scope for user error e.g. the user doesn’t have the opportunity to mistakenly enter the name of the wrong destination chain. Follows the UX principle that “when possible, the best way of handling errors is to remove the possibility of the user making the error in the first place!”
-
Lower transaction fees, faster transactions and reduced number of transactions.. Wallets would be able to automatically calculate the most efficient routing to transfer X tokens from account A to account B when (for example) account A holds X tokens across rollup A, rollup B and rollup C, and where account B is happy to receive tokens on rollup B, rollup C and rollup D.
-
Requiring the user to manually enter the destination chain for a transaction makes the UX of transferring tokens more complex. By having the ability to encode multiple chain IDs in an address, Ethereum doesn’t get harder to use than it is today in a multi-rollup world.
Open questions:
-
What is the max number of chain IDs we would allow to be encoded in a single address? The cost of allowing a greater number of chain IDs to be encoded in a single address is increased address length. Could allowing a max of say 8 or 16 chain IDs to be encoded in a single address be a sensible number?
-
What is the global max number of chain IDs that would be available for use in the future? The cost of having a greater global max number of chain IDs is increased address length. On the flip side, the greater the number of chain IDs supported the more future proof this format would be. Perhaps aim to support a total of 32k or 64k chain IDs in total??
-
A table of which chain IDs map to which chains would have to live somewhere
Other thoughts
-
Encoding Chain IDs in addresses should be optional e.g. an address should be valid even if no Chain IDs are encoded in it.
-
I’m +1 on adding native support for checksums to any future address format.
-
We’ve been looking into how we can encode multiple chain IDs into Ethereum’s current address format using mixed case encoding (EIP-55’s checksum encoding mechanism), but it’s not possible to use mixed case encoding for both multiple chain IDs and a checksum at the same time. Natively supporting multiple chain IDs in a new address format would resolve this issue.