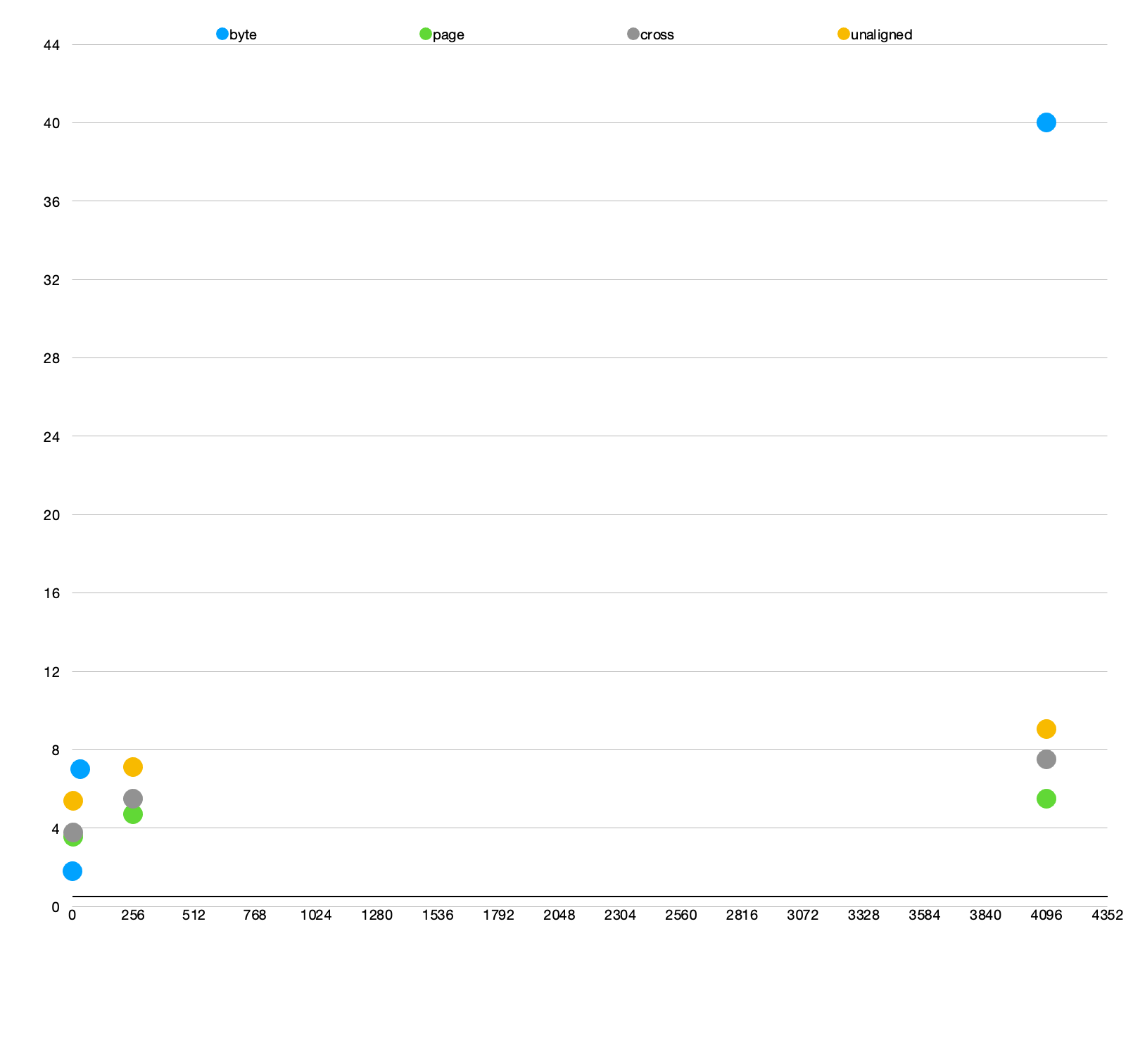
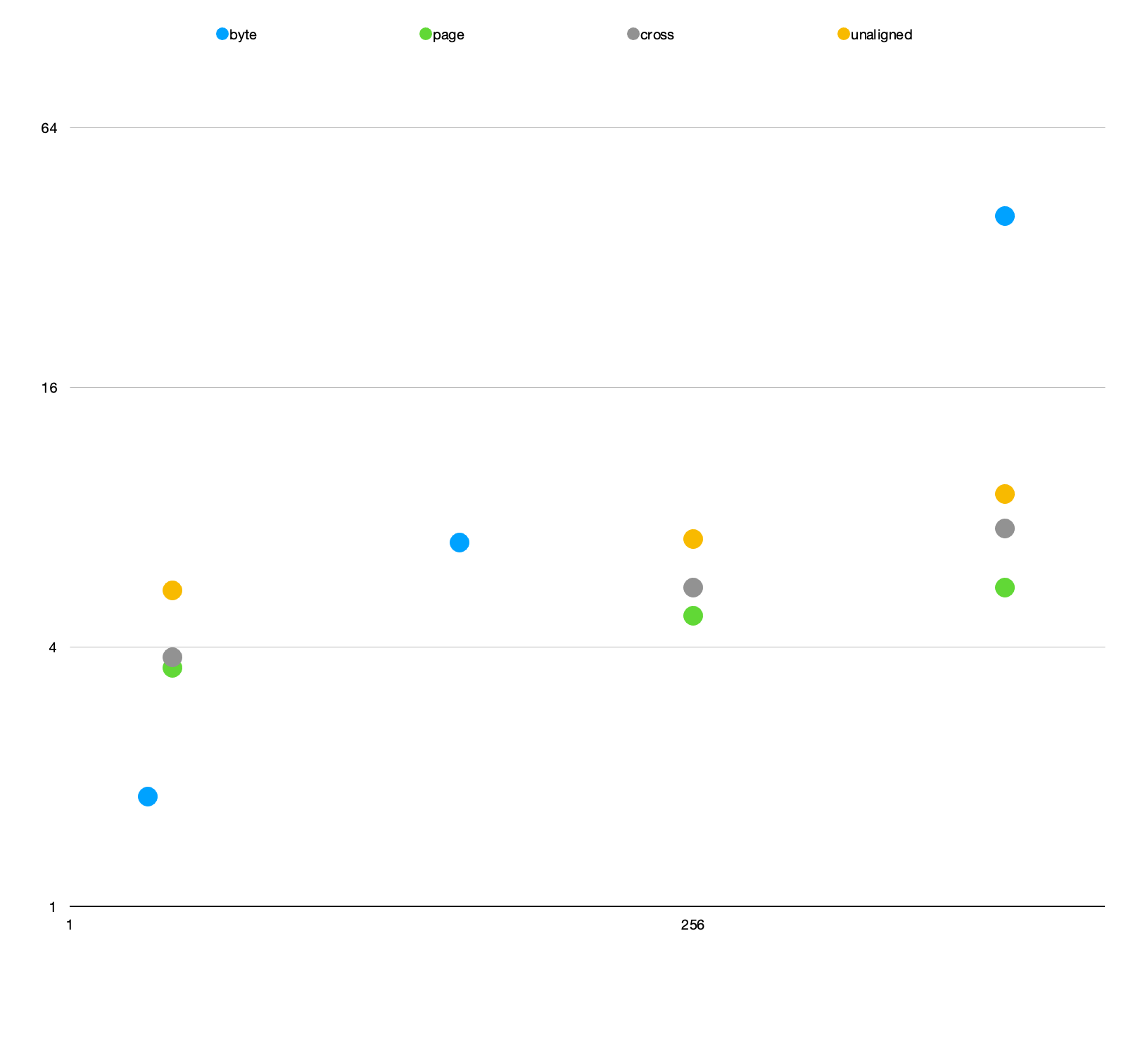
In the EIP Charles reports these numbers on an older machine:
Time to randomly read a byte from a 2MB range: 1.8ns
Time to randomly read a byte from a 32MB range: 7ns
Time to randomly read a byte from a 4GB range: 40ns
I put all of it in charts below. Plotted on a linear graph it seems there is maybe a thrash point somewhere below 32 MB. But plotted on a log-log graph they are all straight-line power laws with no obvious knee. It would be worth running the experiments with more data points to better explore the smaller memory sizes. I suspect we may be looking at the effects of on-chip caching – at 4GB the newer machine isn’t thrashing main memory at all. Instead we might be seeing a smoother increase in timings as data falls from L1 to L3 cache. Or, given that an AMD 5950x has only 64MB of L3 per core, it is hitting main mem, but the caching is doing a good job.
Thanks! How much RAM does a client use these days? Even if we increase the block gas limit I don’t know who could afford a transaction that allocated 4GB. Last time I scanned the whole chain most contracts used a few hundred bytes at most.
Since Qi’s numbers were run on a computer which is much more similar to a typical client than mine (2019 laptop with DDR4 ram) I’m inclined to go with his numbers.
At the sizes of memory we are talking about (64MB per transaction etc) the difference between 7ns and 30ns (or even 40ns) to justify the LRU cache, so I’ll nix it from the EIP.
An alternative here which I’ve discussed in the EIP is to create a per-call limit, instead of having a transaction-global limit. That has the downside of making it harder to reason about how much memory a transaction can use, since you need to reason about all possible shapes of the call stack. I believe core devs prefer the global limit to the per-call limit, but maybe we can ask them to chime in here.
In this case, the “maliciously allocated” memory of contract 2 is cleaned up as the call exits, leaving memory clean for Contract 3 to use. Contracts can indeed interfere with subcalls (in this case, e.g. by making a subcall inside of Contract 2), but they can do that already anyway in numerous ways (e.g., by not providing enough gas to the subcall). They can’t interfere with the execution of subsequent calls.
So if I understand correctly, memory is reclaimed (hopefully zeroed) and reused by subsequent calls after a call returns. This differs from solidity’s memory management, where every allocation increments the free-pointer and memory is never reclaimed.
To make sure I understand, I’ll use an OS analogy. Sounds like it’s behaving similarly to the how memory management works on Linux: The brk/sbrk syscalls increase the memory size, setrlimit syscall can limit this size for the entire process, but higher level lib functions like malloc/free manage and reuse the memory, calling brk/sbrk only when they’re out of memory. Is that how memory managed for each transaction?
If that’s the case then indeed my EntryPoint example is incorrect. I assumed that each call counts towards the limit - separately. UserOps will not be able to affect each other.
However, subcalls are still affected. This can be abused by transactions that wrap 3rd party calls, such as intent protocols. A malicious solver may cause user calls to fail, while still getting paid for making them.
Well-written protocols mitigate the gas case by letting the user specify the required gas, checking for it using the GAS opcode and rejecting the entire transaction if user calls are given insufficient gas. EntryPoint for example is immune to this attack because it reverts the entire transaction if a UserOp is executed with less gas than it requested.
We’ll need a similar opcode to check available memory in order to mitigate such attacks. And another one for available transient slots with EIP-7971.
Yes, the memory is reclaimed. If you read the specification or the reference implementation, nothing in the EIP changes any semantics about how memory is allocated/reclaimed at the entry and exit of a call frame, it retains the same semantics of each call frame having its own ephemeral memory. If you’re not familiar here with how memory is currently managed in the EVM, I would recommend digging into the execution specs, as a full exposition would be off topic for this thread.
We’re talking about how memory is managed in the EVM, it’s a completely separate topic from how solidity may or may not manage memory.
I don’t think many (if any?) protocols check gas at their entry point. This is because hitting OOG results in the same outcome semantically as reverting, which is reverting the current message call (not the whole transaction, by the way). In any case I don’t see the issue here, DOSing subcalls seems pretty pointless, since you already control the execution at the point right before the subcall. You could just avoid making the subcall.
Gotcha. Still wondering how much memory clients take up; that plus per-call overhead, stack and memory use is the total memory footprint. What is that footprint relative to cache size? When the thrash point is up above 4GB it might not matter, but the limit on transaction memory is surely not a factor.