I must be misunderstanding something then because it looks like your proposition is to turn an HTTP GET request into a single contract call where you pass a bunch of strings to it, rather than dispatching it to the appropriate function directly and doing the string to type conversion elsewhere. By doing it the way you have it specified, you are putting a lot of work on the EVM that could be done in some middleware component which feels like a bad trade since EVM execution is many many many orders of magnitude more costly than middleware execution.
The idea here is that there will be minimal computation performed inside the request function. Take the following rapidly made request function that may or may not work, for example. I expect that most of the request functions that will be made will look extremely similar to the following:
function request(string[] memory resource) external view returns (uint8 statusCode, string memory body, KeyValue[] headers) {
bytes32 hash = keccak256(abi.encode(resource));
if (bodyMap[hash] == "") {
return 404, someIPFSMultihashFor404, standardIPFSReturnHeaders;
}
return 200, bodyMap[hash], standardIPFSReturnHeaders;
}
Considering it’s a view function that is meant to never be called by an external contract, the only noticeable cost will be during deployment (to store the bytecode in the contract and initialize someIPFSMultihashFor404 and standardIPFSReturnHeaders) and when updating bodyMap.
For example, I have pandapip1.eth (well, I don’t, but I would like to), and decide to point it to address 0x1234567..., a smart contract implementing this EIP. When a web browser visits pandapip1.eth, assuming I have no A, AAAA, CNAME, or SRV DNS records, the request function will be called with a resource of [] (no path). Say I have a link to /my-cool-project, and the user clicks on it. Then, the request function will be called with a resource of ['my-cool-project']. With the proposed IPFS content type, the whole website doesn’t need to be stored on Ethereum, but has all the advantages of this EIP, minus the permanence/
What is the advantage of this over just adding a record to pandapip1.eth that points at an IPFS root?
The ability to add more complex logic if it is needed. Most of the time, it isn’t (yay!), but I could imagine a use-case (such as a blockchain explorer) that could benefit from this functionality.
Do you have an example of adding more complex logic (even a contrived example would be fine for this purpose)?
A balance explorer. The resource would be the string representation of the address you’re inspecting.
What would that look like if this EIP was implemented?
So, there would be a mix.
The best example would be SPAs (single-page applications) with their front-end code fully on the Ethereum mainnet. While it would cost a fortune to push updates, the website will remain for the rest of time.
Alternatively, with the new content type, they could host the code on IPFS. While it might eventually disappear, the advantage of this over returning a tree would be that any URL would be resolved, not just ones in the tree. While I can imagine a block explorer being written as a SPA, the fact that an infinite number of URLs need to be resolved to the same thing means that this standard is flexible enough for that use-case.
Things get interesting when you consider rollups or cheap sidechains. While initially, hosting a website fully on a sidechain might seem like a stupid idea, I argue it’s superior to the current system for two reasons:
- It might actually be more cost-efficient than the current hosting situation
- It’s more decentralized than hosting on a single fully centralized hosting platform like Hostinger.
I hope to see the first two scenarios most frequently, but I would argue even the third (“worst-case”) scenario is better than what we have currently.
One could host a blockchain explorer as an IPFS SPA and just use anchor or query string routing for data. There is no need to have a separate IPFS page for every block/transaction/whatever.
That being said, I don’t see how a block explorer would fit into this paradigm as much of the information one would want can’t be acquired from a contract (but can be acquired from an Ethereum client).
As a more high level argument, something with a replication factor of Y where Y < X will necessarily always be cheaper to host than something with a replication factor of X. Ethereum is a database with an RF of like 10,000 while IPFS is a database with an RF of 0-n (where n is the number of people who have recently browsed the site plus people who have pinned the site). With the introduction of Filecoin, RF changes to m-n, where m is the RF that IPFS has determined is enough to provide robust availability guarantees (I don’t actually know what m is, but it is > 1).
While this isn’t a blocker for the EIP, I’m not convinced there exists a future where this EIP would make sense for anyone as I think it is better in basically all scenarios to use something purpose built for data storage like IPFS than to use something like Ethereum which is an insanely expensive database.
1 Like
Should the type of statusCode be changed from uint8 to uint256? E.g., 404 status code is greater than 255 and cannot be returned to frontend.
Hi!
I made a quick proof-of-concept implementation of eip-5219 on this browser :
You need to switch to the eip-5219 branch, then run
yarn start -- -- web3://0xd67C07015dc70a57d6675aaAeF17dbA42FEBfA91:5/
It will run this website :
https://goerli.etherscan.io/address/0xd67C07015dc70a57d6675aaAeF17dbA42FEBfA91#code
You’ll get debugging infos on the devtools, for example if I go to :
web3://0xd67C07015dc70a57d6675aaAeF17dbA42FEBfA91:5/view/1
I get :
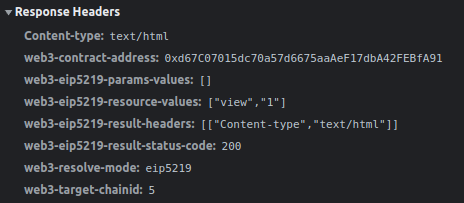
This is a quick proof of concept implementation to get hands on experience!
A question : why not accept some specific headers as input?
For example, many of files we store on-chain, we store them gzip’ed, so it would be great that we can transmit the Accept-encoding header so that we know if we can return the gzip’ed data, or return an error if the client does not support gzip.
What do you think?
Yup, had a brainfart when I wrote that. Will bump it up to uint16 which should be sufficient.
1 Like
This EIP is final, so this can’t be added. Earlier, I decided against it, since having to parse headers would significantly increase contract code size, and if there is a significant need for it, it’s always possible to standardize a new access-type.
Hi!
I have implemented ERC-6944 (adding ERC-5219 as a mode to ERC-4804 web3://) on :
- The parsing and executing package GitHub - nand2/web3protocol: Parse and execute ERC-4804 web3:// URLs
- The proof of concept EVM Browser GitHub - nand2/evm-browser: Web browser with support of the EIP-4804 web3:// protocol, which can show on-chain websites hosted on Ethereum and all others EVM chains.
I have published a demo ERC-6944 website at web3://web3-mode-5219.terraformnavigator.eth/ (Terraform NFT explorer) whose source code is at https://etherscan.io/address/0x2b51a751d3c7d3554e28dc72c3b032e5f56aa656#code
2 Likes