A translation of an HTTP-style Web3 URL to an EVM call message
Motivation
Currently, reading data from Web3 generally relies on a translation done by a Web2 proxy to Web3 blockchain. The translation is mostly done by the proxies such as dApp websites/node service provider/etherscan, which are out of the control of users. The standard here aims to provide a simple way for Web2 users to directly access the content of Web3. Moreover, this standard enables interoperability with other standards already compatible with URIs, like SVG.
In the motivation section, it might be nice to add something like this comment. Perhaps: interoperability with other standards already compatible with URIs, like SVG.
Personally, I think the web3 term is a bit too vague/broad for us to co-opt. Maybe evm://, since we use Solidity’s ABI, or just maybe just eth?
The return types are strictly client-side, so perhaps using the anchor notation for that ...#uint256,(string,bytes32)?
In the example web3://wusdt.eth:4->(uint256)/balanceOf/charles.eth, balanceOf doesn’t match the given grammar earlier in the proposal (as far as I could tell.)
How would you feel if the types were mandatory? Asking implementers to figure out how to retrieve ABI definitions might be a bit heavy.
Many thanks for your comments. A couple of my responses:
Nice! I have added the sentence Moreover, this standard enables interoperability with other standards already compatible with URIs, like SVG. in the motivation part.
Thanks for the comment. I feel that eth:// may be a bit narrow because the protocol itself can support any EVM blockchains such as Polygon/BSC or even testnets. For evm://, I feel it is a bit technical because a lot of Web2 people may not have an idea what EVM is.
I have been struggling to choose the best scheme name. I finally choose web3:// because the major goal of the protocol is to be the counterpart of http:// in Web2. Further, given the fact that Ethereum/EVM has been the de-facto Web3 technical stack, using web3:// could strengthen the position of Ethereum/EVM in Web3 without creating confusion. Feel free to let me know if you have other thoughts.
Thanks for the comment. The hashtag will be pre-processed by the browser so that the type info may not be passed to the gateway or web extension. If we want to process them on the client side, we need to return an HTML that processes the type info, which may be complicated. Instead, if we could process them on server side, then the user can browse the formatted result either in browser or curl/wget or programs easily.
Thanks for the comment. balanceOf should match method in the grammar:
As the result, the protocol will call “balanceOf(address)” with charles.eth’s address from NS. Please let me know if I miss anything.
I agree that retrieving ABI definition is not easy in this case. Actually, mandating the types in the link still needs ABI definitions for implementers. So the cost should be the same no matter whether the types are mandatory or not.
The reason for providing auto-type detection is to make the URL as simple and natural as possible. Further, in our current gateway implementation, we will return web3-calldata, web3-method-siganture, and web3-return-type in HTTP response headers for better debuggability. The following is an example of
I would argue that http is pretty technical I don’t feel too strongly about the actual prefix though.
Is the intent to resolve the URIs through a browser? Although it’s possible to return HTML directly from a contract, I don’t expect that to be too normal (or gas efficient.) If the anchor is stripped before passing to a web extension, then yeah, it wouldn’t make sense to put it there.
The only non-binary data I’m familiar with on-chain today would be NFT metadata/image data.
Ha, can’t believe I missed that… Obviously that makes sense.
I think if you had a URI like web3://foo.eth/balanceOf/address!bar.eth that would be sufficient to call the function. Actually, you could even do web3://foo.eth/balanceOf(address):uint256/bar.eth. What am I missing?
Are the types in the current EIP are there to disambiguate between overrides?
On an unrelated note:
In the second case, nsProvider will be the short name of name service providers such as “ens”, “w3q”, etc.
This seems to imply that an ENS lookup would have to be web3://foo.eth.ens/... or web3://example.com.ens/...? The examples later in the EIP don’t match that pattern.
Thanks for the comment. The intention is to resolve the URIs via a gateway (like ipfs.io) or a web browser extension. The browser just passes the full Web3 URI to the gateway/extension, and the gateway/extension would have full knowledge to parse the URIs to EVM call message and format the returned data back to the browser via HTTP protocol. This requires minimal changes on browsers so that we can use any browser (Chrome/Firefox/IE/etc) to browse Web3 URIs easily.
The standard would perfectly fit into NFT metadata/image data like SVG (I am also a big fan of it ). Meanwhile, we are exploring other non-binary data such as dWeb or even dynamic Web page generation (decentralized social network?). There are a lot of possibilities here enabled by Ethereum and ERC-4804!
Many thanks for the comment. A couple of great design questions for the standard. Let me list them one-by-one:
Q1: For address from name service, should we use name type or address type? E.g.,
web3://foo.eth/balanceOf/address!bar.eth ; or
web3://foo.eth/balanceOf/name!bar.eth?
Using address type for both conventional 0x-20-bytes-hex ETH address space and name from NS should work as ETH address will never have “.”, but should we separate these types for better clarification?
Q2: Do we need type auto-detection, i.e., do we need the simpler URI at the price of potential ambiguity? E.g.,
web3://foo.eth/balanceOf/address!bar.eth
web3://foo.eth/balanceOf/bar.eth
where the first is with mandatory type and the second’s type is auto-detected.
Actually, auto-detection may coexist with manual resolve mode better. Taking a dWeb as an example, the user may type (myhome.eth is in manual resolve mode)
web3://myhome.eth/aaa.svg,
which will pass /aaa.svg as the calldata so that the contract can display the file directly. As a comparison, using the mandatory typed link in auto resolve mode will look like
web3://myhome.eth/showFile/string!aaa.svg
which is more verbose.
Q3: If types are supplied, where to put the input argument types and return types (which can be a tuple)? E.g.,
I personally prefer “->” to prepend return types as it is clear to understand. In addition, current standard puts “->(outputTypes)” after the contract name (Option 4) so that the path part of the link looks almost the same as that of the Web2 HTTP link. Admittedly, Option 1 or 2 is closer to what current Solidity has, but seems to be incompatible with auto-detection for types.
Nice find! I have changed the sentence to
In the second case, nsProviderSuffix will be the suffix from name service providers such as “eth”, “w3q”, etc.
If you’re using a gateway (like foo.test), I’m guessing the full URL would look something like https://example.eth.foo.test/balanceOf/bar.eth#uint256? If the gateway is returning the raw data, it wouldn’t be able to access the anchor… So it makes sense to put it in the path component.
If we want everything to be symmetric, then it makes sense to put it in the path for extensions and direct requests too. You’ve convinced me
I guess the reverse question is also important: will there ever be a NS provider without a .? I have a slight preference for just using address, but that mandates a dot in the name. Small trade-off, in my opinion.
I totally overlooked the section on auto-detection. I don’t think the contract being queried should be able to affect the interpretation of the URI. That would mean I’d need to know what mode the contract is in to correctly construct a URI, which would make autogeneration of URIs (say in on-chain SVGs) difficult.
I’d most prefer an explicitly typed URI, but it might be possible to make some unambiguous rules to infer types.
Yeah, looking at your examples, I like -> more too. Doing name(type arg0)->(type,type) will be pretty familiar to Rust devs
I definitely don’t think it should come before the first /. If it does, it looks like part of the “host”.
Just kinda throwing the idea out, but what if there were some implied defaults, if not specified? For example web3://foo.eth/->/aaa.svg could mean “call a function with the signature index(string) -> (string)”.
How would you handle resolving ENS names that use DNSSEC? For example supersaiyan.xyz is a valid ENS name.
We also had an internal discussion on which one is better, but no strong preference. I think we could choose address now by assuming that all NS providers must have “.”.
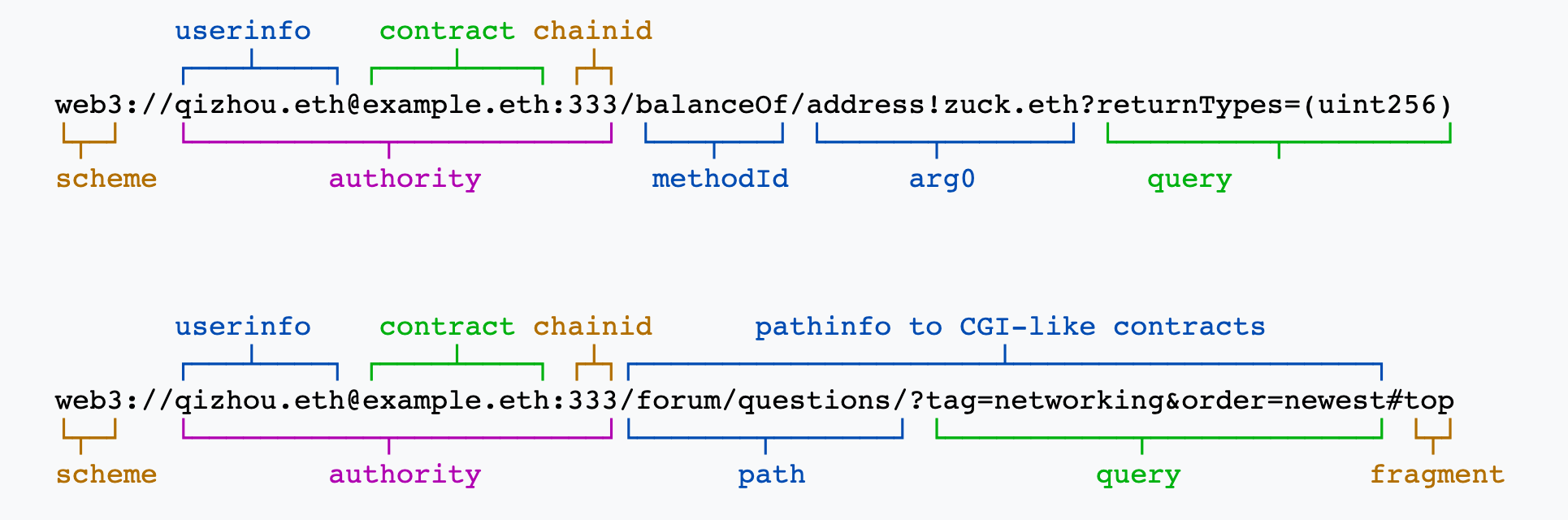
Thanks for the comment. I would argue a potential huge application with “manual” mode for on-chain Web content generation. To be more specific, the current standard serves two major purposes:
Purpose 1: Call a contract for JSON-formated result
If the returned types are specified, the protocol will
1. call the contract;
2. get the call result in raw bytes;
3. parse the raw bytes into ABI-encoded types as specified by returned types;
4. format the ABI-encoded types to JSON and return the JSON response to the client.
This can be viewed as a complement to the existing JSON-RPC protocol.
Purpose 2: Call a contract for on-chain Web content
If the returned types are not specified, the protocol will assume that an on-chain web content (e.g., HTML/SVG/CSS/etc) will be returned to the client. This is perhaps the most attractive application of the standard.
My original design for this purpose comes from common gateway interface (CGI) - the famous interface for Web servers. In CGI, the web server allows its owner to configure which URLs should be handled by which CGI scripts. For example,
this will ask web server to call printenv.pl script with /with/additional/path?and=a&query=string as argument.
With manual resolve mode, the smart contract can work as CGI script similar to Web2. This brings the following unique benefits:
Support Web3 URI with HTTP-URL-style path and query, which existing Web2 users are most familiar with;
Be compatible with existing HTTP-URL pathing, such as relative path. This means a HTML/XML can reference their relative resources easily (e.g., web3://aaa.eth/a.svg referencing ./layers/0.svg will be translated to web3://aaa.eth/layers/0.svg by browser);
Default web index (e.g., web3://aaa.eth/ could reference to web3://aaa.eth/index.html as configured by the contract).
I think that these features should greatly bridge the gap between Web2 users to Web3 dApps.
Admittedly that the users need to know what mode the contract is in to correctly construct a URI. However, the manual mode only works to CGI contracts that serve special web content needs, while 99+% of existing contracts are not affected. As a result, we could safely assume that the implementers (most likely the CGI contract developers) have the full knowledge of how to interact with CGI contracts in manual model.
What do you think?
I think if we enable manual mode, the implied defaults may be implemented by the contract themselves? Similar to setting directory index in Web servers (Web server directory index)
Thanks for the comment. Do not have a plan right now. But we could create an extension EIP for supporting DNSSEC after finalizing this one?
add a principle to highlight that EIP-4804 should be maximum compatible with the HTTP-URL standard so that existing Web2 users can migrate to Web3 easily with minimal knowledge of this standard.
The second one is inspired by our discussion of interoperability with SVG (or more generally, any on-chain Web content), which is one of the most applications we want to support. Please take a look.
Yes, the URL may look like https://example.eth.foo.test/balanceOf/bar.eth#uint256 or https://foo.test/example.eth/balanceOf/bar.eth#uint256
where the ipfs’s gateway has similar link to resolve ipfs resources.
Given the principle that we want to maximize compatibility with HTTP-URL, we the 5th option may be
5. web3://foo.eth/balanceOf/address!bar.eth?returnType=(uint256)
Thanks for pointing this out. Looks like there are a couple of overlaps, but it seems the target applications are quite different? E.g., ERC-4804 serves as an HTTP-style resource locator, which is designed with some unique features
MIME detection
Auto-type detection to simplify the links
CGI-style resolve model to allow “smart contract as CGI script”
Do not ask for the block number (but we could add it if we really need this)