I would support opening a PR that reduces the costs to the proposed values, there is going to be some overhead in the implementations themselves that would make the maximum memory allocated higher than in the formulas. I have some code locally that uses https://github.com/fjl/memsize to observe the size of the transient storage struct after filling it up with a ton of bytes. If we can come to an agreement on what the safe max size is, then I can add a test to the geth implementation for that. Perhaps 15mb? Would need to run it again with the new values to see where its at.
I think we should also come to agreement on the bytes that represent the opcodes themselves, because in its current state different implementations are using different numbers.
https://github.com/ethereumjs/ethereumjs-monorepo/pull/1768 uses 0xa5 and 0xa6
https://github.com/tynes/go-ethereum/tree/eip1153 uses 0x5c and 0x5d
https://github.com/cfromknecht/solidity/tree/5aaf51f82e7acd9c50406332e2acb4e175b7572a uses 0x5c and 0x5d
https://github.com/vyperlang/vyper/tree/transient uses 0x4E and 0x4F
The Ethereum JS VM implements Simple Subroutines which use 0x5c and 0x5d
but I think the codegen would be better if TLOAD and TSTORE were byte addressed instead of word addressed like SLOAD and SSTORE
I’m definitely not opposed to this but would want more feedback from people first. Perhaps @AlexeyAkhunov@axic?
Maybe worth it to price in a transient storage expansion cost, to model cost going up as you approach OOM.
I’d prefer to not have dynamic costs if possible since that would increase the complexity of the implementations, but that would make it much safer against mass TSTORE’ing.
unlike mstore (max memory expansion is 2.5gb from what someone else calculated), max memory allocation is small. Strongly think the complexity isn’t worth it but i will explore later with concrete benchmarks.
The alternate solution of a byte-addressed persistent memory makes it a lot harder to support things like mappings or dynamic arrays. Our primary use case needs mappings. Implementing a mapping in memory is painful. I imagine persistent memory would also have to be more expensive to account for reverts, which require you to store snapshots of the persistent memory with each new context for an address. I also think the revert behavior of persistent memory will not be as obvious for developers. For those reasons I’d prefer opcodes with the same semantics of storage.
We chatted in DMs and the 2.5gb number seems incorrect. A closer estimate of the max memory size that can be allocated via mstore is below:
30M gas = 3x + x^2 / 512 where x is the number of 256-bit words that can be allocated
implies x = ~123,169 256-bit words
max memory size in MB = ~123,169 words * 256 bits/word * 1MB / 2^23 bits = ~3.75MB
This is computed with the assumption of a single call context, so maybe it can be inflated by creating a new context but I doubt it can be inflated by several orders of magnitude.
To verify, go to evm.codes and enter the offset 123169 * 32 = 3941408 to see a gas cost of ~30M due to memory expansion. Not sure about the original motivation of this very constrained memory.
Re TLOAD/TSTORE pricing: if the warm SLOAD/SSTORE is overpriced/underpriced, I think it makes more sense to reprice those opcodes than to give TLOAD/TSTORE a separate pricing model. They operate exactly the same with regards to reverts except the original value of the slot does not need to be loaded.
Sidenote: I am working on testing the impact of TSTORE/TLOAD opcodes on the prototype I’m working on.
The alternate solution of a byte-addressed persistent memory makes it a lot harder to support things like mappings or dynamic arrays. Our primary use case needs mappings. Implementing a mapping in memory is painful.
Not sure why, since there will be no transient storage/persistent memory expansion cost. Mappings will still work the same way as storage. It will just make it easier to issue unaligned loads and stores.
I’ve tested our prototype against this solidity compiler and using this gist to work around the incomplete solidity compiler support for the transient keyword, plus a grep to update the opcodes to match the EIP (PR waiting merge), and this @ethereumjs/vm fork, and found the gas differences to be very significant as expected. This is far from an optimal implementation because I had to manually write the loads and stores in solidity plus they go through a delegatecall to an intermediate library (incurring a minimum 2600 + 100*(N-1) gas overhead). For example, the reentrancy lock looks like this using the linked gist:
import {TransientStorageProxy, TransientStorage} from './libraries/TransientStorage.sol';
contract Contract {
using TransientStorage for TransientStorageProxy;
TransientStorageProxy public immutable transientStorage;
constructor() {
transientStorage = TransientStorage.init();
}
uint256 public constant LOCKED_BY_SLOT = uint256(keccak256('lockedBy'));
function lockedBy() public returns (address) {
return address(uint160(transientStorage.load(LOCKED_BY_SLOT)));
}
function setLockedBy(address addr) internal {
transientStorage.store(LOCKED_BY_SLOT, uint256(uint160(addr)));
}
}
For our most expensive transactions, e.g. the first position to mint for a given tick range around the current price, #mint around current price new position mint first in range: the savings are minor, 385k to 365k. As expected the change does not benefit expensive transactions as much since the 20% refund cap is not as limiting, but there are still savings to be had avoiding unnecessary cold SLOADs.
However, for a simple swap: #swapExact0For1 first swap in block with no tick movement, gas goes from 204k to 137k. Given V3 swaps are around 100k gas, this is the difference between feasible and infeasible for the prototype design (note this isn’t exactly apples to apples–the 37k difference will come down with proper support and is also made up elsewhere). Not having this EIP means we have to use a worse design.
Byte-addressing for the TLOAD/TSTORE opcodes while still using an underlying map implementation is an unexpected hybrid between storage and memory that will confuse developers and implementers. It also would have to have dynamic gas cost to represent the fact that it reads/writes from either 1 or 2 slots depending on whether the given offset is word aligned, and unaligned writes will also have to avoid overwriting existing values via 2 separate loads. Thus it’s a leaky abstraction to the fact that transient storage is key-value storage–compiler devs will need to understand the hidden underlying implementation.
Bytecode generation improvements in rare use cases don’t seem worth the complexity in this case.
Have since updated the EIP to TLOAD = 0xb3 and TSTORE = 0xb4.
I’ve also added the security considerations about non-quadratic memory expansion to the EIP. TSTORE is cheaper than MSTORE after 24831 words have been stored to memory. 24831 words occupy less than a megabyte.
Open to suggestions about how to improve the pricing for memory expansion. Agree with @tynes that ideally it does not result dynamic memory cost, but open to changing that about the EIP if it’s deemed necessary by the client developers, and also would like if we can decrease the cost of small amounts of transient storage.
After working through the prototype, I still favor this map based interface (a la TSTORE/TLOAD) over a persistent memory similar to MSTORE/MLOAD because of how important mappings and dynamic arrays are for the use cases it enables, and also the expectation of how it interacts with reverts.
I will try a different angle
It might make sense to ask the cost of a origin calldata ‘witness’ verification via txid
Then ask how expensive (or cheap) these tload/tstore opcodes would have to be to be used in practice
It might turn out that the practical outcome of this is yet more reason to increase the cost of calldata
Then after that it would no longer be logically connected, like you are implying
After working through the prototype, I still favor this map based interface (a la TSTORE/TLOAD) over a persistent memory similar to MSTORE/MLOAD because of how important mappings and dynamic arrays are for the use cases it enables, and also the expectation of how it interacts with reverts.
I think @axic’s proposal is still workable. The revert issue may potentially be addressed with a paging/COW implementation; and, mappings / resizable dynamic arrays should not be a deciding motivator here since they are a language restriction, not an EVM restriction.
I disagree with @charles-cooper . Nothing stops a language implementation from addressing an associative memory 2^256 words in size as though it was a linear memory of smaller size. Meanwhile the benefit to implementors for having such an oversize memory in reduced bookkeeping for maps and dynamic arrays is considerable.
As for the size of entries in the memory the EVM works with 256 bit words natively. Addressing memory smaller than word size makes loads of these values harder, or consumes more opcode space for each width. Meanwhile there is no reason that values need to be compacted in this memory space given the low costs of access.
If you have particular applications in mind that trump these concerns please share.
Sorry, this is not meant to sound rude, but I’m very sceptical about the usefulness of these new opcodes. They make the memory (in the more general sense) model and calling convention of the EVM even more complicated than it already is.
The use cases I have seen do personally not convince me. They are either saving only a small amount of gas or need way more explanation. I’m looking at the list as currently published on eips.ethereum.org):
“reentrancy locks” - that’s a joke, right?
I don’t understand this - can someone add more explanation please?
not sure why this cannot be passed by memory
passing error codes and messages up the execution stack is currently working well
not sure how generic libraries with callbacks would use transient storage. Do you wont to store code in storage?
isn’t this what we currently have by the name of modifiers? How does this need transient storage?
using transient storage for calldata metadata sounds like a hack to me.
Seriously, let’s stop putting all our brain power towards saving 10k-100k per transaction and start scaling this thing properly! We need trees of rollups and especially we need things like “evaluate evm inside evm”, don’t we?
The gas accounting rules for storage are currently so complicated, it’s difficult for an experienced smart contract developer to estimate how much storage accesses in a transaction will cost in practice. With adoption, this EIP allows those accounting rules to be simplified.
As much of a joke as PUSH0 saving a O(1e11) gas on deploys alone, or simplifying 11.5% of all PUSH1 instructions, i.e. making all Ethereum nodes more efficient for the same effect. Uniswap V2 uses a transient storage slot just for unlocked. If you discount 2500 gas on every swap, mint, and burn on Uniswap V2, for wasted SLOADs, with V2 once accounting for 40%+ of the network traffic, you easily get billions-trillions of gas over the life of the contracts, and millions-billions of read ops on millions of hard drives (remember, this applies to hosted node services like Infura too).
Making nodes more efficient is good. They’re supposed to eventually run on mobile after all. Making the network horizontally scalable is also good. Maybe instead of making the EVM more efficient, the Ethereum nodes could JIT compile EVM bytecode, and still do gas accounting using the old bytecode, but that’s a level of indirection and complexity that pushes out client developers and does not pass on performance improvements to users.
E.g.: v3-core/contracts/UniswapV3PoolDeployer.sol at ed88be38ab2032d82bf10ac6f8d03aa631889d48 · Uniswap/v3-core · GitHub
This is done to avoid constructor arguments being part of the init code hash, allowing addresses to be computed on chain without constructing the preimage of the init code hash (i.e. the init code + constructor arguments). This is especially useful for proxies that have cheaper deploy costs. Yes this is an issue with the CREATE2 opcode, and the init code hash probably shouldn’t have been included since it provides no guarantees about the deployed code. That ship has sailed.
I think you are referring to single transaction approvals. This can be done with regular storage today. It cannot be done with memory, because the #transferFrom call will re-enter the token and have a new context in which the memory from the #approveAndCall is not accessible.
Passing errors up the stack is the weakest point, which is why I updated the EIP to have the same revert behavior as regular storage. It actually isn’t useful for passing errors up the stack with the new behavior. I will update the EIP.
Yes, it is effectively modifiers, where the inner logic is actually calling into an external untrusted contract, which can do some set of operations as long as some invariants are held. This is not possible without using storage to keep track of the state between calls. If your modifier is complicated, you need a lot of transient storage for otherwise cheap operations. See the example.
I don’t find this point that convincing either, but it was there in an earlier draft. That said, calldata metadata is already in use today (also with gas station network IIRC) and looks very complicated.
If you read the above example, you will see, this is effectively allowing us to ‘evaluate EVM inside of EVM’, instead of evaluate ‘custom Uniswap VM’. The same thing is potentially useful for fault proofs. This EIP is supported by developers from both Arbitrum and Optimism.
Moody and me have talked in the meantime. I’m still not convinced it is worth the complexity, but I understand some of the use-cases now.
Having spent some more thoughts on this, one thing that caught my eye is that this is a transaction-based feature instead of a call-based feature. Until now (please correct me if I’m wrong), the only way an “inner call” can be distinguished from an “outer call” inside the EVM is using tx.origin and maybe some aspects of selfdestruct. And both tx.origin and selfdestruct have been heavily criticized because of that, for example with regards to account abstraction.
Please excuse me if this has been discussed before, but one problem I can see (and mind me, it is a complicated feature) is that if we reset transient storage to zero only at the end of the transaction, we can no longer group two transactions together.
For example, if you have a reentrancy lock and people do not reset it (because they want to save the gas) and rely on it being reset at the end of the transaction, you will no longer be able to call this contract for the rest of the transaction at all.
We can solve this problem by resetting the transient storage of a contract whenever a call returns from the contract and the same contract is not in the current call stack. It would eliminate some other use cases, but it would feel much cleaner to me.
You could also check the code length of caller is greater than zero. You can’t do this for code running in a constructor
I’m not sure if the exact criticisms of those opcodes applies here. Could you elaborate or share a link?
This is interesting, but it might make transient storage harder to implement in the clients, since you need to keep track of the depth of the call stack by address. I don’t think it would introduce any additional risk, but the contract is already capable of resetting storage before returning from the calls (and also if the call reverts, all transient storage writes within it are reverted as well.) The 100 gas per TSTORE saved is probably not worth optimizing, and actually more explicitly represents the cost of clearing the slots. IMO this should be handled by the smart contract, not by the opcode, because it is trivial to handle within the smart contract.
If you use a transient mapping and don’t store the keys, the contract cannot reset it. Also this is just something people will forget about - “ah, it will be cleared at the end of the transaction anyway, I don’t need to do it”.
The current go-ethereum implementation curretnly keeps a full transaction log of all transient store operations - clearly an address per call would not be a big deal.
What I would be more interested in is which use-cases would not be possible any more in this modified version. Most cases I have seen call back into the caller, so those would be fine, as is the reentrancy lock obviously, but are there any where this does not happen?
True, but why are you storing values in the mapping unless you later need to iterate through the map? I can’t think of a use case that uses a mapping but doesn’t store a list of keys. EDIT: you can also just count the number of set keys, which is more efficient, and check that it’s 0 (require the caller to do something that unsets the keys)
Sidenote, an iterable map data type would be cool to have in solidity, rather than doing this separately.
One case it breaks is a call to a hypothetical ERC20#temporaryApprove that only lasts one transaction, and then another call to a separate contract that calls #transferFrom (which looks for a transient approval before a regular approval). In the context of 3074, this might be the cheaper version of approve and swap in a single transaction (for tokens that would support it)
If the SSTORE_RESET refund were greater, there would be no need for transient storage; you could just reset the storage and its cost would be reduced.
In addition, reverts are mispriced (and should refund), which prevents persistent storage from cheaply implementing transient storage.
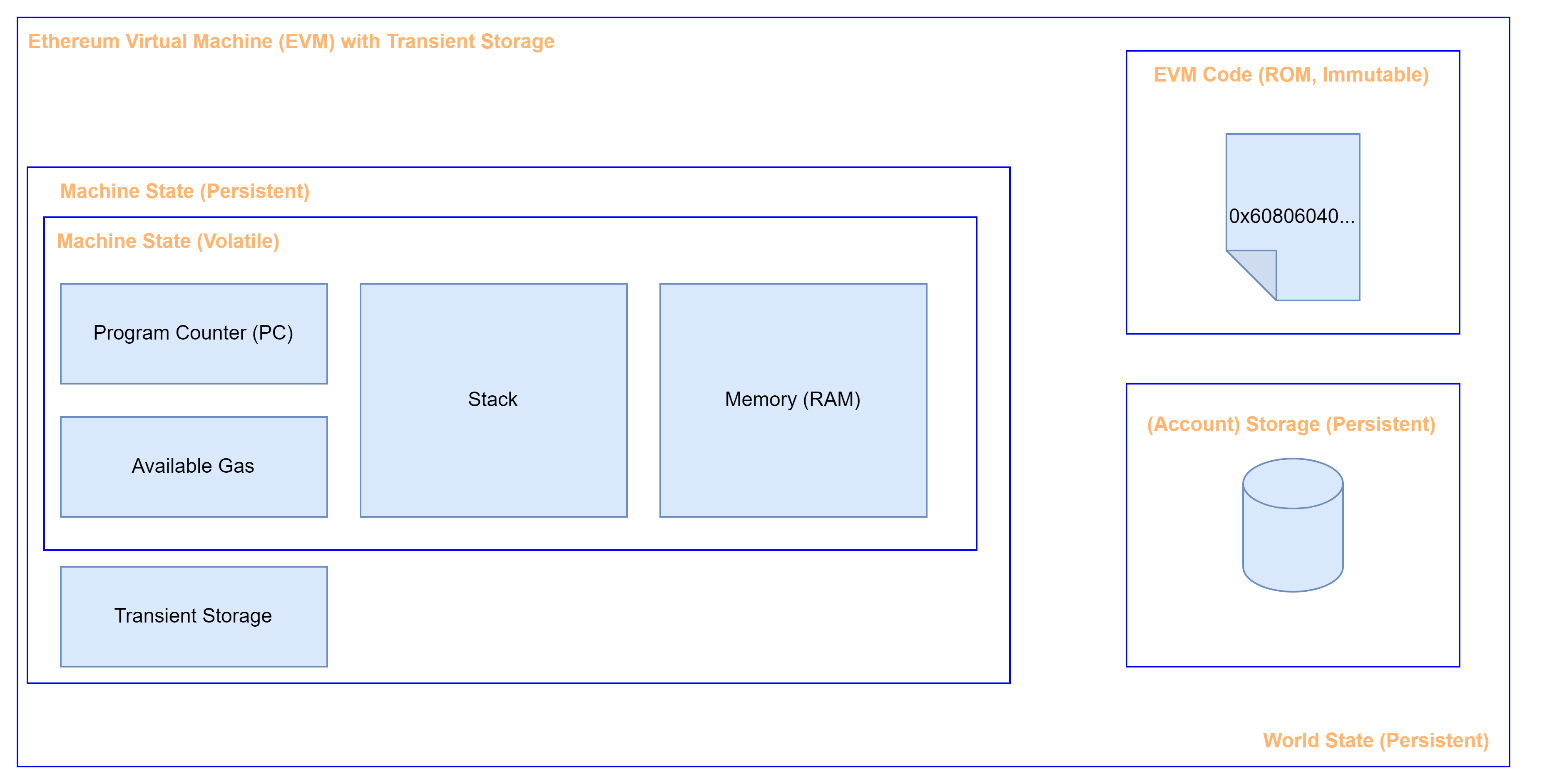
Hey everyone, I visualised the adjusted EVM with transient storage. Let me know if I missed something. It helped me a lot to explain the aim of EIP-1153. Maybe some of you can make use of it.
After reading EIP-1153 again: one strange thing about EIP-1153 is that it doesn’t get reverted on REVERT or OOG in its own frame. How a robust mutex is implemented if it may leave the mutex activated by an error? This can be abused by an attacker to censor a certain contract.
Let say a contract A calls another trusted contract T which uses a transient mutex.
The attacker can perform a transaction that calls a contract A but blocks the execution of a targeted child contract T by performing these steps:
Call to T with very little gas so that it raises OOG during the execution of T, leaving the mutex active.
Call A which will try to call T and that call will fail because of the mutex.
So this brings the stack overflow security problem back, but now using broken mutexes.
Interaction with reverts should be be mandatory.
At least transient memory writes should be reverted if the contract owning it reverts!
The original version of EIP-1153 did not interact with reverts. However, I edited the EIP so that it interacts with reverts in the exact same way that regular storage does. So it indeed works as you want it to, and the EIP-1153 text plus all existing implementations reflect that:
If a frame reverts, all writes to transient storage that took place between entry to the frame and the return are reverted, including those that took place in inner calls. This mimics the behavior of persistent storage.
Dropping a link here to the EIP-1153 implementation project board: EIP-1153 · GitHub